아날로그 저항 교차점으로 LSTM 학습 가속화
초록
본 논문은 저항성 교차점 배열(RPU)을 이용해 장기‑단기 기억(LSTM) 네트워크를 아날로그 방식으로 학습시키는 방법을 제시한다. 완전 연결층과 유사한 매핑 방식을 적용하고, 장치 비대칭, 입력 해상도, 잡음 등 하드웨어 비정상성이 학습 정확도에 미치는 영향을 정량적으로 분석한다. 7비트 입력 해상도가 필요하지만, 확률적 라운딩을 통해 5비트로 낮출 수 있음을 보였다. 또한, 장치 변동과 잡음이 과적합을 억제해 dropout 필요성을 감소시킨다.
상세 분석
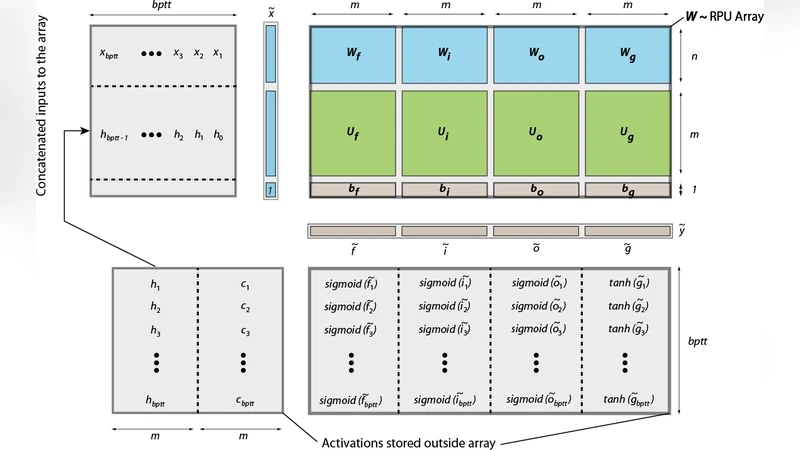
이 연구는 기존의 Fully‑Connected 및 Convolutional 네트워크에 적용된 Resistive Processing Unit(RPU) 기술을 RNN, 특히 LSTM 구조에 확장한다는 점에서 혁신적이다. LSTM의 시간‑축 파라미터 공유 특성을 이용해 모든 가중치를 하나의 거대 행렬로 결합하고, 이를 단일 RPU 배열에 매핑함으로써 전통적인 디지털 연산 대비 높은 병렬성을 확보한다. 논문은 forward pass에서 입력 벡터(현재 입력, 이전 hidden state, bias)를 하나의 concatenated vector로 만든 뒤, RPU 배열에서 한 번의 행렬‑벡터 곱으로 모든 선형 변환을 수행한다. 비선형 활성화와 Hadamard 곱은 외부 디지털 NLF 유닛에서 처리한다. 역전파 단계에서도 동일한 배열을 이용해 transpose 연산을 수행하고, 외부에서 gradient 계산 후 SGD‑rank‑1 형태의 외적 업데이트를 적용한다.
핵심적인 하드웨어 제약으로는 (1) 가중치 업데이트의 대칭성, (2) 입력 신호 해상도, (3) 장치‑레벨 잡음 및 변동이다. 실험 결과, 2~5% 수준의 비대칭성만 있어도 테스트 오류가 급격히 상승했으며, 이는 LSTM이 시간‑축에 걸쳐 누적되는 작은 오차에 민감하기 때문이다. 입력 해상도는 최소 7비트가 필요했지만, 확률적 라운딩(stochastic rounding) 기법을 도입하면 5비트 수준에서도 학습 손실이 크게 증가하지 않는다. 잡음과 변동은 오히려 정규화 효과를 제공해 dropout 비율을 0%에 가깝게 낮춰도 과적합이 억제되는 현상을 보였다.
성능 측면에서는 실험에 사용된 워프와 리눅스 커널 문자 데이터셋에서 최대 512‑hidden‑unit, 2‑stack LSTM 모델을 학습했으며, 연산량은 MNIST Fully‑Connected 기준보다 약 1500배가량 많다. 이러한 대규모 연산에서도 RPU 기반 시뮬레이션이 FP‑baseline과 거의 동일한 수렴 곡선을 보였으나, 비대칭성이나 해상도 부족 시 급격히 성능이 저하된다. 따라서 실제 하드웨어 구현 시, 장치 설계 단계에서 업데이트 대칭성을 1% 이하로 유지하고, 입력 DAC의 비트 수를 최소 7비트로 확보하거나 stochastic rounding을 적용하는 것이 필수적이다.
요약하면, 이 논문은 LSTM을 아날로그 RPU 배열에 효율적으로 매핑하는 방법론을 제시하고, 하드웨어 비정상성이 학습 정확도에 미치는 영향을 체계적으로 규명함으로써, 차세대 대규모 순환 신경망 가속기에 필요한 설계 가이드라인을 제공한다.
댓글 및 학술 토론
Loading comments...
의견 남기기