연관 규칙을 위한 새로운 확률 기반 흥미도 측정법
초록
본 논문은 거래 데이터의 무작위성을 모델링한 확률 프레임워크를 제시하고, 기존의 신뢰도와 lift 지표가 아이템 빈도에 편향되는 문제를 실증한다. 이를 바탕으로 하이퍼‑리프트와 하이퍼‑컨피던스라는 두 개의 새로운 흥미도 측정법을 도입하여, 무작위 노이즈를 효과적으로 걸러내고 실제 데이터에서 스푸리어스 규칙을 감소시키는 우수성을 입증한다.
상세 분석
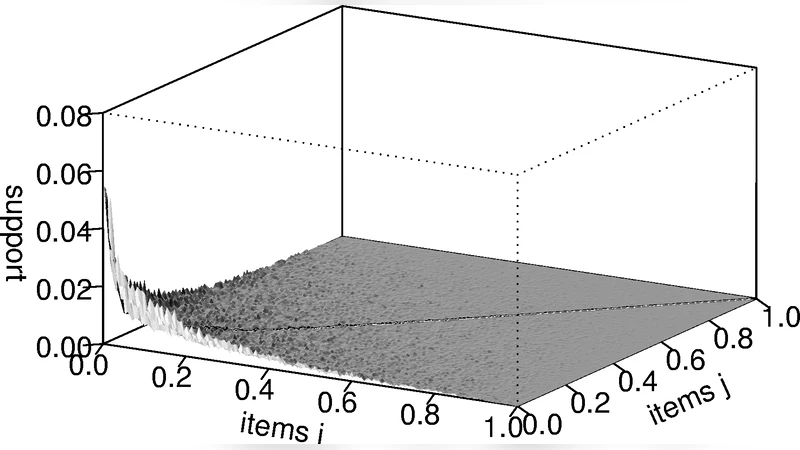
논문은 먼저 거래 데이터가 시간 구간 내에서 동질적인 포아송 과정(λ=θ·t)에 따라 발생하고, 각 아이템이 독립적인 베르누이 시행(p_i)으로 포함된다고 가정하는 간단한 확률 모델을 구축한다. 이 모델 하에서는 아이템별 등장 횟수 C_i가 포아송 분포(λ_i = p_i·θ·t)를 따르며, 아이템 쌍(l_i, l_j)의 동시 등장 횟수 C_{ij}는 고정된 주변 빈도(c_i, c_j)를 조건으로 할 때 초등적인 초등분포(하이퍼지오메트리)로 기술된다. 이러한 수학적 기반을 통해 ‘무구조(null) 데이터’를 시뮬레이션하고, 실제 식료품점 거래 데이터와 비교한다.
실험 결과, 신뢰도(confidence)는 오른쪽 아이템(l_j)의 전체 빈도가 높을수록 인위적으로 상승하는 경향을 보이며, 이는 규칙의 실제 연관성을 반영하기보다 빈도 편향에 의해 좌우됨을 확인한다. lift는 1을 기준으로 독립성을 판단하지만, 희귀 아이템이 한 번이라도 동시에 나타날 경우 극단적인 값을 생성해 노이즈를 충분히 억제하지 못한다. 특히, 최소 지원(support) 임계값을 낮게 잡으면 시뮬레이션 데이터에서도 lift > 2인 규칙이 다수 발생한다는 점에서 lift의 신뢰도가 제한적임을 보여준다.
이러한 한계를 극복하기 위해 저자는 하이퍼‑리프트와 하이퍼‑컨피던스를 제안한다. 하이퍼‑리프트는 관측된 동시 등장 횟수 r와 기대값 E
댓글 및 학술 토론
Loading comments...
의견 남기기