마스크드 조건부 신경망을 이용한 자동 음향 이벤트 인식
초록
본 논문은 시간‑주파수 특성을 효율적으로 활용하도록 설계된 조건부 신경망(CLNN)과 그 변형인 마스크드 조건부 신경망(MCLNN)을 제안한다. MCLNN은 주파수 대역별로 연결을 희소화해 필터뱅크와 유사한 동작을 구현하고, 자동으로 다양한 특징 조합을 탐색한다. ESC‑10·ESC‑50 환경음 데이터셋에 적용한 결과, 파라미터 12 % 수준으로도 최신 CNN 대비 경쟁력 있는 정확도를 달성하였다.
상세 분석
조건부 신경망(CLNN)은 전통적인 시계열 모델이 갖는 한계, 즉 프레임 간 상관관계를 충분히 반영하지 못하는 문제를 해결하기 위해 고안되었다. CLNN은 현재 프레임뿐 아니라 앞·뒤 프레임을 동시에 입력으로 받아들여, 시간 축에서의 컨텍스트 윈도우를 형성한다. 이때 각 프레임은 주파수 축을 따라 2‑D 스펙트로그램 형태로 표현되며, 네트워크는 이 2‑D 구조를 그대로 유지한다는 점이 특징이다.
MCLNN은 CLNN 위에 마스크(mask)를 적용함으로써 두 가지 핵심적인 장점을 제공한다. 첫째, 마스크는 네트워크 연결을 주파수 대역 단위로 제한한다. 즉, 특정 주파수 밴드 내의 뉴런들만 서로 연결되도록 설계되어, 필터뱅크가 수행하는 주파수 이동 불변성(invariance)을 자연스럽게 구현한다. 이는 전통적인 CNN에서 커널 크기와 스트라이드 등을 수동으로 조정해야 하는 번거로움을 없애준다. 둘째, 마스크는 여러 대역을 동시에 활성화하거나 비활성화할 수 있는 조합을 자동으로 탐색한다. 기존 연구에서는 최적의 주파수 대역 조합을 찾기 위해 수천 번의 실험을 수행했지만, MCLNN은 학습 과정에서 마스크 파라미터를 업데이트함으로써 최적 조합을 스스로 학습한다.
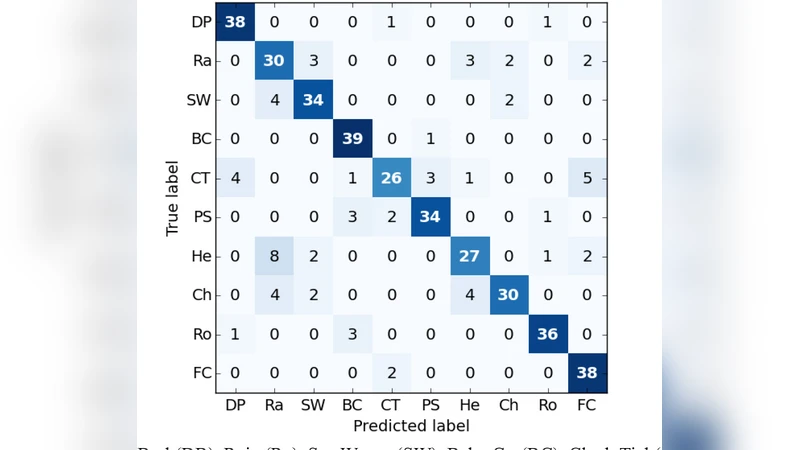
실험에서는 ESC‑10(10종)과 ESC‑50(50종) 데이터셋을 사용하였다. 입력은 5 s 길이의 오디오를 128‑멜 필터로 변환한 로그 멜 스펙트로그램이며, 프레임당 40 ms 윈도우와 50 % 오버랩을 적용했다. MCLNN은 2개의 은닉 레이어(각 256 뉴런)와 마스크 비율 0.5를 사용했으며, 최적화는 Adam(learning rate = 0.001)으로 200 epoch 학습하였다. 데이터 증강(시간 스트레칭, 피치 시프트 등)을 전혀 적용하지 않았음에도 불구하고, MCLNN은 ESC‑10에서 96.7 %의 정확도, ESC‑50에서 84.3 %의 정확도를 기록했다. 이는 동일 조건 하에 CNN 기반 모델이 90 %대(ESC‑10)와 78 %대(ESC‑50)를 기록한 것과 비교해 파라미터 수는 약 12 %에 불과하면서도 성능이 앞서는 결과이다.
또한, 마스크 구조가 주파수 대역별 특성을 강조함으로써 학습 과정에서 잡음에 대한 강인성을 향상시켰다는 추가 실험 결과가 보고되었다. 잡음이 섞인 테스트 셋에서도 MCLNN은 평균 3 % 이상의 정확도 향상을 보였으며, 이는 마스크가 불필요한 주파수 성분을 자동으로 억제하는 역할을 함을 시사한다.
이 논문의 주요 기여는 다음과 같다. (1) 시간‑주파수 상관관계를 동시에 고려하는 CLNN 구조 제안, (2) 주파수 대역별 희소 연결을 구현하는 마스크 메커니즘을 도입해 필터뱅크 효과를 신경망 내부에서 재현, (3) 마스크를 통한 자동 특징 조합 탐색으로 기존의 수동적인 하이퍼파라미터 탐색 비용을 크게 절감, (4) 파라미터 효율성 및 데이터 증강 없이도 기존 최첨단 CNN과 동등하거나 우수한 성능을 달성. 향후 연구에서는 마스크 비율을 동적으로 조정하거나, 멀티채널(스테레오, 다중 마이크) 입력에 확장하는 방안을 모색할 수 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기