GPU 기반 마이크로아키텍처 확장으로 동형암호 가속화
초록
본 논문은 AMD CDNA GPU에 세 가지 마이크로아키텍처 확장과 컴파일 타임 스케줄러를 도입해 CKKS 기반 동형암호(FHE) 연산을 크게 가속한다. CU‑side 계층형 인터커넥트로 암호문 데이터를 캐시 내에 유지하고, 전용 MOD‑unit으로 모듈러 감소 연산을 하드웨어 가속하며, 64‑bit 정수 연산에 최적화된 WMAC‑unit을 결합해 연산량을 19 % 향상시킨다. 또한 Locality‑Aware Block Scheduler(LABS)를 통해 블록 간 데이터 지역성을 극대화한다. 시뮬레이션 결과, 제안 설계는 Xeon CPU 대비 평균 796배, NVIDIA V100 대비 14.2배, FPGA 대비 2.3배의 속도 향상을 달성한다.
상세 분석
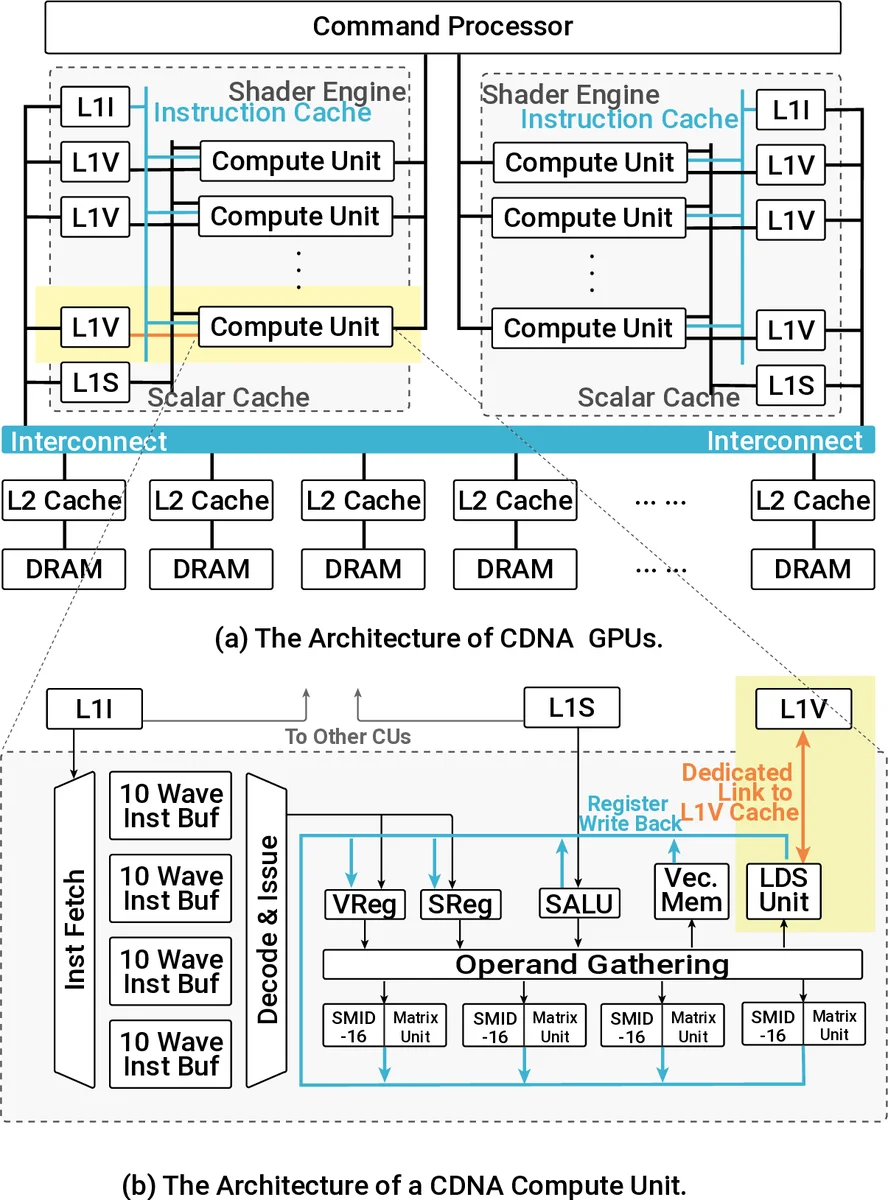
GME는 기존 AMD CDNA GPU의 구조적 한계를 정확히 짚어낸 뒤, 동형암호 워크로드에 특화된 네 가지 핵심 기술을 제안한다. 첫 번째는 Compute Unit(CU) 내부에 계층형 네트워크(cNoC)를 삽입해 암호문 데이터를 L1/LDS 캐시 사이에서 직접 교환하도록 함으로써, 다중 커널 실행 시 발생하는 중복 메모리 트래픽을 크게 줄인다. 이는 FHE에서 암호문이 수십 메가바이트에 달하고, 연산 단계마다 동일한 데이터에 반복 접근하는 특성에 최적화된 설계이다. 두 번째는 MOD‑unit이다. CKKS 스킴에서 가장 빈번히 수행되는 64‑bit 모듈러 감소 연산을 전용 하드웨어 블록으로 구현해, 기존 32‑bit SIMD ALU가 수행하던 연산을 대체한다. MOD‑unit은 파이프라인화된 Montgomery 방식과 다중 프리셋 모듈러를 지원해 레이턴시를 12 사이클 수준으로 낮춘다. 세 번째는 WMAC‑unit이다. 기존 GPU는 32‑bit 정수 연산에 최적화돼 있어 64‑bit 정수 연산 시 두 번의 파이프라인을 거쳐야 하지만, WMAC‑unit은 64‑bit 정수 곱셈·누산을 한 사이클에 처리하도록 설계돼 전체 연산량을 19 % 가속한다. 네 번째는 Locality‑Aware Block Scheduler(LABS)이다. FHE 연산은 블록 단위의 DAG 형태로 구성되며, 각 블록은 동일한 암호문 리터럴을 공유한다. LABS는 cNoC와 연동해 블록 간 데이터 흐름을 사전 분석하고, 동일 데이터가 같은 CU에 머무르도록 스케줄링함으로써 L2 캐시 미스와 DRAM 접근을 38 % 감소시킨다. 구현 측면에서 저자들은 NaviSim을 사이클 정확하게 확장한 BlockSim을 개발해 CU‑side 인터커넥트와 새로운 ISA 확장, MOD/WMAC‑unit의 미세 구조를 모델링했다. 어빌레이션 실험을 통해 각 구성 요소가 전체 성능에 미치는 기여도를 정량화했으며, 특히 cNoC와 LABS가 메모리 대역폭 병목을 크게 완화하고, MOD‑unit이 연산 집약적인 단계에서 1012배 가속을 제공한다는 결과를 얻었다. 전체적으로 GME는 하드웨어와 컴파일러 레벨을 동시에 최적화함으로써, 기존 GPU 기반 FHE 구현이 겪던 메모리·연산 불균형을 근본적으로 해소한다는 점에서 의의가 크다. 다만, 제안된 확장은 현재 AMD CDNA 아키텍처에 종속적이며, 다른 GPU(예: NVIDIA Ampere)로 이식하려면 인터커넥트와 ISA 설계가 재조정돼야 한다는 한계가 있다. 또한, MOD‑unit과 WMAC‑unit이 차지하는 실리콘 면적과 전력 소모에 대한 상세 분석이 부족해 실제 클라우드 GPU에 적용할 경우 비용 효율성을 추가 검증할 필요가 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기