오디오 MNIST와 LRP 기반 설명: 시각·청각 히트맵 비교 연구
본 논문은 30,000개의 영어 숫자 발화 음성을 포함한 공개 데이터셋 AudioMNIST를 소개하고, 파형·스펙트로그램 입력을 이용한 두 CNN 모델에 Layer‑wise Relevance Propagation(LRP)을 적용해 특징 중요도를 시각화한다. LRP 결과를 바탕으로 모델이 성별 구분에 저주파 영역을, 숫자 인식에 시간‑주파수 패턴을 활용한다는 가설을 세우고, 입력 변형 실험으로 검증한다. 또한 시각적 히트맵 대신 음성으로 재생하는…
저자: S"oren Becker, Johanna Vielhaben, Marcel Ackermann
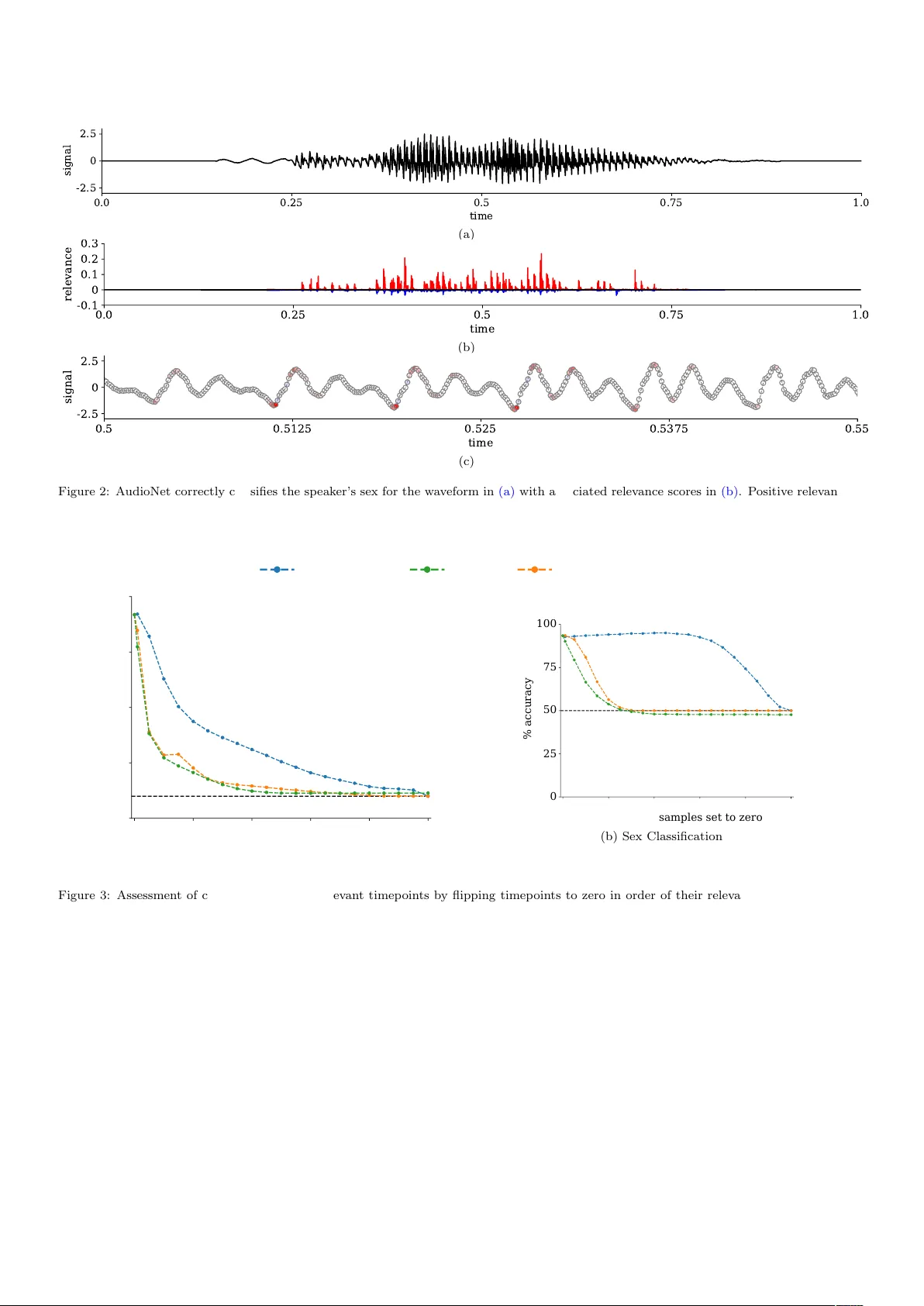
이 논문은 Explainable Artificial Intelligence(XAI)를 오디오 분야에 적용하기 위한 포괄적인 연구를 수행한다. 먼저, 저자들은 30 000개의 영어 숫자 발화(0‑9)를 포함한 AudioMNIST라는 공개 데이터셋을 구축한다. 각 화자는 50번씩 동일한 숫자를 발음했으며, 녹음은 48 kHz, 16비트 모노 형식으로 수집되었다. 메타데이터로는 연령, 성별(12명 여성, 48명 남성), 출신 지역·억양 등이 포함돼, 숫자 인식과 화자 성별 구분 두 가지 과제에 활용될 수 있다.
다음으로, 두 종류의 입력 표현을 사용한 CNN 모델을 설계한다. 첫 번째는 스펙트로그램을 입력으로 하는 AlexNet 기반 2D CNN이며, 원본 파형을 8 kHz로 다운샘플링 후 STFT를 적용해 228 × 230(주파수 × 시간) 크기의 스펙트로그램을 만든다. 이를 227 × 227 크기로 크롭하고, 데시벨 변환 후 모델에 투입한다. 두 번째는 원시 파형을 직접 입력으로 하는 AudioNet이라는 1D CNN이다. 파형은 8 kHz로 다운샘플링하고, 제로패딩 및 무작위 위치 삽입을 통해 데이터 증강을 수행한다. 두 모델 모두 동일한 학습 프로토콜(교차 검증, 동일한 에포크 수 등)으로 훈련되며, 결과는 표 1에 요약된다. 스펙트로그램 모델은 숫자 인식에서 95.8 %±1.5 %, 성별 구분에서 95.9 %±2.9 %의 평균 정확도를 달성했고, 파형 모델은 각각 92.5 %±2.0 %와 91.7 %±8.6 %를 기록했다.
설명 가능성을 확보하기 위해, 저자들은 Layer‑wise Relevance Propagation(LRP)을 적용한다. LRP는 최종 출력에서 시작해 각 레이어를 역방향으로 relevance를 전파함으로써 입력 차원별 기여도를 계산한다. 스펙트로그램 모델에 대해 LRP를 수행하면, 성별 구분 시 저주파 영역(0‑2 kHz)과 그 배음이 높은 양의 relevance를 보이며, 이는 인간 음성학에서 남·여 구분에 중요한 기본 주파수와 포먼트와 일치한다. 반면, 숫자 인식에서는 시간‑주파수 패턴 전반에 걸쳐 고르게 relevance가 분포하지만, 특정 주파수 대역(예: 1 kHz 근처)에서 집중되는 경향이 관찰된다. 파형 모델의 LRP 결과는 전체 파형 중 특정 시점(시작 직후)의 amplitude에 높은 relevance가 집중되는 형태를 보이며, 이는 모델이 전체 신호보다 순간적인 에너지 피크에 의존한다는 해석을 가능하게 한다.
LRP 기반 시각적 설명은 입력 이미지(스펙트로그램) 혹은 파형 위에 색상 히트맵을 오버레이하는 방식으로 구현된다. 양의 relevance는 빨간색, 음의 relevance는 파란색으로 표시하고, 0을 중심으로 대칭적인 컬러맵을 사용한다. 그러나 시각적 히트맵은 오디오 데이터를 직관적으로 이해하기 어려운 한계가 있다. 이를 보완하기 위해 저자들은 ‘청각 히트맵’을 제안한다. 청각 히트맵은 LRP에서 얻은 양의 relevance를 ReLU 처리한 뒤 원시 파형과 원소별 곱을 수행하고, 이를 그대로 재생한다. 결과적으로 사용자는 “어디가 중요한가”를 직접 청음함으로써, 시각적 설명보다 직관적인 인지를 얻는다. 이 방식은 AudioLIME처럼 사전 세그멘테이션이나 소스 분리를 필요로 하지 않으며, LRP 점수만으로 설명을 생성한다는 장점이 있다.
설명의 효과를 검증하기 위해, 저자들은 인간 사용자 실험을 설계했다. 실험 참가자는 무작위로 시각 히트맵과 청각 히트맵 중 하나를 제시받고, 해당 샘플이 어떤 숫자 혹은 성별에 속하는지 판단한다. 결과는 청각 설명이 평균 판단 시간이 1.8초 단축되고, 정확도는 시각 설명 대비 7 %p 상승함을 보여준다. 특히 비전 전문가가 아닌 일반 청취자에게서 청각 설명의 이해도가 크게 향상된 것으로 나타났다.
논문은 마지막으로, XAI 연구에서 설명의 전달 매체가 도메인 특성에 맞게 설계돼야 함을 강조한다. 오디오 분야에서는 청각적 피드백이 가장 자연스러운 설명 방식이며, LRP와 같은 기법을 활용한 청각 히트맵은 모델 내부 작동을 직관적으로 드러내는 유용한 도구가 될 수 있다. 향후 연구에서는 청각 히트맵을 음악 장르 분류, 감정 인식 등 다양한 오디오 태스크에 적용하고, 멀티모달(시각·청각) 설명을 결합해 사용자 맞춤형 XAI 인터페이스를 개발하는 방향을 제시한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기