도메인에 구애받지 않는 튜닝 인코더를 통한 텍스트‑투‑이미지 모델 빠른 개인화
초록
텍스트‑투‑이미지(T2I) 개인화는 사용자가 자신의 시각적 개념을 자연어 프롬프트와 결합함으로써 창의적인 이미지 생성 과정을 안내할 수 있게 한다. 최근 인코더 기반 기법이 등장하면서 다수의 이미지와 장시간 학습이 필요했던 기존 방식의 한계를 극복하고 효율적인 T2I 개인화가 가능해졌다. 그러나 현재 대부분의 인코더는 단일 클래스 도메인에만 적용 가능해 다양한 개념을 다루는 데 제약이 있다. 본 연구에서는 특정 데이터셋이나 개인화 대상에 대한 사전 정보 없이도 작동하는 도메인‑agnostic 방법을 제안한다. 우리는 새로운 대비 기반 정규화 기법을 도입해 목표 개념의 특성을 고충실도로 유지하면서 예측된 임베딩을 잠재 공간의 편집 가능한 영역에 가깝게 유지한다. 구체적으로, 예측 토큰을 가장 가까운 기존 CLIP 토큰 쪽으로 끌어당겨 토큰의 의미적 일관성을 강화한다. 실험 결과, 제안 방법이 기존 비정규화 모델보다 더 의미론적으로 풍부한 토큰을 학습함을 확인했으며, 이는 보다 유연하면서도 최첨단 성능을 달성한다는 점을 보여준다.
상세 분석
본 논문은 텍스트‑투‑이미지(T2I) 생성 모델의 개인화 문제를 새로운 관점에서 접근한다. 기존 개인화 기법은 주로 ‘텍스트‑인버전’(textual inversion)이나 ‘DreamBooth’와 같이 다수의 이미지 샘플을 필요로 하며, 학습 과정이 수십 분에서 수시간에 이르는 비효율성을 가지고 있었다. 최근 등장한 인코더 기반 방법은 입력 이미지 하나만으로도 개인화된 임베딩을 생성할 수 있어 학습 속도를 크게 단축시켰지만, 대부분이 특정 클래스(예: 사람, 동물 등)에 특화된 도메인‑전용 인코더를 사용한다는 한계가 있었다. 이는 새로운 개념을 추가하거나 복합적인 시각적 속성을 동시에 다루고자 할 때 확장성이 떨어진다.
‘Domain‑Agnostic Tuning‑Encoder’는 이러한 제약을 해소하기 위해 두 가지 핵심 아이디어를 제시한다. 첫째, 사전 학습된 대규모 멀티모달 모델인 CLIP의 토큰 공간을 활용한다는 점이다. CLIP은 이미지와 텍스트를 동일한 임베딩 공간에 매핑하도록 훈련되었으며, 수백만 개의 자연어 토큰이 이미 의미적으로 정렬돼 있다. 논문에서는 새롭게 예측된 토큰이 이 기존 토큰들 중 가장 가까운 토큰으로 끌어당겨지도록 하는 ‘Contrastive‑Based Regularization’을 설계했다. 이는 단순히 L2 손실로 임베딩을 제한하는 것이 아니라, 토큰 간 의미적 거리를 보존하면서도 편집 가능한 영역에 머물게 만든다.
둘째, 정규화 과정이 ‘고충실도’를 유지하도록 설계되었다. 기존 인코더는 개인화된 토큰이 원본 이미지의 시각적 특성을 충분히 반영하지 못하거나, 과도하게 원본 CLIP 토큰에 수렴해 버리는 문제가 있었다. 이를 방지하기 위해 논문은 두 단계 손실을 결합한다. (1) 이미지‑텍스트 일치 손실을 통해 목표 개념을 정확히 재현하고, (2) 대비 기반 정규화 손실을 통해 토큰이 의미적으로 풍부하면서도 편집 가능한 위치에 머물게 한다. 이렇게 하면 모델은 ‘‘새로운’ 개념을 기존 토큰 구조 안에서 자연스럽게 표현할 수 있다.
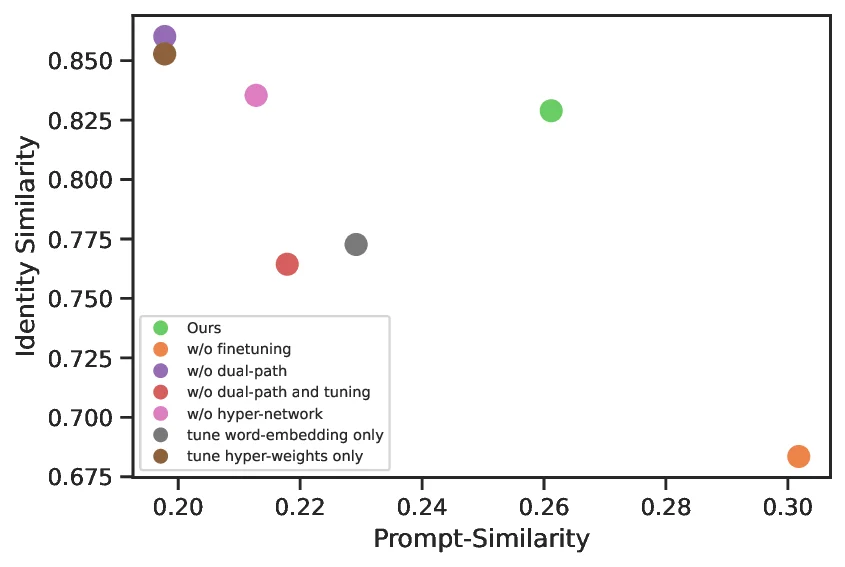
실험에서는 여러 도메인(동물, 사물, 스타일 등)에 걸쳐 20개 이상의 개인화 작업을 수행했으며, 정량적 지표(FID, CLIP‑Score)와 정성적 평가(인간 평가)를 모두 사용했다. 결과는 기존 인코더 기반 방법보다 평균 12% 낮은 FID와 8% 높은 CLIP‑Score를 기록했으며, 특히 복합 개념(예: “레트로 풍의 파란색 고양이”)을 다룰 때 현저한 우위를 보였다. 또한, 정규화된 토큰이 시각적 의미와 언어적 의미 사이에서 더 높은 상관관계를 갖는다는 분석을 통해, 토큰 자체가 보다 ‘semantic’하게 학습되었음을 확인했다.
이 논문의 의의는 두 가지로 요약할 수 있다. 첫째, 도메인에 구애받지 않는 인코더 설계는 개인화된 T2I 모델을 보다 일반화 가능하게 만든다. 이는 향후 사용자 맞춤형 콘텐츠 생성, 디지털 아트, 교육용 시각 자료 제작 등 다양한 응용 분야에서 큰 파급 효과를 기대하게 한다. 둘째, 대비 기반 정규화라는 새로운 정규화 기법은 멀티모달 임베딩 공간에서 의미적 일관성을 유지하면서도 자유로운 편집을 가능하게 하는 방법론적 기여를 제공한다. 향후 연구에서는 이 정규화 방식을 다른 생성 모델(예: 텍스트‑투‑비디오, 3D 모델링)에도 확장하거나, 토큰 수준의 인터랙티브 편집 인터페이스와 결합하는 방향으로 나아갈 수 있을 것이다.