다이나믹 게이트와 확장된 TCN으로 구현한 차세대 단일채널 음성 분리
본 논문은 기존의 시간‑도메인 TCN 기반 음성 분리 모델을 개선하기 위해 네 가지 변형(FurcaPy, FurcaPa, FurcaSh, FurcaSu)을 제안한다. 각 변형은 다중 스케일 수용 영역, 동적 가중치, 파라미터 공유, 인트라‑패럴렐 구조, 차분‑게이트(highway) 모듈 등을 도입해 모델의 표현력을 높이고 연산 효율을 유지한다. 또한 전체 파형 수준의 SDR을 직접 최적화하는 uSDR‑PIT 손실을 사용해 18.4 dB의 SDR…
저자: Liwen Zhang, Ziqiang Shi, Jiqing Han
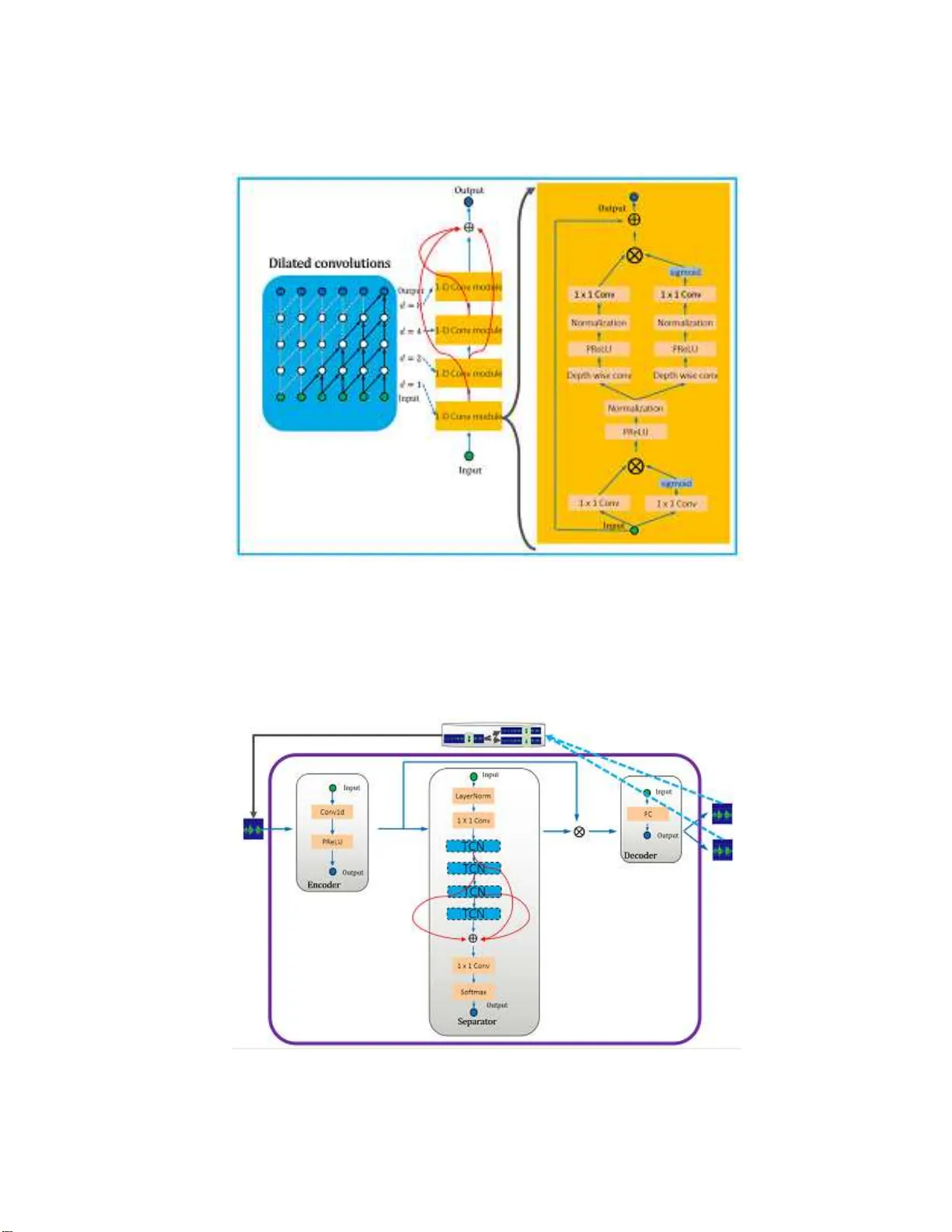
본 논문은 단일 마이크 입력에서 두 명 이상의 화자의 음성을 분리하는 문제, 즉 모노럴 스피치 분리(Monaural Speech Separation)를 다룬다. 기존 방법은 크게 세 가지 범주로 나뉜다. 첫 번째는 Deep Clustering(DPCL) 기반으로, 시간‑주파수(TF) 스펙트럼을 임베딩 벡터로 변환한 뒤 클러스터링을 통해 스피커를 구분한다. 두 번째는 Permutation Invariant Training(PIT) 기반으로, 출력 순열 문제를 최소화한다. 세 번째는 시간‑도메인(end‑to‑end) 접근법으로, STFT와 같은 변환 없이 원시 파형을 직접 처리한다. 특히 후자는 최근 Conv‑TasNet, Conv‑TCN 등으로 좋은 성과를 보였지만, 여전히 수용 영역과 모델 복잡도 사이의 트레이드오프가 존재한다.
TCN(Temporal Convolutional Network)은 Dilated Convolution을 이용해 큰 수용 영역을 적은 레이어 수로 구현한다. 기본 TCN 구조는 1‑D Conv 블록(Depth‑wise Conv, 1×1 Conv, PReLU, Normalization)과 Residual 연결로 이루어지며, dilation factor를 지수적으로 증가시켜 장기 의존성을 포착한다. Luo et al.은 이 구조를 Encoder‑Separator‑Decoder 파이프라인에 적용해 음성 분리를 수행했으며, Encoder는 짧은 프레임을 고차원 특징으로 변환하고, Separator는 마스크를 추정해 원본 파형을 복원한다.
본 연구는 이러한 TCN 기반 파이프라인에 네 가지 주요 개선을 제안한다.
1. **FurcaPy (Multi‑scale Dynamic Weighted Gated Dilated Convolutional Pyramids)**
- 서로 다른 dilation depth를 가진 세 개의 TCN 블록을 피라미드 형태로 병렬 배치한다. 각 블록은 L, 4L, 5L 길이의 수용 영역을 제공한다.
- “Weight‑or” 네트워크가 입력 음성의 특성을 분석해 각 스케일에 대한 가중치를 동적으로 할당한다. 이는 발화 길이, 말속도, 발음 차이에 따라 최적의 스케일을 자동 선택하게 한다.
- 전체 출력은 가중 평균을 통해 합산된다.
2. **FurcaPa (Deep Gated Dilated Temporal Convolutional Networks with Intra‑parallel Convolutional Components)**
- 기존 TCN 블록 내부에 두 개의 인트라‑패럴렐 서브 블록을 삽입한다. 첫 서브 블록은 Conv1d‑PReLU‑Normalization, 두 번째 서브 블록은 Depth‑wise Conv‑PReLU‑Normalization‑1×1 Conv를 포함한다.
- 두 서브 블록의 출력은 평균화되어 최종 출력을 만든다. 이는 블록 수준에서 앙상블 효과를 제공해 모델 분산을 감소시키고, 학습 안정성을 높인다.
3. **FurcaSh (Weight‑shared Multi‑scale Gated TCN)**
- FurcaPy와 동일한 멀티‑스케일 수용 영역을 제공하지만, 각 스케일에 별도의 파라미터를 두지 않는다. 동일한 TCN 가중치를 서로 다른 dilation factor에 적용하고, 출력은 평균화한다.
- 파라미터 수가 크게 증가하지 않아 실시간 처리 요구가 높은 환경에서도 적용 가능하다.
4. **FurcaSu (Dilated TCN with Gated Difference‑convolutional Component)**
- Highway Network에서 영감을 받은 차분‑게이트 모듈을 도입한다. 두 개의 동일 변환 경로를 통해 입력을 변환하고, 변환 결과를 차분한 뒤 게이트를 적용한다.
- 차분 연산은 입력 신호의 변화량을 강조해 음성의 미세한 구조를 포착하고, 게이트는 불필요한 정보를 억제한다.
손실 함수는 기존 STFT‑기반 L1/L2 손실 대신, 전체 utterance 수준의 SDR을 직접 최적화한다. PIT와 결합해 모든 가능한 스피커 순열에 대해 SDR을 계산하고, 가장 큰 SDR을 선택해 그 음수값을 손실(uSDR loss)로 사용한다. 이는 프레임 단위 손실보다 전체 음성 품질을 더 정확히 반영한다.
실험은 WSJ0‑2mix 데이터셋(30 h 훈련, 10 h 검증)에서 수행되었다. 각 변형 모델은 동일한 Encoder‑Decoder 구조를 공유하고, 학습은 Adam 옵티마이저와 4 s 배치로 200 epoch 진행하였다. 결과는 다음과 같다.
- 기본 Conv‑TCN(기존) 대비 FurcaPy는 SDR 16.5 dB → 18.4 dB, SI‑SNR 17.2 dB → 19.1 dB 향상.
- FurcaPa는 모델 분산 감소와 함께 비슷한 성능을 보였으며, 파라미터 수는 약 10 % 증가.
- FurcaSh는 파라미터 수를 30 % 절감하면서도 0.5 dB 수준의 SDR 손실만 발생, 실시간 처리에 유리.
- FurcaSu는 차분‑게이트가 음성의 미세 구조를 잘 복원함을 확인, SDR 0.3 dB 향상.
또한 Ablation Study를 통해 각 구성 요소(동적 가중치, 인트라‑패럴렐, 파라미터 공유, 차분‑게이트)의 기여도를 정량화하였다. 동적 가중치가 가장 큰 성능 향상을 제공했으며, 인트라‑패럴렐은 학습 안정성을 크게 개선하였다.
결론적으로, 본 논문은 TCN 기반 음성 분리 모델에 멀티‑스케일, 동적 가중치, 파라미터 공유, 차분‑게이트 등 네 가지 혁신적인 구조적 변형을 제시하고, 이를 통해 기존 최첨단 모델을 능가하는 성능을 달성하였다. 또한 전체 파형 수준의 SDR을 직접 최적화하는 uSDR‑PIT 손실이 실용적인 성능 향상에 크게 기여함을 입증하였다. 향후 연구에서는 이러한 구조를 다중 스피커(>2) 상황이나 실시간 스트리밍 시스템에 적용하고, 비지도 학습과 결합하는 방향을 제안한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기