신경그래픽스 하드웨어 가속
초록
본 논문은 NeRF, NSDF, NVR, GIA 등 네 가지 대표적인 신경 그래픽스 애플리케이션을 대상으로 4K 60FPS 및 AR/VR 수준의 실시간 렌더링을 달성하기 위해 현재 GPU가 부족한 성능 격차를 분석한다. 입력 인코딩과 MLP 연산이 전체 실행 시간의 60 % 이상을 차지한다는 사실을 발견하고, 이를 전용 엔진으로 가속하는 Neural Graphics Processing Cluster(NGPC) 아키텍처를 제안한다. NGPC는 인코딩 전용 가속기와 MLP 전용 코어, 그리고 커널 융합을 통해 최대 58배의 엔드‑투‑엔드 성능 향상을 제공한다.
상세 분석
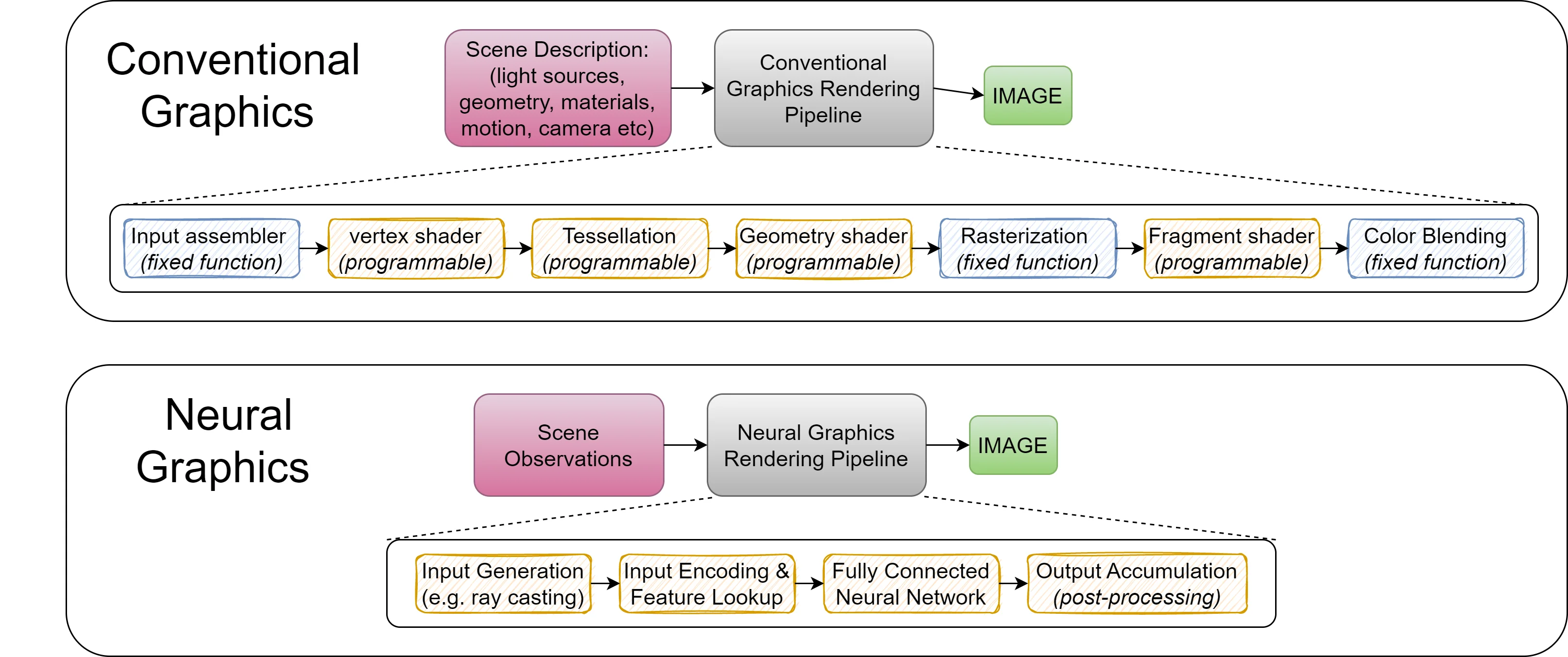
본 연구는 최근 급부상하고 있는 신경 그래픽스(NR 기반 그래픽스) 분야가 실시간 고해상도 렌더링을 위해서는 기존 GPU만으로는 충분하지 않다는 근본적인 한계를 정량적으로 규명한다. 네 가지 대표 애플리케이션(NeRF, NSDF, NVR, GIA)을 선정하고, 4K 60FPS 목표와 AR/VR용 4K ~ 8K 120FPS 목표를 기준으로 성능 요구량을 산출한 결과, 현재 상용 GPU가 달성해야 할 FLOPS와 메모리 대역폭이 각각 1.5배에서 55.5배, 그리고 전력 소모 측면에서는 2~4 오더의 격차가 존재함을 확인했다. 특히, 입력 인코딩 단계에서 사용되는 다중 해시그리드(Multi‑Resolution Hashgrid)와 다중 해상도 밀집 그리드(Densegrid) 인코딩이 전체 실행 시간의 60 % 이상을 차지한다는 점이 핵심 병목으로 드러났다. 이러한 인코딩 연산은 대규모 테이블 조회와 비선형 해시 매핑을 반복 수행해야 하며, GPU의 일반적인 SIMD 구조에서는 메모리 접근 패턴이 비정형적이어서 캐시 효율이 급격히 저하된다. 이어지는 MLP(다층 퍼셉트론) 연산 역시 수천 개의 작은 행렬‑벡터 곱을 반복 수행하는데, 이는 GPU의 대규모 행렬 연산 유닛에 최적화되지 않아 연산 효율이 떨어진다. 논문은 이러한 두 핵심 모듈을 전용 하드웨어 가속기로 분리하고, 나머지 부수 연산(예: 샘플링, 색상 합성 등)을 하나의 파이프라인으로 융합함으로써 전체 파이프라인의 레이턴시와 오버헤드를 최소화하는 NGPC(Neral Graphics Processing Cluster) 아키텍처를 설계한다. NGPC는 (1) 인코딩 전용 SRAM‑ 기반 캐시와 해시 매핑 전용 연산 유닛, (2) 고정밀도·저전력 MLP 코어, (3) 커널 융합을 위한 다중 스레드 스케줄러를 포함한다. 실험 결과, 해시그리드 인코딩에 대해 스케일 팩터 8, 16, 32, 64에서 각각 12.94×, 20.85×, 33.73×, 39.04×의 가속을 달성했으며, 전체 애플리케이션 레벨에서는 평균 58.36배, 최악의 경우 55.5배에 달하는 성능 향상을 기록했다. 특히, NGPC를 적용한 NeRF는 4K 30FPS, 나머지 세 애플리케이션은 8K 120FPS를 실시간으로 렌더링할 수 있게 되어, 기존 GPU 기반 구현이 불가능했던 실시간 AR/VR 시나리오를 현실화한다. 이러한 결과는 신경 그래픽스가 차세대 그래픽 파이프라인의 핵심 요소로 자리매김하기 위해서는 전용 하드웨어 지원이 필수적임을 강력히 시사한다.
댓글 및 학술 토론
Loading comments...
의견 남기기