노이즈 채널에서 분산 가설 검정의 오류 지수 트레이드오프
본 논문은 관측자와 의사결정자가 각각 i.i.d. 샘플을 보유하고, 관측자가 이산 메모리리스 채널을 통해 정보를 전송하는 두 단말 분산 이진 가설 검정 문제를 다룬다. 타입 기반 압축·불균등 오류 보호(UEP)와 하이브리드 코딩을 이용한 두 가지 스킴을 제안하고, 각각에 대한 오류 지수(제1종·제2종) 트레이드오프의 내부 경계를 제시한다. 공동 코딩 스킴이 일부 영역에서 분리 스킴보다 엄격히 우수함을 예시를 통해 보인다.
저자: Sreejith Sreekumar, Deniz G"und"uz
본 논문은 두 단말이 각각 n개의 i.i.d. 샘플을 관측하고, 관측자가 이산 메모리리스 채널(DMC)을 통해 정보를 전송하는 상황에서 이진 가설 검정 문제를 다룬다. 목표는 샘플 수 n이 커짐에 따라 제1종 오류 확률 αₙ과 제2종 오류 확률 βₙ이 각각 exp(−nκ_α)와 exp(−nκ_β)로 감소하도록 하는 오류 지수 쌍 (κ_α, κ_β)의 가능한 영역을 규명하는 것이다. 이를 위해 저자들은 먼저 문제 정의와 기초 기호를 명확히 하고, 오류 지수 영역 R을 정의한다. R은 모든 달성 가능한 (κ_α, κ_β) 쌍의 폐포이며, κ_α에 대한 최대 가능한 κ_β를 κ(κ_α)라 두어 R = { (κ_α, κ(κ_α)) : κ_α ∈ (0, κ_α^*) } 형태로 표현한다.
**1) 분리 기반 스킴(SHTCC)**
첫 번째 내부 경계는 “Separate Hypothesis Testing and Channel Coding”(SHTCC)이라 명명한다. 이 스킴은 크게 네 단계로 구성된다.
- (i) **타입 기반 양자화·비닝**: 관측자는 자신의 샘플 Uⁿ의 타입 P_{U}를 추정하고, 사전 정의된 코드북에 따라 해당 타입을 압축한다. 압축률은 R으로 설정되며, 이는 채널 전송률과 비교된다.
- (ii) **불균등 오류 보호(UEP) 채널 코딩**: 압축된 메시지는 중요도에 따라 서로 다른 보호 수준을 부여받는다. 특히, 타입 정보를 담은 “핵심 메시지”는 높은 보호 수준을, 부수적인 비닝 인덱스는 낮은 보호 수준을 갖는다. 이를 통해 제1종 오류(αₙ)를 제한한다.
- (iii) **채널 전송 및 디코딩**: DMC P_{Y|X}를 통해 전송된 후, 의사결정자는 수신된 Yⁿ을 이용해 메시지를 복원한다. 복원 과정에서 오류가 발생하면 제2종 오류(βₙ)에 영향을 미친다.
- (iv) **가설 검정**: 복원된 타입 정보와 자신의 샘플 Vⁿ을 조합해, 로그우도비(Likelihood Ratio) 기반 검정을 수행한다.
수식적으로는 압축률 R, 타입 분포 P_{SX}, 채널 전이 확률 P_{Y|X}에 대한 상호 정보 I(X;Y|S)와 expurgated error exponent E_ex(R, P_{SX}) 등을 활용해 κ_α와 κ_β 사이의 불균형을 정량화한다. 주요 결과는 Theorem 1으로, L(κ_α) 집합에 포함되는 (ω, R, P_{SX}, θ) 파라미터가 존재하면 κ_β ≥ min{E_sp, E_ex, E_b}를 달성할 수 있음을 보인다. 여기서 E_sp는 채널 출력의 타입 기반 스펙트럼 지수, E_ex는 전형적인 expurgated 지수, E_b는 압축‑전송 간 격차에 기인한 보정항이다. 또한, 특수 경우인 “Testing Against Independence”(TAI)와 “Testing Against Dependence”(TAD) 에 대해 구체적인 식을 제시한다.
**2) 공동 코딩 스킴(JHTCC)**
두 번째 내부 경계는 “Joint Hypothesis Testing and Channel Coding”(JHTCC)이며, 하이브리드 코딩을 핵심으로 한다. 이 스킴은 전통적인 소스‑채널 분리를 포기하고, 압축과 전송을 동시에 최적화한다. 구체적인 절차는 다음과 같다.
- (i) **타입별 하이브리드 코드북 설계**: 관측자는 각 가능한 타입 P_{U}에 대해 별도의 코드북을 생성한다. 코드북은 소스 코딩(양자화)과 채널 코딩(전송) 요소를 결합한 구조이며, 각 코드워드에는 채널 입력 Xⁿ과 해당 타입에 대한 메타 정보가 동시에 포함된다.
- (ii) **채널 전송**: 관측자는 자신의 실제 타입에 맞는 코드워드를 선택해 DMC에 전송한다. 이때 채널 잡음이 발생하더라도, 코드워드 내부에 포함된 메타 정보가 복원 가능하도록 설계한다.
- (iii) **복합 디코딩**: 의사결정자는 Yⁿ을 받아, 먼저 채널 코딩 부분을 디코딩하고, 이어서 소스 코딩 부분(타입 정보)을 추정한다. 디코딩 규칙은 P_{U|W}, P_{V|W} 등 소스와 채널 통계가 결합된 로그우도비를 사용한다.
- (iv) **가설 검정**: 복원된 타입과 Vⁿ을 이용해 최적의 검정 함수를 적용한다. 여기서는 제1종 오류를 제한하는 동시에, 제2종 오류를 최소화하도록 설계된 복합 임계값을 사용한다.
JHTCC의 성능 분석은 크게 세 단계로 나뉜다. 첫 번째는 **타입 오류**(압축 단계에서 잘못된 타입을 선택할 확률)이며, 이는 KL 발산 D(P̂_U‖P_U)와 직접 연관된다. 두 번째는 **채널 오류**(UEP 없이 발생하는 오류)이며, 이는 ψ* (rate function)와 E_sp, E_ex와 유사한 형태로 표현된다. 세 번째는 **결합 오류**(소스와 채널 오류가 동시에 발생)이며, 이는 E_ex와 E_b를 동시에 포함하는 복합 항으로 나타난다. Theorem 2는 이러한 세 오류 항을 모두 고려한 최적의 κ_β 하한을 제시한다. 특히, R < ζ(κ_α, ω)인 경우에만 유효한 복합 지수 E_3가 등장한다.
**3) 비교 및 예시**
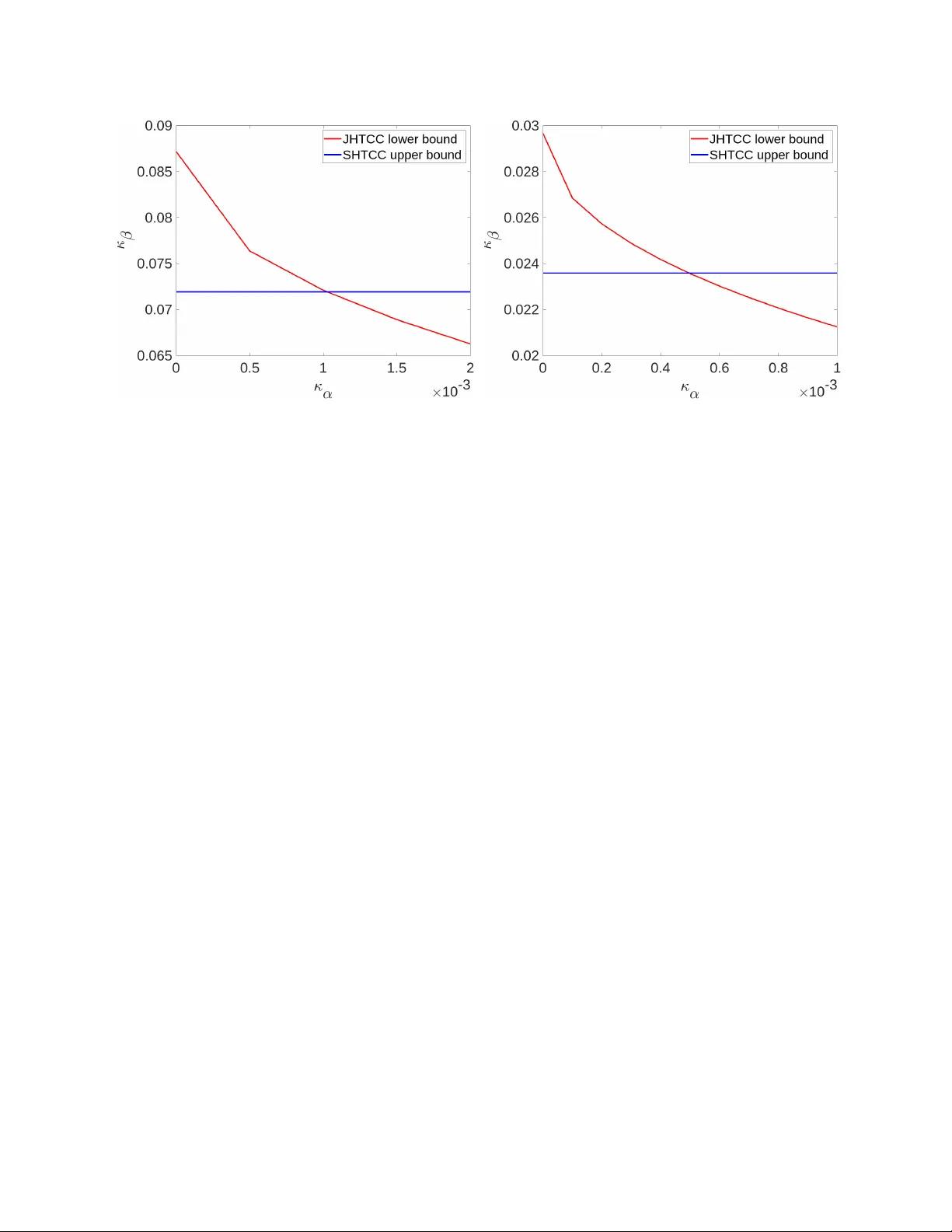
논문은 두 스킴을 수치적으로 비교한다. 예시로 이진 대칭 채널(BSC)과 특정 P_{UV}, Q_{UV} (예: TAI 상황)를 사용한다. 결과는 다음과 같다.
- SHTCC는 채널 용량이 충분히 클 때(즉, R이 채널 용량 이하) 좋은 성능을 보이지만, 채널 잡음이 심하거나 전송률 제한이 강하면 κ_β가 급격히 감소한다.
- JHTCC는 동일한 조건에서도 κ_β가 더 높은 값을 유지한다. 특히, R이 채널 용량에 근접하거나 초과하는 경우에도, 하이브리드 코딩이 타입 정보를 효과적으로 보호해 제2종 오류 지수를 크게 향상시킨다.
- 두 스킴 모두 κ_α → 0 (즉, 제1종 오류를 거의 허용하지 않을 때)에서는 기존 무노이즈 채널 결과와 일치한다는 점을 확인한다.
**4) 기존 연구와의 관계**
본 연구는 Han‑Kobayashi(1996)와 Ahlswede‑Csiszár(1986) 등 무노이즈 채널에서의 DHT 이론을 일반화한다. 또한, 이전 저자들의 “Stein exponent” 연구와 “type‑based UEP” 설계(Reference
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기