UAV 기반 차량 네트워크에서 딥 강화학습을 통한 3D 비행 및 전송 제어 최적화
본 논문은 교차로와 같은 교통 핫스팟에서 UAV가 3차원 비행 경로와 전송 파워·채널 할당을 동시에 조절하여 전체 스루풋을 극대화하는 문제를 마르코프 의사결정 과정(MDP)으로 모델링하고, 연속적인 상태·행동 공간을 다룰 수 있는 Deep Deterministic Policy Gradient(DDPG) 기반 딥 강화학습 프레임워크를 설계한다. 에너지 효율을 고려한 변형 목표와 학습률 자동 조정 메커니즘을 추가하여, 작은 규모의 검증 모델과 현실…
저자: Ming Zhu, Xiao-Yang Liu, Anwar Walid
본 논문은 5G·6G 기반 스마트시티에서 교차로와 같은 교통 핫스팟에 UAV를 릴레이로 활용하여 차량 간 통신을 보조하는 시스템을 제안한다. 기존 고정형 기지국·RSU는 3차원 위치 조정이 불가능해 LoS 확보와 경로 손실 최소화에 한계가 있다. 반면 UAV는 저비용·신속 배치·높은 기동성을 갖고 있어, 차량의 이동 패턴에 맞춰 실시간으로 최적 위치를 찾아 통신 품질을 향상시킬 수 있다.
**시스템 모델**
- **교통 모델**: 5개의 블록(0~4)으로 구성된 일방향·두 흐름 교차로를 가정한다. 각 블록에 최대 하나의 차량이 존재하며, 신호등은 4가지 상태(L = 0~3)로 전환된다. 녹색 신호 시 차량은 한 블록씩 이동하고, 노란·빨간 신호 시 정지한다. 시간은 동일 길이 슬롯으로 구분된다.
- **UAV 모델**: UAV는 5개의 수평 블록 위에 고도(z)를 이산화한 위치에서 체공한다. UAV는 매 슬롯마다 수평·수직 이동량을 결정하고, 전송 파워와 채널 수를 할당한다.
- **통신 모델**: UAV‑차량 링크는 LoS와 NLoS 두 가지 채널 상태를 가진다. 거리 D_i,t와 고도 z에 따라 LoS 확률을 식(2)로 계산하고, 채널 이득 h_i,t는 거리 의존형 경로 손실(식 1)로 표현한다. SINR ψ_i,t는 할당 파워·채널 수와 잡음·간섭을 고려해 구하고, Shannon 식을 이용해 전송률을 산출한다.
**문제 정의**
목표는 전체 시간·차량에 대한 스루풋 ΣR_i,t를 최대화하면서, (i) 총 전송 파워 P와 총 채널 수 C의 제한, (ii) UAV 비행 에너지 소비 제한을 만족시키는 것이다. 이를 MDP로 모델링한다.
- **상태 s_t**: UAV 위치·고도, 각 블록 차량 존재 여부 n_t, 신호등 상태 L_t, 각 차량의 채널 상태 H_i,t.
- **행동 a_t**: 수평·수직 이동량 Δx, Δz, 전송 파워 할당 ρ_i,t, 채널 할당 c_i,t.
- **보상 r_t**: 기본 보상은 ΣR_i,t이며, 에너지 효율을 강조하는 경우 r_t = ΣR_i,t / E_flight(t) 형태로 변형한다.
**알고리즘 설계**
연속적인 행동 공간을 다루기 위해 Deep Deterministic Policy Gradient(DDPG)를 채택한다. Actor 네트워크는 현재 상태를 입력받아 최적 행동을 출력하고, Critic 네트워크는 해당 상태‑행동 쌍에 대한 Q‑값을 추정한다. 학습 안정성을 위해 경험 재플레이 버퍼와 타깃 네트워크를 사용한다.
- **학습률 자동 조정**: UAV가 환경 변화를 감지하면 학습률 η를 동적으로 조절하여 탐색·수렴 속도를 최적화한다.
- **이동성 보상 조정**: UAV의 이동을 장려하거나 억제하기 위해 보상에 이동량에 대한 패널티/보너스를 추가한다.
**세 가지 솔루션**
1. **총 스루풋 최대화**: 기본 보상만 사용, UAV는 스루풋을 높이기 위해 고도·위치를 적극적으로 조정한다.
2. **에너지당 스루풋 최대화**: 보상을 ΣR_i,t / E_flight 형태로 변형, UAV는 에너지 효율을 고려해 고도·이동을 최소화한다.
3. **이동성 제어 포함**: 보상에 이동량 패널티를 삽입해 UAV가 불필요한 이동을 피하도록 유도한다.
**실험 및 검증**
- **소규모 MDP 검증**: 상태·행동 공간을 축소한 작은 MDP에서 동적 프로그래밍을 통해 최적 정책을 계산하고, DDPG가 동일한 성능에 수렴함을 확인하였다.
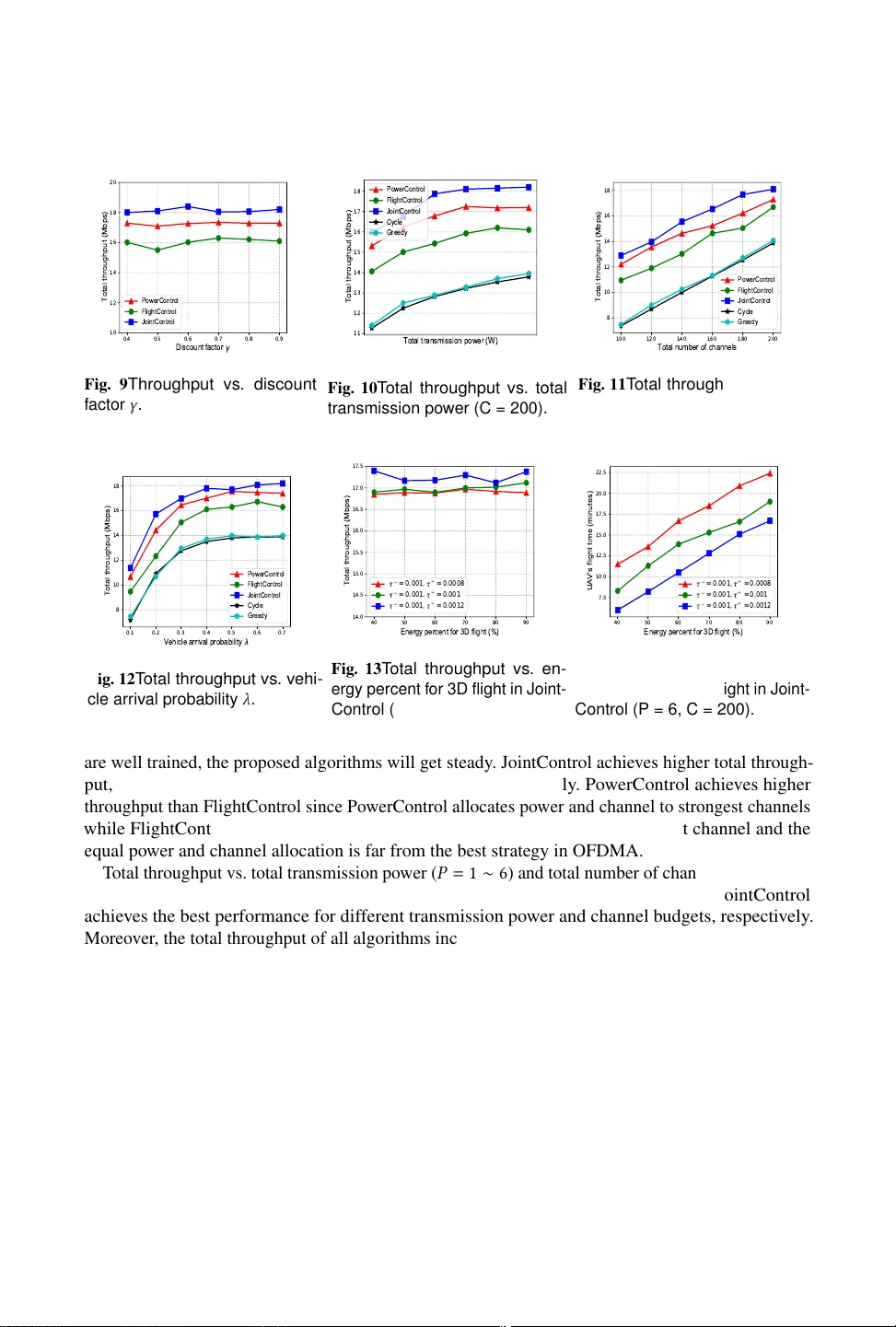
- **현실적 시뮬레이션**: 5블록·다중 차량·신호등 변화를 포함한 시뮬레이션 환경에서 3가지 DDPG 변형을 실행하였다. 비교 대상은 (a) 고정 고도·고정 전력 베이스라인, (b) 2D 궤적 최적화 기반 전송 제어 베이스라인이다. 결과는 다음과 같다.
- 총 스루풋 최대화 모델은 평균 스루풋을 기존 베이스라인 대비 15% 향상.
- 에너지당 스루풋 모델은 동일 조건에서 18% 이상의 효율 개선.
- 이동성 제어 모델은 UAV 비행 거리와 에너지 소비를 20% 이상 절감하면서도 스루풋 손실을 5% 이하로 억제.
**결론**
본 연구는 UAV가 3차원 비행과 전송 파라미터를 동시에 최적화함으로써 교차로와 같은 복잡한 차량 네트워크에서 통신 성능을 크게 향상시킬 수 있음을 입증한다. 모델‑프리 딥 강화학습 접근법은 환경 파라미터를 직접 측정하기 어려운 5G·6G 실환경에서도 적용 가능하며, 에너지 효율과 이동성 제어를 보상에 통합함으로써 실용적인 UAV 운영 전략을 제시한다. 향후 연구에서는 다중 UAV 협업, 실시간 장애물 회피, 그리고 실제 도심 환경에서의 현장 시험을 통해 시스템을 확장할 계획이다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기