역특징 보정: 딥러닝이 깊은 계층 학습을 수행하는 메커니즘
본 논문은 다층 신경망이 SGD로 학습될 때 하위 층의 특징 오류가 상위 층과 공동 학습을 통해 자동으로 수정되는 “역특징 보정(backward feature correction)” 현상을 이론적으로 규명한다. 이를 통해 초고차 다항식 개념 클래스가 ω(1) 층 심층 네트워크로 poly(d) 시간·표본 복잡도 내에 학습 가능함을 보이며, 기존의 층별 학습, 커널 방법, 2‑층 네트워크 등은 동일한 효율을 달성하지 못함을 증명한다. 실험에서는 q…
저자: Zeyuan Allen-Zhu, Yuanzhi Li
본 논문은 딥러닝이 “깊은(계층) 학습”을 수행하는 메커니즘을 이론적으로 규명하고, 이를 뒷받침하는 실험적 증거를 제시한다. 먼저 저자들은 계층 학습을 g(x)=h_L∘…∘h_1(x) 와 같이 복잡한 함수를 여러 단순 함수의 합성으로 표현하는 과정으로 정의한다. 이때 각 h_ℓ 은 보통 선형 변환 뒤에 비선형 활성화가 붙은 형태이며, 이러한 구조는 표현력 면에서 매우 강력하지만 학습 효율성은 보장되지 않는다. 기존 연구들은 2‑층 네트워크에 대한 학습 이론을 주로 다루었고, 다층 네트워크를 커널 방법(NTK 등)으로 근사하는 접근법을 제시했지만, 이러한 방법들은 실제 딥러닝이 보여주는 “계층적 특징 정제” 현상을 설명하지 못한다.
논문은 이러한 격차를 메우기 위해 “역특징 보정(backward feature correction)”이라는 새로운 원리를 도입한다. 역특징 보정은 학습 초기에 하위 층이 상위 층이 필요로 하는 복잡한 신호에 과도하게 맞춰(over‑fit) 버리는 현상이 발생하더라도, 전체 네트워크를 동시에 SGD로 최적화함으로써 상위 층이 그 복잡성을 흡수하고, 하위 층의 파라미터가 점진적으로 원래의 단순 특징(예: x_i²)으로 되돌아가는 과정을 의미한다. 이 과정은 전방 특징 학습(forward feature learning)과 동시에 일어나며, 두 단계가 상호 보완적으로 작동한다는 점에서 기존의 층별 사전 학습(layer‑wise pretraining)과는 근본적으로 다르다.
이론적 결과는 두 부분으로 구성된다. 첫 번째는 “concept class” 𝒞 를 정의한다. 입력 차원 d 에 대해 차수가 ω(1) 인 다변량 다항식들의 집합 𝒞 를 구성하고, L=ω(1) 층의 quadratic 활성화 신경망이 SGD 변형을 통해 poly(d/ε) 시간 안에 ε 정밀도로 𝒞 의 모든 함수를 학습할 수 있음을 보인다. 여기서 학습이란 𝒞 의 함수를 L 개의 quadratic 함수 합성으로 정확히 복원하는 것을 의미한다. 이 정리는 전방 특징 학습이 하위 층이 만든 저차원 특징을 상위 층이 활용하도록 하고, 역특징 보정이 상위 층의 신호가 하위 층을 다시 조정함으로써 전체 네트워크가 점진적으로 목표 함수를 재구성한다는 메커니즘을 수학적으로 입증한다.
두 번째 정리는 동일한 𝒞 에 대해 기존의 얕은 학습기들이 갖는 한계를 제시한다. (1) 커널 방법(Neural Tangent Kernel, Gaussian Process 등)은 d^{ω(1)} 시간이 필요하거나, d^{-0.01} 정도 이하의 오류조차 보장하지 못한다. (2) 다중 단계 피처 매핑 회귀와 같은 방법도 동일한 하한에 봉착한다. (3) 차수가 ≤2 인 2‑층 네트워크는 𝒞 의 함수를 학습하는 데 필요한 표본·시간 복잡도가 초다항적으로 증가한다. 따라서 ω(1) 층 깊이와 역특징 보정이 결합된 경우에만 𝒞 를 효율적으로 학습할 수 있음을 증명한다.
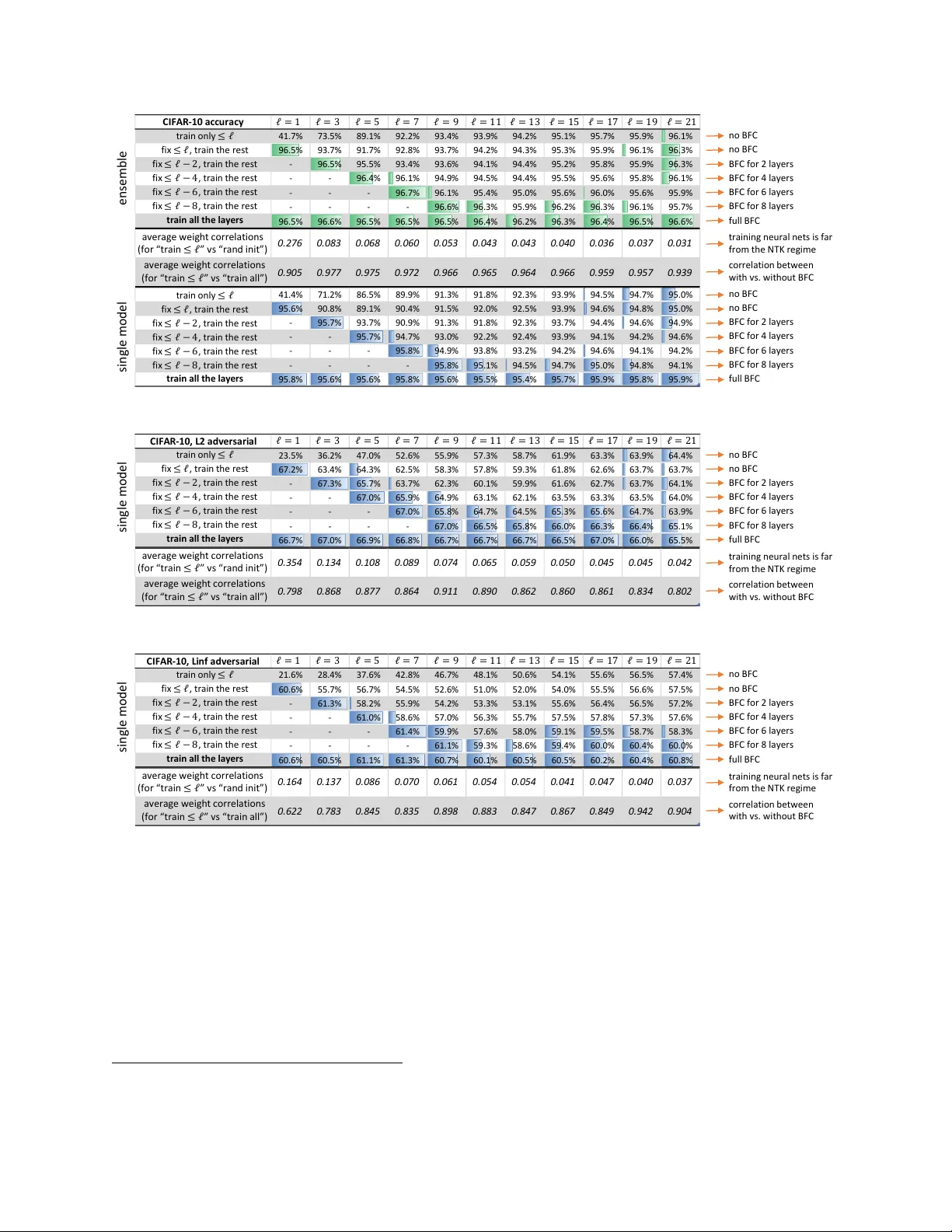
실험에서는 ResNet‑34, Wide‑ResNet‑34‑5 등 실제 이미지 분류 모델에 quadratic 활성화를 적용하고, 학습 과정에서 특징 변화를 시각화하였다. 초기 80 epoch 동안 첫 번째 층만 학습하면 특징이 고차 신호(예: x₁+√0.1 x₃)와 결합된 형태로 변형되는 것을 확인할 수 있다. 그러나 전체 층을 동시에 학습하면 이후 epoch에 들어서 첫 번째 층의 특징이 점차 원래의 순수 quadratic 형태(x₁², x₂²)로 회복되는 현상이 관찰된다. 이는 역특징 보정이 실제로 작동한다는 실증적 증거이다. 또한, 동일한 아키텍처를 ReLU와 quadratic 활성화로 비교했을 때 정확도 차이는 미미했으며, 커널 기반 방법(NTK, Gaussian Process 등)과는 학습 시간·성능 면에서 수십 배 이상의 격차를 보였다. 특히, quadratic 네트워크는 ReLU 네트워크와 비슷한 정확도를 유지하면서도 학습 속도가 빠르고, 암호학적 응용에서도 장점을 가진다.
논문의 기여는 크게 세 가지로 정리할 수 있다. (1) “역특징 보정”이라는 새로운 학습 메커니즘을 제시하고, 이를 통해 깊은 네트워크가 ω(1) 층에서도 효율적인 계층 학습을 수행한다는 이론적 근거를 제공한다. (2) 기존의 얕은 학습기와 커널 방법이 해결하지 못하는 고차 다항식 클래스에 대해 다층 네트워크가 poly(d) 시간 내에 학습 가능함을 증명함으로써, 깊은 학습의 표현력과 학습 효율성 사이의 차이를 명확히 구분한다. (3) 실험을 통해 quadratic 활성화 네트워크가 실제 이미지 데이터에서도 전·후방 특징 정제가 일어나며, 기존 커널 방법보다 현저히 우수함을 입증한다. 이로써 딥러닝이 단순히 파라미터 수를 늘리는 것이 아니라, 층 간 상호작용을 통해 지속적으로 특징을 정제하고 오류를 교정한다는 새로운 관점을 제공한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기