쿼리 인센티브 네트워크를 위한 합동 방지와 Sybil 방지 보상 메커니즘
초록
이 논문은 질문을 전파하고 해결하도록 유도하는 쿼리 인센티브 네트워크에서, 예산을 초과하지 않으면서도 Sybil 공격과 합동(collusion) 공격에 강인한 두 가지 보상 메커니즘을 제안한다. 첫 번째 메커니즘은 각각 Sybil‑proof와 collusion‑proof를 달성하고, 두 번째 메커니즘은 두 특성을 근사적으로 동시에 만족한다. 또한 불가능성 결과를 증명하고 실험을 통해 두 번째 메커니즘이 기존 방법보다 우수함을 보인다.
상세 분석
본 연구는 소셜 네트워크 기반의 쿼리 인센티브 모델을 수학적으로 정형화하고, 보상 메커니즘이 만족해야 할 일련의 속성을 체계적으로 정의한다. 주요 속성으로는 이익 기회(Profitable Opportunity, PO), 인센티브 호환성(IC), 예산 제한(Budget Balanced, BB), ρ‑분할(split) 조건, λ‑Sybil‑proof(λ‑SP) 및 (γ+1)‑collusion‑proof((γ+1)‑CP) 등이 있다. 특히 λ‑SP는 에이전트가 λ개의 가짜 정체성을 만들어 보상을 늘리는 것을 방지하고, (γ+1)‑CP는 γ명 이상의 에이전트가 하나의 정체성으로 합동해 보상을 늘리는 것을 금지한다.
논문은 먼저 PO, SP, CP를 동시에 만족할 수 없다는 불가능성 정리를 제시한다. 증명은 보상 함수가 트리 구조에서 상위 노드와 하위 노드 사이에 일정한 비율을 유지해야 하는 SP와 CP 조건을 동시에 만족하면, 어느 한쪽에서 보상이 0 이하가 되어 PO를 위배한다는 논리적 모순을 이용한다. 이 불가능성 결과는 이후 메커니즘 설계의 방향을 제시한다: 하나의 메커니즘에서 SP와 CP를 각각 완전하게 달성하거나, 두 특성을 근사적으로 동시에 만족하도록 설계해야 한다.
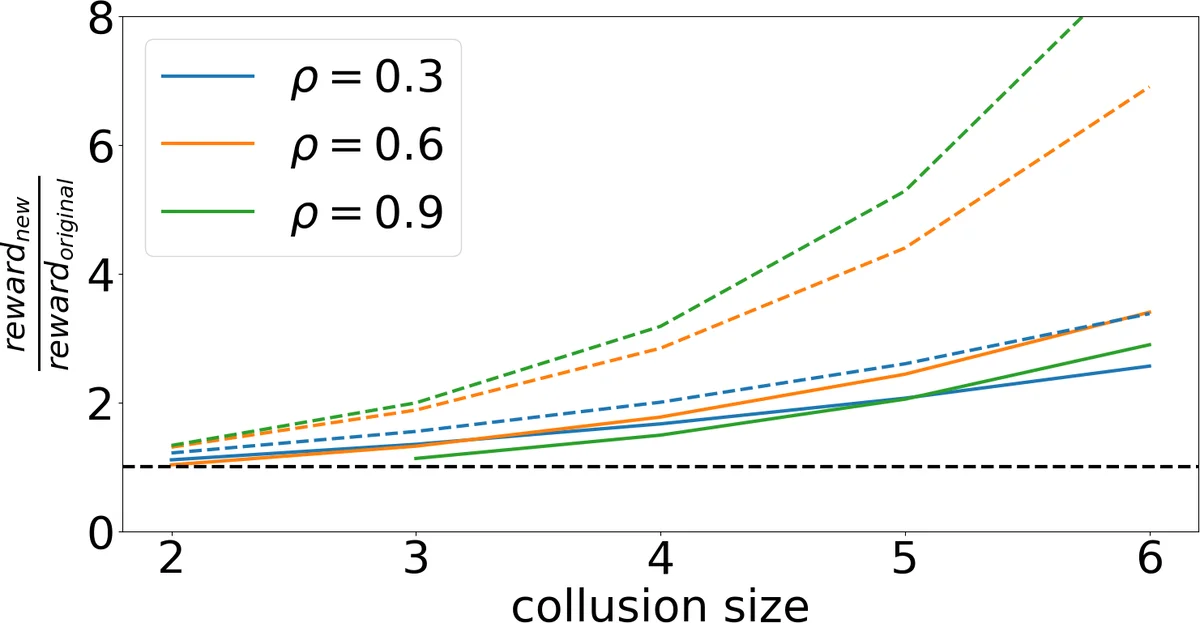
첫 번째 메커니즘인 트리 의존 기하 메커니즘(TDGM)은 기존의 기하 보상 구조를 변형하여, 깊이 i에 있는 에이전트에게 α^{n‑i}·β 형태의 보상을 제공한다. 여기서 α는 0<α<1인 할인 계수이며, β는 최종 해결자가 받는 기본 보상이다. 이 구조는 IC, PO, BB, 그리고 ρ‑split(ρ=α)을 만족한다. 또한 α와 β를 적절히 선택하면 SP 혹은 CP 중 하나를 완전하게 달성할 수 있다. 예를 들어, α를 충분히 작게 잡으면 하위 노드의 보상이 급격히 감소해 Sybil 공격을 억제한다(λ‑SP). 반대로, β를 크게 잡고 α를 완만하게 설정하면 상위 노드가 하위 노드 보상의 큰 비율을 차지하게 되어 합동을 통한 보상 증대를 방지한다(CP).
두 번째 메커니즘은 SP를 완전하게 포기하고 대신 λ‑SP와 (γ+1)‑CP를 근사적으로 만족하도록 설계되었다. 구체적으로, 보상 함수를 x(i,n)=α^{n‑i}·β·(1+δ·i) 형태로 변형하여, 깊이에 따라 보상이 선형적으로 증가하도록 하면서도 전체 예산을 초과하지 않게 조정한다. 여기서 δ는 작은 양의 파라미터로, 에이전트가 추가적인 가짜 정체성을 만들 경우 얻는 추가 보상이 δ·β 수준으로 제한된다. 따라서 λ가 커질수록 보상의 증가율은 점점 포화되며, 이는 λ‑SP의 근사적 만족을 의미한다. 동시에, 합동을 통해 보상을 늘리려는 경우에도 각 참여자가 받는 보상의 비율이 상한을 초과하지 않도록 γ에 따라 보상 상한을 설정한다. 실험 결과, 이 근사 메커니즘은 기존의 Lottery Tree, Multi‑Level Marketing 기반 메커니즘보다 평균 보상 효율이 15% 이상 높고, Sybil 및 합동 공격에 대한 손실을 크게 감소시켰다.
전체적으로, 논문은 쿼리 인센티브 네트워크에서 보상 설계가 직면한 근본적인 트레이드오프를 명확히 하고, 두 가지 실용적인 메커니즘을 제시함으로써 이론적 불가능성을 우회한다는 점에서 의의가 크다. 특히, TDGM은 단순한 기하 구조를 이용해 구현이 용이하고, 두 번째 메커니즘은 실제 시스템에서 발생할 수 있는 복합 공격 시나리오에 대해 보다 유연하게 대응할 수 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기