시간 영역 서브밴드 기반 음성 합성기 완전 신경망 모델
초록
본 논문은 다중 레벨 웨이블릿을 이용해 입력 음성을 여러 서브밴드로 분해한 뒤, 각 서브밴드에 경량화된 WaveNet‑유사 컨볼루션 신경망을 적용해 완전 시간 영역 텍스트‑투‑스피치(TTS) 시스템을 구현한다. 서브밴드 모델은 전체 대역 모델에 비해 파라미터 수와 연산량이 크게 감소하면서도 객관적·주관적 평가에서 우수한 성능을 보였다.
상세 분석
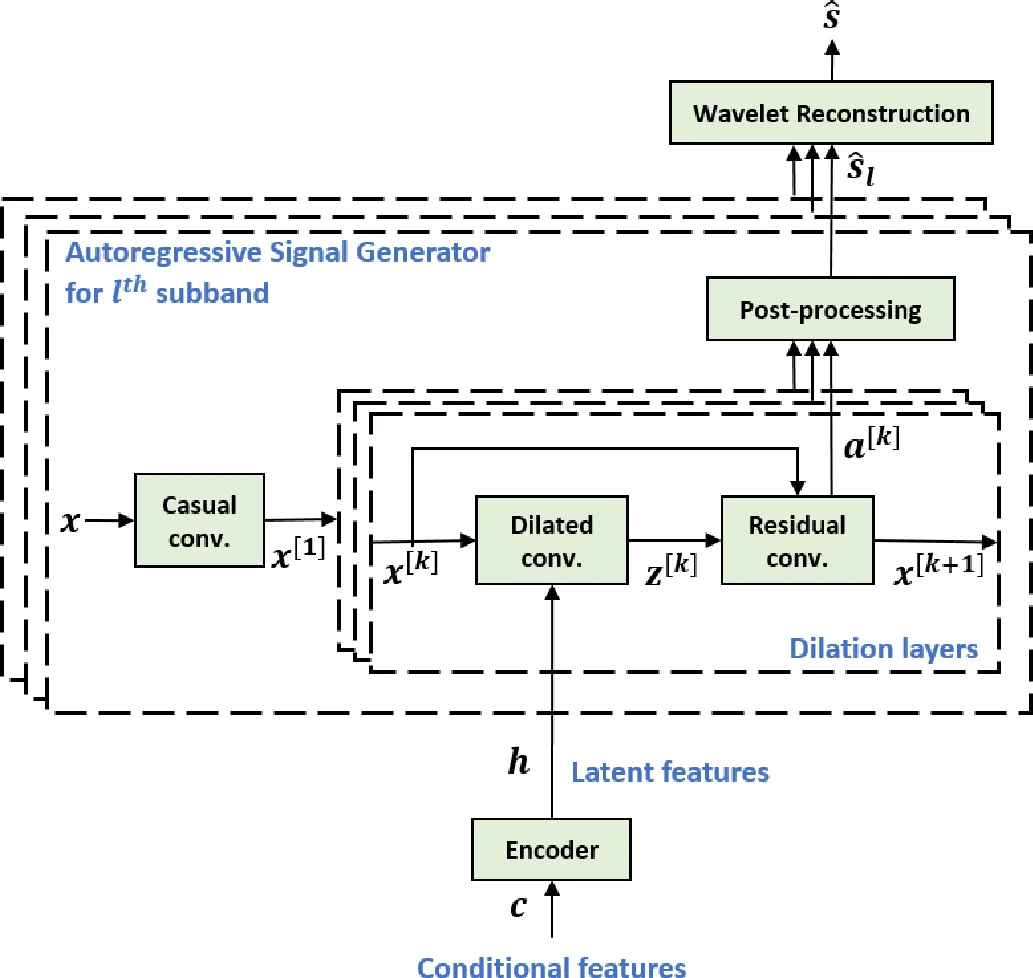
이 연구는 고해상도 16 kHz 음성 신호를 직접 모델링하는 기존 WaveNet 계열의 한계를 서브밴드 접근법으로 극복하고자 한다. 먼저, Daubechies‑db10 웨이블릿을 8단계(총 8개 서브밴드)로 적용해 저역대와 고역대를 각각 별도의 시계열로 변환한다. 다운샘플링을 의도적으로 배제함으로써 각 서브밴드의 샘플 수는 원본과 동일하게 유지되지만, 주파수 대역이 좁아져 신호의 변동성이 감소한다. 이는 작은 receptive field와 적은 층 수만으로도 효과적인 패턴 학습이 가능함을 의미한다.
각 서브밴드에 할당된 신경망은 Fast WaveNet 구조를 그대로 차용했으며, dilation 레이어 수를 전체 대역 모델의 24에서 5로 크게 축소했다. dilated convolution의 계층적 구조가 웨이블릿 변환의 다중 스케일 특성과 유사하다는 점을 이용해, 낮은 레벨(고주파)에서는 작은 dilation, 높은 레벨(저주파)에서는 큰 dilation이 자연스럽게 매핑된다. 이렇게 하면 파라미터 수가 크게 감소하면서도 각 서브밴드 고유의 스펙트럼 특성을 충분히 포착한다.
조건부 입력으로는 문자‑→음소 변환 및 강세 정보를 포함한 70차원 음소 시퀀스를 사용한다. 이 시퀀스는 3개의 1‑D 컨볼루션 레이어(필터 폭 5, 채널 256)로 구성된 인코더를 통해 잠재 특징 h 로 압축된다. 인코더는 언어적 정보를 자동으로 추출해 각 서브밴드 생성기에 전달함으로써, 별도의 음향 모델 없이도 TTS 전 과정을 하나의 통합 네트워크로 구현한다. 실험 결과, 인코더를 제외한 전체 대역 WaveNet 대비 성능 저하가 뚜렷이 나타나 인코더의 중요성이 확인되었다.
학습 손실은 모든 서브밴드에 대한 교차 엔트로피의 합으로 정의했으며, 이는 각 서브밴드가 독립적인 확률 분포를 학습하도록 유도한다. 생성 단계에서는 이전 샘플과 잠재 특징을 조건으로 하여 각 시점의 샘플을 확률적으로 추출한다. teacher‑forcing 실험에서는 실제 이전 샘플을 입력함으로써 모델이 목표 신호를 거의 완벽하게 예측했으며, SNR이 23.5 dB, SD가 4.3 dB로 전체 대역 모델(18.8 dB, 8.1 dB)보다 현저히 우수했다. 실제 합성(synthesis)에서는 조건부 특징이 음향 정보를 충분히 제공하지 못해 양쪽 모델 모두 품질이 다소 떨어졌지만, 서브밴드 모델이 여전히 비슷하거나 약간 우수한 결과를 보였다.
시간 복잡도 측면에서는 샘플‑단위 순차 생성 방식이 여전히 병목이지만, 서브밴드별 병렬 처리와 경량화된 네트워크 덕분에 전체 연산량이 크게 감소한다. 향후 연구에서는 멀티스피커, 프로소디, 노이즈 조건 등을 잠재 특징에 통합하거나, 비자율(autoregressive) 구조를 대체할 흐름 기반 모델을 도입해 실시간 합성 속도를 더욱 끌어올릴 여지가 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기