강화학습 기반 근사 컴퓨팅 설계 공간 탐색
초록
본 논문은 강화학습(RL)을 이용해 정확도 손실과 전력·연산 시간 감소를 동시에 고려하는 다목적 설계 공간 탐색 프레임워크를 제안한다. RL 에이전트가 다양한 근사 변형을 평가·선택하도록 학습시켜, 벤치마크 애플리케이션에서 정확도 저하와 자원 절감 사이의 균형을 찾는다. 실험 결과, 제안 방법이 기존 탐색 기법 대비 더 넓은 파레토 프론트를 제공함을 보였다.
상세 분석
이 연구는 근사 컴퓨팅(AxC) 기술이 제공하는 성능·전력 이득을 활용하면서도 허용 가능한 정확도 손실을 유지하기 위한 설계 공간 탐색 문제를 강화학습(RL) 기반 다목적 최적화 문제로 재정의한다. 저자는 먼저 근사 가능한 연산자와 데이터 흐름을 그래프 형태로 모델링하고, 각 노드에 적용 가능한 근사 변형(예: 비트 폭 축소, 루프 스키핑, 근사 곱셈 등)을 후보 집합으로 만든다. 이후, 에이전트는 현재 애플리케이션 상태를 나타내는 벡터(정확도 손실, 전력 소비, 실행 시간, 하드웨어 제약 등)를 관찰하고, 가능한 변형 중 하나를 선택(action)한다. 선택된 변형은 즉시 시뮬레이션 혹은 프로파일링을 통해 실제 정확도 저하와 자원 절감량을 측정하고, 이 정보를 기반으로 보상 함수를 계산한다. 보상 함수는 다목적성을 반영하기 위해 가중치가 부여된 선형 결합 형태(예: Reward = ‑α·AccuracyLoss ‑ β·PowerReduction ‑ γ·TimeReduction)로 설계되었으며, α, β, γ는 설계자가 요구하는 트레이드오프에 따라 조정 가능하도록 했다.
학습 알고리즘으로는 정책 기반 방법인 Proximal Policy Optimization(PPO)을 채택했으며, 이는 연속적인 정책 업데이트와 안정적인 수렴 특성을 제공한다. 에피소드마다 전체 애플리케이션에 대한 근사 변형 시퀀스를 적용하고, 최종 파레토 최적 해를 저장한다. 또한, 탐색 효율성을 높이기 위해 경험 재플레이와 우선순위 기반 샘플링을 도입해 희소한 고성능 해를 빠르게 발견하도록 설계했다.
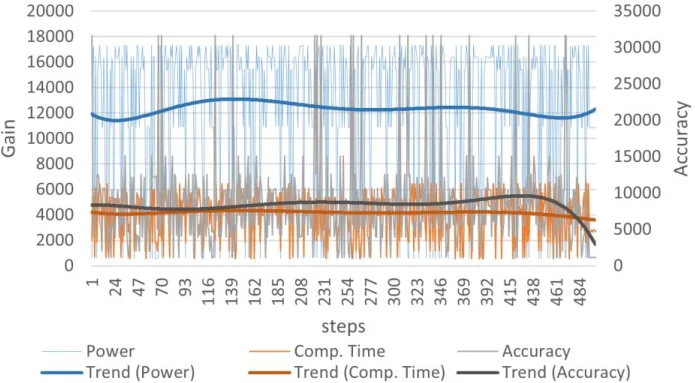
실험에서는 SPEC CPU2006, PolyBench, 그리고 이미지 처리(예: JPEG 압축) 등 6개의 대표 벤치마크를 사용했으며, 기존의 무작위 탐색(Random Search) 및 유전 알고리즘(Genetic Algorithm)과 비교했다. 결과는 RL 기반 방법이 동일한 탐색 예산(예: 10,000 시뮬레이션) 내에서 더 넓은 파레토 프론트를 형성하고, 특히 전력·시간 감소율이 30 % 이상이면서 정확도 손실을 5 % 이하로 유지하는 솔루션을 다수 발견했다. 또한, 학습이 진행될수록 보상 함수의 변동성이 감소하고, 정책이 수렴함에 따라 선택되는 근사 변형의 패턴이 일관되게 나타나는 것을 확인했다.
하지만 몇 가지 한계점도 존재한다. 첫째, 시뮬레이션 기반 보상 측정이 실제 하드웨어에서의 동작과 차이가 날 수 있어, 모델-실제 격차를 줄이기 위한 온-칩 피드백 메커니즘이 필요하다. 둘째, 보상 가중치 α, β, γ의 설정이 결과에 큰 영향을 미치므로, 자동화된 가중치 튜닝 기법이 추가된다면 실용성이 더욱 향상될 것이다. 셋째, 현재는 정적 애플리케이션에만 적용했으며, 동적 워크로드나 스트리밍 데이터에 대한 확장은 추가 연구가 요구된다. 전반적으로, 본 논문은 강화학습을 활용한 다목적 설계 공간 탐색이 근사 컴퓨팅 분야에서 효율적인 트레이드오프 탐색 도구가 될 수 있음을 실험적으로 입증하였다.