리얼리즘 감정 제어 오디오 기반 아바타
초록
READ Avatars는 오디오 입력을 이용해 2D 아바타를 실시간으로 구동하면서, 감정을 연속적인 강도로 정밀하게 제어할 수 있는 3D 기반 파이프라인이다. 다대다 매핑 문제를 해결하기 위해 오디오‑표정 생성기에 GAN 손실을 도입하고, 입 내부와 복잡한 입 모양을 재현하기 위해 오디오‑조건부 신경 텍스처(SIREN 기반)를 사용한다. 새로운 감정 재현 지표(A/V‑EMD)와 사용자 연구를 통해 기존 방법들을 시각 품질, 입동기 일치, 감정 명료도 모두에서 능가함을 입증한다.
상세 분석
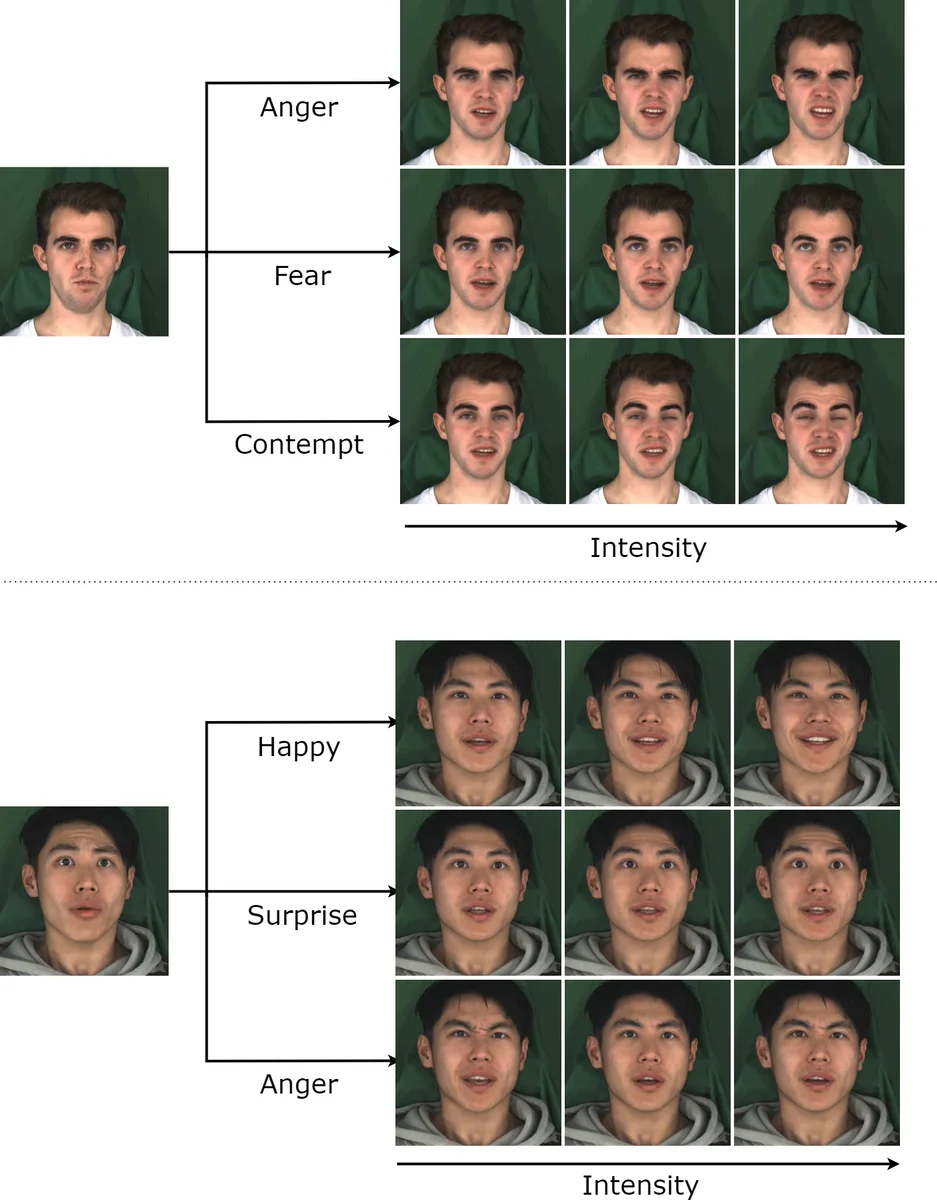
본 논문은 “오디오 → 표정” 매핑이 다대다 관계라는 근본적인 한계를 GAN 기반 적대적 학습으로 완화한다는 점에서 의미가 크다. 기존 회귀식 모델은 평균화된 파라미터를 출력해 입술 움직임이 과도하게 부드러워지는 문제를 안고 있었지만, 판별기가 실제 파라미터 분포와 생성 파라미터를 구분하도록 학습함으로써 미세한 표정 변화를 보존한다. 특히, 감정 라벨을 N‑1 차원의 연속 벡터로 설계해 ‘중립(0)’에서 각 감정 축으로 강도를 조절하도록 함으로써, 감정을 이산 카테고리로만 제한하던 기존 3D 기반 방법들보다 훨씬 정교한 감정 제어가 가능해졌다.
두 번째 핵심은 입 내부와 복잡한 입 모양을 재현하기 위한 오디오‑조건부 신경 텍스처이다. 기존 3DMM(FLAME)은 입술 외곽과 기본적인 입술 움직임만을 모델링하고, 혀·치아·입 안쪽 디테일을 전혀 표현하지 못한다. 저자들은 UV 좌표에 직접 SIREN MLP를 적용해 고해상도 텍스처를 생성하고, 여기서 오디오 특징을 concat하여 텍스처를 조건부로 변형한다. 이렇게 하면 입 내부의 움직임이 오디오 스펙트럼에 직접 연결되므로, 발음에 따라 혀와 입천장의 미세 움직임까지 자연스럽게 재현된다. 또한, 텍스처 루킹을 배제해 연산 효율성을 높이고, 해상도 독립적인 표현을 가능하게 만든 점도 주목할 만하다.
렌더링 단계에서는 16채널 신경 텍스처를 rasterize한 뒤, UNet 기반 디퍼드 렌더러에 투입해 최종 프레임을 합성한다. 여기서 L1 손실과 속도 손실(L_vel)을 함께 최적화해 시간적 일관성을 확보하고, GAN 손실을 통해 시각적 리얼리즘을 강화한다.
평가 측면에서는 FID, LSE‑D/C(입동기 정확도), 그리고 새롭게 제안한 A/V‑EMD(감정 재현 거리)를 사용해 정량적 비교를 수행했다. 사용자 연구에서도 제안 방법이 기존 TVG, MEAD, EVP보다 감정 전달력과 입동기 정확도에서 유의미하게 우수함을 보였다.
하지만 몇 가지 한계도 존재한다. 3DMM 피팅 단계가 사전에 촬영된 고품질 비디오를 필요로 하며, 피사체마다 모델을 재학습해야 한다는 점은 실시간 대규모 서비스 적용에 제약이 될 수 있다. 또한, 오디오‑조건부 텍스처가 특정 화자에 과적합될 위험이 있으며, 새로운 화자에 대한 일반화 성능에 대한 실험이 부족하다. 마지막으로, GAN 기반 파라미터 생성이 불안정할 경우 비현실적인 표정이 발생할 가능성도 있다. 전반적으로, 다대다 매핑 문제와 입 내부 재현이라는 두 핵심 난제를 효과적으로 해결했으며, 감정 제어의 연속성까지 제공한 점에서 현존 최첨단 오디오‑구동 아바타 기술을 한 단계 끌어올린 연구라 평가할 수 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기