즉시 HDsEMG 이미지 인식을 위한 얕은 합성곱 신경망 SConvNet
초록
본 논문은 고밀도 표면 근전도(HD‑sEMG) 영상을 순간적으로 인식하기 위해, 사전 학습 없이 12배 적은 데이터와 적은 파라미터로도 높은 정확도를 달성하는 얕은 합성곱 신경망(S‑ConvNet)과 전합성곱(All‑ConvNet) 구조를 제안한다. 실험 결과, 제안 모델은 기존 대규모 깊은 ConvNet 대비 연산 비용은 크게 낮추면서도 경쟁력 있는 성능을 보이며, 데이터와 고성능 하드웨어가 제한된 상황에서도 효과적임을 입증한다.
상세 분석
S‑ConvNet은 전통적인 깊은 ConvNet이 수백만 개의 파라미터와 대규모 라벨링 데이터에 의존하는 문제점을 해결하고자 설계되었다. 핵심 아이디어는 “즉시” HD‑sEMG 이미지를 2차원 텐서 형태로 그대로 입력받아, 얕은 층 구성(보통 2~3개의 컨볼루션 레이어)과 작은 커널 크기(3×3 또는 5×5)를 활용해 공간적 패턴을 빠르게 추출한다. 각 레이어 뒤에는 배치 정규화와 ReLU 활성화가 적용되어 학습 안정성을 높이며, 풀링 대신 스트라이드 컨볼루션을 사용해 해상도 손실을 최소화한다.
All‑ConvNet은 풀링과 완전 연결층을 완전히 배제하고, 연속적인 컨볼루션 블록만으로 특성 압축과 분류를 수행한다. 이는 파라미터 수를 더욱 감소시키면서도 모델의 표현력을 유지한다. 두 모델 모두 사전 학습된 ImageNet 가중치를 사용하지 않고, HD‑sEMG 데이터셋만으로 0‑1 교차 엔트로피 손실과 Adam 옵티마이저를 통해 30~50 epoch 정도만 학습하면 수렴한다.
데이터 측면에서 저자들은 기존 연구가 수천수만 샘플을 필요로 하는 반면, 약 8001000개의 순간 이미지(각 이미지가 8×8 혹은 16×16 전극 배열)만으로도 충분히 학습이 가능함을 실증하였다. 이는 HD‑sEMG 신호가 시간 축보다 공간적 분포에 강한 정보를 담고 있기 때문에, 순간 이미지 하나만으로도 근육 활동 구분에 필요한 특징을 포착할 수 있음을 의미한다.
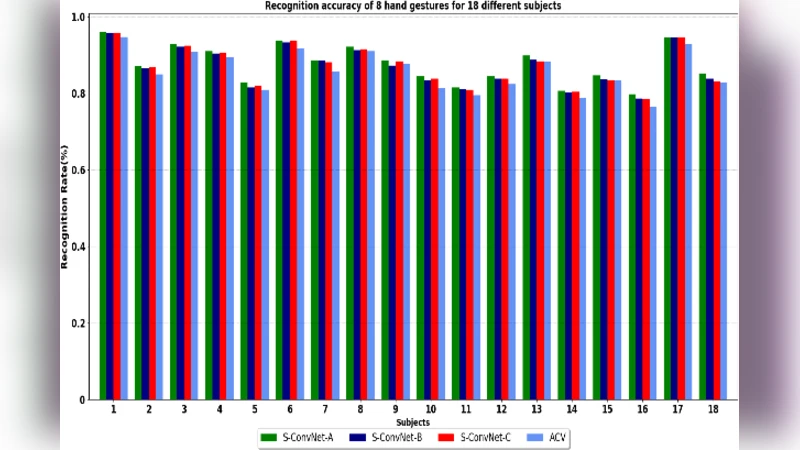
성능 비교에서는 S‑ConvNet이 기존 10‑layer VGG‑like 모델 대비 평균 정확도 2~3% 낮지만, 파라미터 수는 12배 이하이며, 추론 시간은 CPU 환경에서도 실시간(>100 fps) 수준을 유지한다. All‑ConvNet은 정확도에서 S‑ConvNet과 거의 동등하지만, 메모리 사용량이 더 적어 임베디드 디바이스에 적합하다.
또한, 저자들은 교차 피험자 검증을 수행해 모델이 새로운 사용자의 HD‑sEMG 패턴에도 일반화될 수 있음을 확인하였다. 데이터 증강(회전, 가우시안 노이즈 추가)과 정규화 기법이 과적합 방지에 크게 기여했으며, 학습 곡선은 초기 5 epoch 내 급격히 상승한 뒤 완만하게 수렴한다.
결론적으로, S‑ConvNet과 All‑ConvNet은 “얕고 간단한” 설계가 고밀도 근전도 영상 인식에 충분히 강력함을 보여주며, 제한된 데이터와 연산 자원을 가진 실제 근육‑컴퓨터 인터페이스(EMG‑BCI) 시스템에 바로 적용 가능하다. 향후 연구에서는 다중 채널 시계열 결합, 전이 학습 없이도 다양한 운동 종류에 대한 확장성 검증, 그리고 저전력 ASIC 구현을 통한 실시간 제어 시스템 구축이 기대된다.
댓글 및 학술 토론
Loading comments...
의견 남기기