첫 스파이크 시간으로 구현하는 빠르고 에너지 효율적인 뉴로모픽 딥러닝
본 논문은 누설이 있는 적분‑발화(LIF) 뉴런을 이용해 첫 스파이크 시간(TTFS) 코딩을 구현하고, 입력·출력 스파이크 시각만으로 정확한 그래디언트를 계산하는 학습 규칙을 유도한다. 도출된 규칙은 전통적인 역전파와 동등하게 작동하며, 이를 BrainScaleS‑2 가속 뉴로모픽 하드웨어에 적용해 48 µs·8.4 µJ의 매우 짧은 시간·에너지로 이미지 분류를 수행한다. 또한 다양한 회로 왜곡(노이즈, 정밀도 제한 등)에 대한 강인성을 실험적…
저자: Julian G"oltz, Laura Kriener, Andreas Baumbach
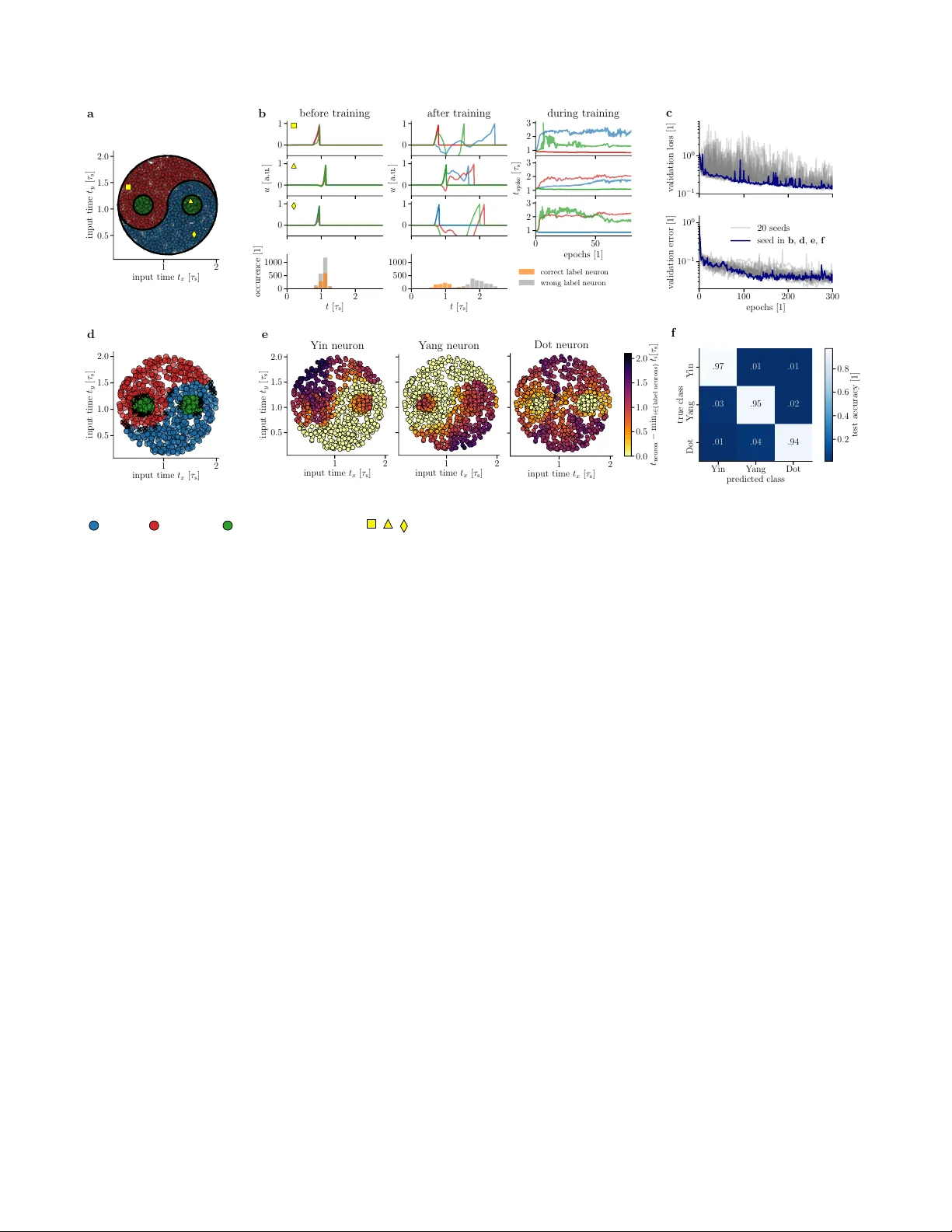
본 논문은 생물학적 신경계가 에너지와 반응 시간에 극도로 민감한 것처럼, 인공 뉴로모픽 시스템에서도 최소한의 스파이크와 빠른 응답을 목표로 하는 TTFS(시간‑대‑첫‑스파이크) 코딩 방식을 심도 있게 탐구한다. 먼저, 저자들은 누설 전도성(Leak)과 시냅스 시간 상수(τ_s)를 포함한 전형적인 LIF(Leaky Integrate‑and‑Fire) 뉴런 모델을 수식(1)으로 정의하고, 이 모델의 서브스레시홀드 동작을 정확히 해석한다. τ_m과 τ_s의 비율에 따라 PSP(Postsynaptic Potential)의 형태가 단일 지수, 차이 지수, 혹은 계단형으로 변하는 것을 도식화(Fig. 1a)하고, 특히 τ_m = τ_s와 τ_m = 2τ_s 경우에 대해 Lambert W 함수를 이용한 폐쇄형 첫 스파이크 시간 식(2, 3)을 도출한다. 이러한 식은 가중치와 입력 스파이크 시각에 대해 연속적이고 미분 가능하므로, 신경망의 학습을 위한 그래디언트 계산이 가능해진다.
다음으로, 저자들은 첫 스파이크 시각 T를 목표 함수에 직접 연결하는 방법을 제시한다. 손실 함수 L은 정답 라벨 스파이크와 다른 라벨 스파이크 간의 시간 차이를 로그‑소프트맥스 형태로 정량화한 (6)이며, 이는 절대 시각 이동에 불변하고 라벨이 스파이크하지 않을 경우 무한 시각을 가정하는 휴리스틱을 포함한다. 손실 함수에 대한 미분은 체인 룰을 통해 ∂L/∂w_ki = (∂L/∂t_k)(∂t_k/∂w_ki) 로 전개되며, 여기서 핵심 편미분식 ∂t_k/∂w_ki와 ∂t_k/∂t_i는 각각 (4)와 (5) 로 정확히 구해진다. 이 식들은 LIF 뉴런의 누설과 시냅스 동역학을 모두 고려하므로, 기존 비누설형 IF 모델에 비해 훨씬 현실적인 역전파가 가능하다.
학습 규칙(7)은 위 편미분식을 이용해 가중치를 업데이트하는 형태이며, 실제 구현에서는 각 뉴런의 스파이크 시각만을 기록하면 된다. 이는 복잡한 미세시간 시뮬레이션 없이도 하드웨어 상에서 직접 적용 가능함을 의미한다. 저자들은 이를 BrainScaleS‑2라는 가속 뉴로모픽 플랫폼에 적용하였다. BrainScaleS‑2는 아날로그 회로 기반으로 실제 물리적 시간보다 약 10⁴배 빠르게 동작하며, 전력 소모도 매우 낮다. 실험 결과, MNIST와 같은 이미지 분류 작업에서 소프트웨어 시뮬레이션과 거의 동일한 정확도를 달성하면서도 48 µs, 8.4 µJ per classification이라는 뛰어난 시간·에너지 효율을 보였다.
또한, 뉴로모픽 회로는 제조 공정에 따른 파라미터 변동, 고정 패턴 노이즈, 제한된 정밀도 등 다양한 왜곡에 취약하다. 저자들은 이러한 왜곡을 시뮬레이션으로 모델링하고, 학습 과정에 실제 회로에서 측정된 파라미터를 반영함으로써 자동 보정 메커니즘을 구현했다. 실험에서는 고정 패턴 노이즈가 10 % 수준까지 증가해도 정확도 저하가 미미했으며, 정밀도 제한(8‑bit 가중치)에서도 학습이 안정적으로 수렴함을 확인했다. 이러한 강인성은 제안된 학습 프레임워크가 다양한 뉴로모픽 하드웨어(예: Loihi, TrueNorth)에도 일반화될 수 있음을 시사한다.
결론적으로, 이 논문은 (1) LIF 뉴런에 대한 정확한 첫 스파이크 시간 해석을 제공하고, (2) 그 해석을 기반으로 완전 미분 가능한 역전파 알고리즘을 설계했으며, (3) 이를 실제 가속 뉴로모픽 하드웨어에 적용해 빠르고 에너지 효율적인 딥러닝을 실현했다는 점에서 큰 의미를 가진다. 특히, 누설 전도와 시냅스 동역학을 동시에 고려한 학습 규칙은 기존 스파이크‑카운트 기반 방법보다 정보 전달 효율이 높으며, 하드웨어 비선형성에 대한 자동 보정 메커니즘은 향후 대규모 뉴로모픽 시스템 구축에 필수적인 설계 원칙이 될 것이다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기