NTT‑PIM: 행‑중심 설계와 매핑으로 구현하는 고효율 수론 변환 가속기
초록
DRAM 기반 PIM 환경에서 셀 배열을 그대로 사용하면서도 행‑중심 구조와 다중 버퍼 파이프라인을 도입해 NTT 연산을 인‑플레이스 방식으로 처리한다. 기존 PIM‑NTT 가속기 대비 1.7∼17배 빠른 실행 시간을 달성했으며, 면적·전력 오버헤드는 거의 발생하지 않는다.
상세 분석
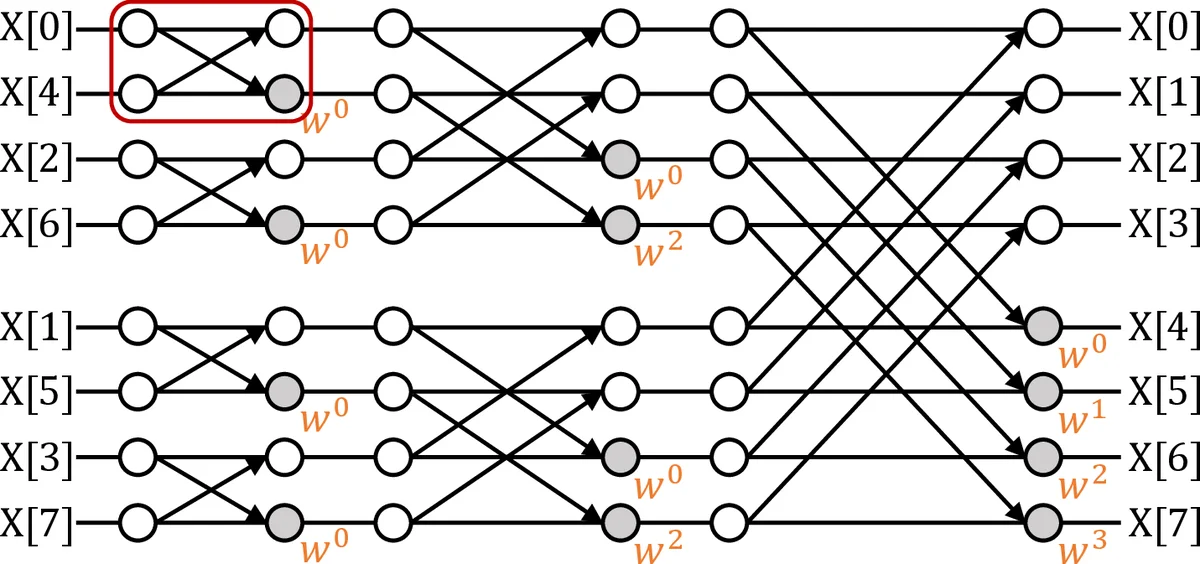
본 논문은 DRAM‑PIM(Processing‑in‑Memory) 시스템이 갖는 “셀 배열 비수정”, “극소형 연산 유닛”이라는 두 가지 핵심 제약을 그대로 유지하면서도, 복잡한 수론 변환(NTT, Number‑Theoretic Transform) 연산을 효율적으로 수행할 수 있는 새로운 아키텍처 NTT‑PIM을 제시한다. 기존 PIM 기반 가속기들은 주로 간단한 매트릭스‑벡터 연산이나 컨볼루션에 국한되었으며, NTT와 같이 모듈러 곱셈·덧셈, 비트‑리버스 순열, 복합적인 ‘버터플라이’ 연산을 동시에 지원하기는 어려웠다. NTT‑PIM은 이러한 난관을 “행‑중심 매핑(row‑centric mapping)”과 “다중 버퍼 파이프라인(multi‑buffer pipelining)”이라는 두 축으로 해결한다.
-
행‑중심 매핑
NTT는 Cooley‑Tukey와 유사한 단계별 버터플라이 연산을 수행한다. 논문은 각 단계의 연산을 DRAM의 행(row) 단위에 매핑함으로써, 동일 행 내에서 필요한 모듈러 곱셈·덧셈을 병렬적으로 수행하도록 설계했다. 행마다 최소한의 연산 로직(모듈러 곱셈기와 어드더)만을 배치하고, 데이터는 같은 행 안에서 인‑플레이스(in‑place)로 업데이트된다. 이 접근법은 행 간 데이터 이동을 최소화하고, DRAM 내부의 대역폭을 최대한 활용한다. 또한, 행 주소와 단계 인덱스를 비트‑리버스 방식으로 매핑함으로써 주소 계산 오버헤드를 거의 없앤다. -
다중 버퍼 파이프라인
기존 PIM 설계는 하나의 버퍼(예: 행 버퍼)만을 사용해 연산과 메모리 접근을 순차적으로 수행했다. NTT‑PIM은 각 행에 두 개 이상의 임시 버퍼를 두어, 한 버퍼에서 연산이 진행되는 동안 다른 버퍼는 다음 단계의 데이터를 미리 로드한다. 이렇게 하면 연산 지연(latency)과 메모리 접근 지연이 겹치지 않아 파이프라인 효율이 크게 향상된다. 특히, NTT의 로그₂N 단계마다 발생하는 데이터 의존성을 버퍼 스위칭으로 해결함으로써, 전체 실행 시간을 단계별로 거의 일정하게 만든다. -
인‑플레이스 업데이트와 모듈러 연산 최적화
NTT는 중간 결과를 재사용해야 하는 특성이 있다. 논문은 DRAM 셀 자체를 임시 저장소로 활용해, 연산 결과를 바로 같은 셀에 기록하는 인‑플레이스 방식을 채택했다. 이를 위해 모듈러 곱셈기의 설계에서 캐리 전파를 최소화하고, 사전 계산된 위즈(roots of unity) 테이블을 행 별로 분산 저장한다. 결과적으로 추가적인 메모리 복사 비용이 사라지고, 전력 소모도 크게 감소한다. -
하드웨어 비용과 전력
NTT‑PIM은 기존 DRAM 칩에 최소한의 주변 회로(연산 로직, 버퍼, 제어 FSM)만을 추가한다. 논문은 면적 오버헤드가 전체 DRAM 면적의 0.3 % 이하이며, 전력 증가율도 2 % 미만임을 시뮬레이션 결과로 제시한다. 이는 “셀 배열 비수정”이라는 설계 목표를 완벽히 지키면서도, 고성능 NTT 가속을 가능하게 만든 핵심 포인트다. -
성능 평가
평가에서는 폴리노미얼 곱셈(특히 격자 기반 암호인 Ring‑LWE, NTRU 등에 사용되는 NTT) 워크로드를 대상으로, 기존 PIM‑NTT 가속기와 GPU/FPGA 구현을 비교하였다. 평균 1.7∼17배의 실행 시간 단축을 기록했으며, 특히 데이터 크기가 DRAM 행 크기와 정렬될 때 최대 17배 향상을 보였다. 메모리 대역폭 활용률은 85 % 이상으로, 기존 설계가 보였던 대역폭 병목을 효과적으로 해소했다.
핵심 인사이트
- 행‑중심 매핑은 DRAM 내부 구조와 자연스럽게 맞물려, 데이터 이동을 최소화하고 병렬성을 극대화한다.
- 다중 버퍼 파이프라인은 연산‑메모리 지연을 겹치게 함으로써, 단계별 동기화 비용을 크게 낮춘다.
- 인‑플레이스 업데이트와 사전 계산된 위즈 테이블을 결합하면, 모듈러 연산에 필요한 임시 저장소를 별도로 두지 않아도 된다.
- 최소한의 회로 추가만으로도 복잡한 NTT를 가속할 수 있다는 점은, 향후 다른 수학적 변환(FFT, NTT‑variant 등)에도 동일한 설계 원리를 적용할 수 있음을 시사한다.
댓글 및 학술 토론
Loading comments...
의견 남기기