플래시‑LLM: 비구조적 희소성으로 저비용·고효율 대형 생성 모델 추론 구현
초록
플래시‑LLM은 대형 생성 모델의 핵심 연산인 가늘어진 행렬곱을 텐서코어에서 효율적으로 수행하도록 설계된 소프트웨어 프레임워크이다. 비구조적 희소성을 ‘로드‑as‑Sparse, 컴퓨트‑as‑Dense’ 방식으로 활용해 메모리 대역폭을 크게 절감하고, 중복 연산을 허용함으로써 텐서코어의 높은 연산량을 유지한다. 새로운 타일 기반 압축 형식(Tiled‑CSL)과 2단계 메모리·연산 겹침 기법을 통해 스파스‑투‑덴스 변환을 최적화했으며, OPT‑30B/66B/175B 모델에서 토큰당 처리량을 기존 DeepSpeed·FasterTransformer 대비 최대 3.8배 가속하고 비용을 크게 낮추었다.
상세 분석
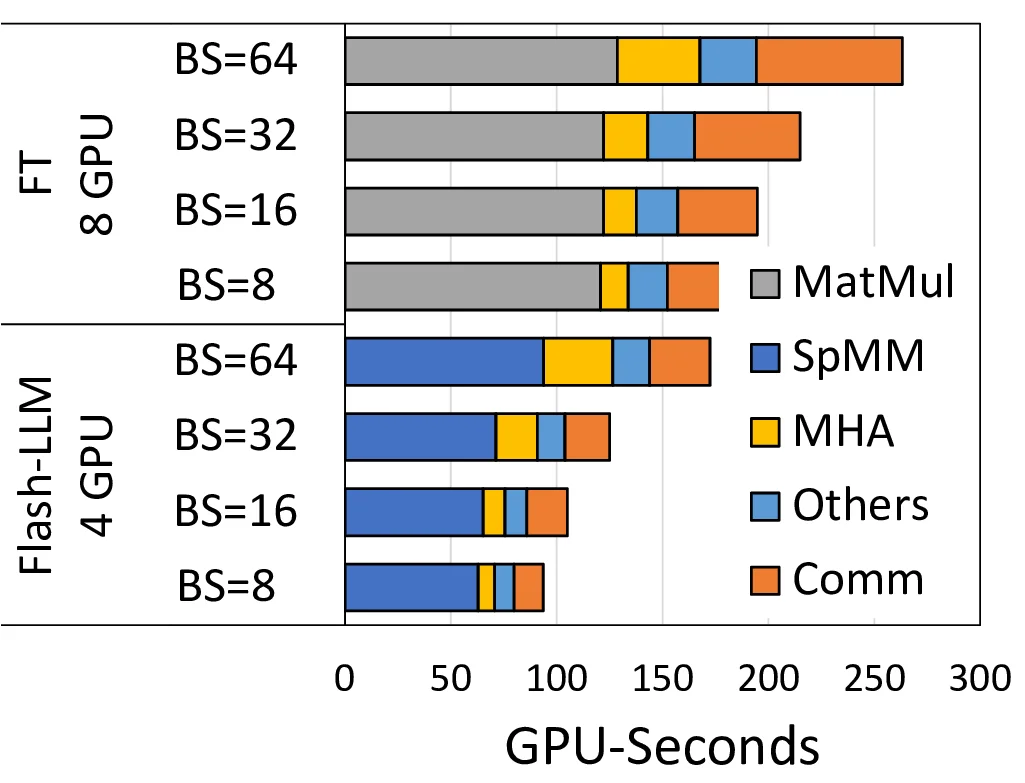
플래시‑LLM은 대형 언어 모델(LLM) 추론에서 가장 큰 병목이 되는 ‘가늘어진’ 행렬곱(M×K × K×N, N≪M,K) 을 텐서코어에 맞게 재구성한다. 기존 스파스 행렬곱 라이브러리들은 SIMT 코어 중심으로 설계돼 텐서코어의 10배 이상 높은 피크 성능을 활용하지 못한다. 저자는 “로드‑as‑Sparse, 컴퓨트‑as‑Dense”라는 핵심 아이디어를 제시한다. 즉, 가중치 행렬을 메모리에서 비압축 형태가 아닌 희소 포맷으로 로드해 전송 대역폭을 절감하고, 로드된 데이터를 텐서코어가 요구하는 16×16·16 형태의 블록으로 변환해 밀집 연산을 수행한다. 이 과정에서 희소 행렬의 0값을 건너뛰지 않고 중복 연산을 허용함으로써 텐서코어의 연산 파이프라인을 포화시킨다.
핵심 구현은 Tiled‑CSL(Tiled Compressed Sparse Layout) 포맷이다. 행렬을 고정 크기 타일(예: 64×64) 로 분할하고, 각 타일 내부의 비제로 원소를 CSR‑like 구조로 저장한다. 타일 단위로 데이터를 공유 메모리와 레지스터에 스트리밍하면서, 스파스‑투‑덴스 변환을 온‑칩에서 수행한다. 이때 두 단계 겹침(overlap) 전략을 적용한다. 1) 가중치 타일을 로드하면서 동시에 이전 타일의 변환 결과를 텐서코어에 전달하고, 2) 입력 피처 맵을 밀집 형태로 로드해 텐서코어 연산에 바로 투입한다. 이렇게 하면 메모리 대역폭과 연산이 거의 동시에 진행돼 파이프라인 스터미를 최소화한다.
또한, 사전 재배열(pre‑ordering) 단계에서 타일 내 원소를 공유 메모리 뱅크 충돌이 최소화되도록 정렬한다. 이는 공유 메모리 접근 병목을 크게 낮추어 전체 지연시간을 감소시킨다. 실험 결과, 스파스 커널 수준에서 기존 Sputnik 대비 평균 2.9배, SparTA 대비 1.5배 빠른 성능을 보였으며, OPT‑30B/66B/175B 모델 전체 파이프라인에서는 토큰당 GPU‑초당 처리량이 DeepSpeed 대비 최대 3.8배, FasterTransformer 대비 3.6배 향상되었다. 비용 측면에서도 메모리 사용량이 크게 감소해 동일한 하드웨어에서 더 많은 인스턴스를 운영할 수 있다.
이러한 설계는 비구조적 희소성을 유지하면서도 텐서코어의 고성능을 활용한다는 점에서 기존 구조적(2:4) 희소성 기반 가속기와 차별화된다. 다만, 중복 연산을 허용하는 접근법이므로 희소 비율이 낮을 경우(예: 50% 이하) 효율이 감소할 수 있다. 또한, 타일 크기와 포맷 선택이 하드웨어마다 최적화가 필요하므로 다른 GPU 아키텍처에 대한 이식성 검증이 추가로 요구된다.
댓글 및 학술 토론
Loading comments...
의견 남기기