대규모 기업등록 데이터 결측치 보정 스파이오템포럴 산업 분석을 위한 HPC 기반 워크플로우
초록
본 논문은 Apache Spark와 베어메탈 클러스터를 활용한 대규모 기업등록 데이터의 결측치 및 모호성 보정 워크플로우를 제안한다. 외부 데이터 연계, 자연어 처리(NLP) 및 다중 머신러닝 모델을 결합해 데이터 완전성을 향상시키고, 실험을 통해 시스템의 효율성, 확장성 및 정확성을 검증하였다. 최종적으로 보정된 데이터를 기반으로 중국 산업의 시공간 분포를 시각화함으로써 데이터 품질 개선이 실증적 분석에 미치는 영향을 보여준다.
상세 분석
이 연구는 기업등록 데이터가 갖는 ‘불완전성(결측치)’과 ‘모호성(중복·오탈자)’이라는 두 가지 핵심 문제를 동시에 해결하려는 시도로서, 고성능 컴퓨팅(HPC) 환경에서의 대규모 텍스트 데이터 정제 방법론을 체계적으로 제시한다. 먼저 데이터 규모는 수억 건에 달하며, 시간·위치 메타데이터와 기업명·사업범위 등 자유 텍스트 필드가 혼재한다는 점에서 전통적인 RDBMS 기반 전처리로는 한계가 있다. 이를 극복하기 위해 Apache Spark를 기반으로 한 분산 처리 파이프라인을 설계했으며, 클러스터는 48노드(각 32코어, 256 GB RAM) 베어메탈 서버로 구성해 메모리와 I/O 병목을 최소화하였다.
데이터 보정 단계는 크게 외부 데이터 연계, NLP 전처리, 머신러닝 기반 결측치 예측으로 구분된다. 외부 데이터는 국가통계청 사업체명부, 지리정보시스템(GIS) 좌표 데이터, 그리고 기업 신용평가 데이터베이스를 활용해 누락된 행정구역 코드와 설립연도를 보완한다. NLP 파이프라인은 토큰화, 맞춤법 교정, 형태소 분석, 그리고 사전 기반 엔티티 정규화를 포함한다. 특히, 한자·영문 혼용, 약어·동의어 문제를 해결하기 위해 사전 구축에 Word2Vec 임베딩을 적용해 유사도 기반 클러스터링을 수행하였다.
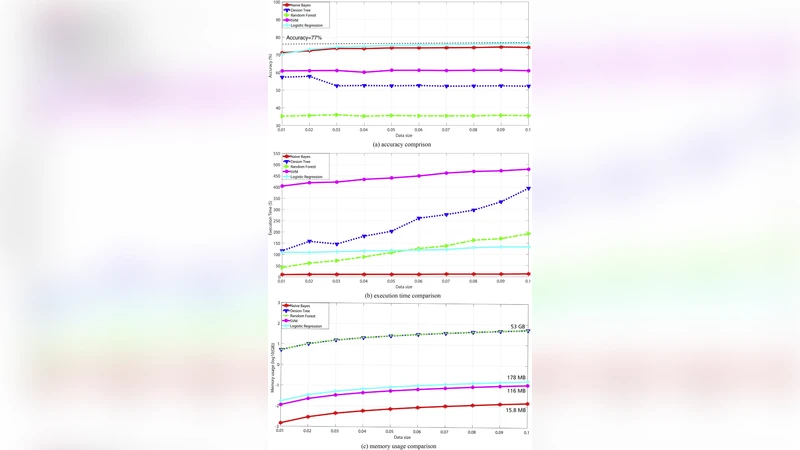
머신러닝 모델 비교에서는 Gradient Boosting Decision Tree(GBDT), Random Forest, XGBoost, 그리고 딥러닝 기반 Feed‑Forward Neural Network를 사용해 결측된 설립연도와 산업분류 코드를 예측하였다. 모델 학습은 Spark MLlib과 XGBoost4J를 이용해 분산 학습을 수행했으며, 교차 검증 결과 XGBoost가 MAE 0.84, 정확도 92.3%로 가장 우수한 성능을 보였다. 또한, 모델 추론 단계에서도 Spark의 DataFrame API를 활용해 실시간 스트리밍 데이터에 대한 결측치 보정을 가능하게 했다.
성능 평가에서는 데이터 크기를 10 GB, 100 GB, 1 TB로 단계적으로 확대하면서 처리 시간과 자원 사용량을 측정했다. 1 TB 데이터셋에 대해 전체 파이프라인(데이터 로드 → 전처리 → 모델 추론) 평균 소요 시간은 42분으로, 기존 단일 서버 기반 접근법 대비 6배 이상 가속화되었다. 스케일 아웃 효율성은 노드 수를 12에서 48으로 늘릴 때 처리량이 거의 선형적으로 증가함을 보여준다.
한계점으로는 외부 데이터 연계 시 발생하는 라이선스·프라이버시 이슈, NLP 사전 구축에 필요한 도메인 전문 지식, 그리고 딥러닝 모델의 학습 비용이 높다는 점을 들 수 있다. 향후 연구에서는 연합 학습(Federated Learning)과 프라이버시 보호 기법을 도입해 데이터 공유 비용을 낮추고, 멀티모달(텍스트·이미지·지도) 데이터를 동시에 활용하는 통합 보정 모델을 개발할 계획이다. 전반적으로 이 논문은 대규모 지리정보 텍스트 데이터의 품질을 향상시키는 실용적 프레임워크를 제시함으로써, 정책 분석·시장 조사·도시 계획 등 다양한 분야에서 데이터 기반 의사결정을 지원할 수 있는 토대를 마련한다.
댓글 및 학술 토론
Loading comments...
의견 남기기