멀티GPU 딥러닝 학습을 위한 하이브리드 병렬 전략 최적화
초록
본 논문은 데이터 병렬(DP)만 사용했을 때 발생하는 통신 오버헤드와 배치 크기 증가에 따른 수렴 효율 저하 문제를 해결하기 위해, 모델 병렬(MP)을 결합한 하이브리드 병렬 방식을 제안한다. 분석 모델인 Inception‑V3, GNMT, BigLSTM에 대해 2‑way MP를 적용한 뒤 DP와 결합한 최적의 디바이스 배치를 찾는 정량적 프레임워크와 정수선형계획 기반 툴(DLPlacer)을 개발하였다. 실험 결과, 대규모 GPU 클러스터에서 하이브리드 전략이 DP 단독 대비 각각 최소 26.5 %, 8 %, 22 %의 전체 학습 시간 감소를 달성함을 보였다.
상세 분석
이 논문은 딥러닝 학습의 전체 시간 C를 단계당 평균 시간 T, 에폭당 스텝 수 S, 필요 에폭 수 E의 곱으로 정의하고, 각각을 DP와 MP 관점에서 정량화한다. DP에서는 N개의 디바이스가 동시에 미니배치를 처리하고, 이후 all‑reduce를 통해 그래디언트를 평균한다. 여기서 스케일링 효율 SE_N = T₁/T_N < 1이며, 글로벌 배치가 N배 증가함에 따라 에폭 수 E_N/E₁이 감소(즉, 더 많은 에폭 필요)한다. 따라서 DP만 사용하면 N이 커질수록 SE_N과 E₁/E_N 모두 감소해 전체 속도 향상이 포화된다.
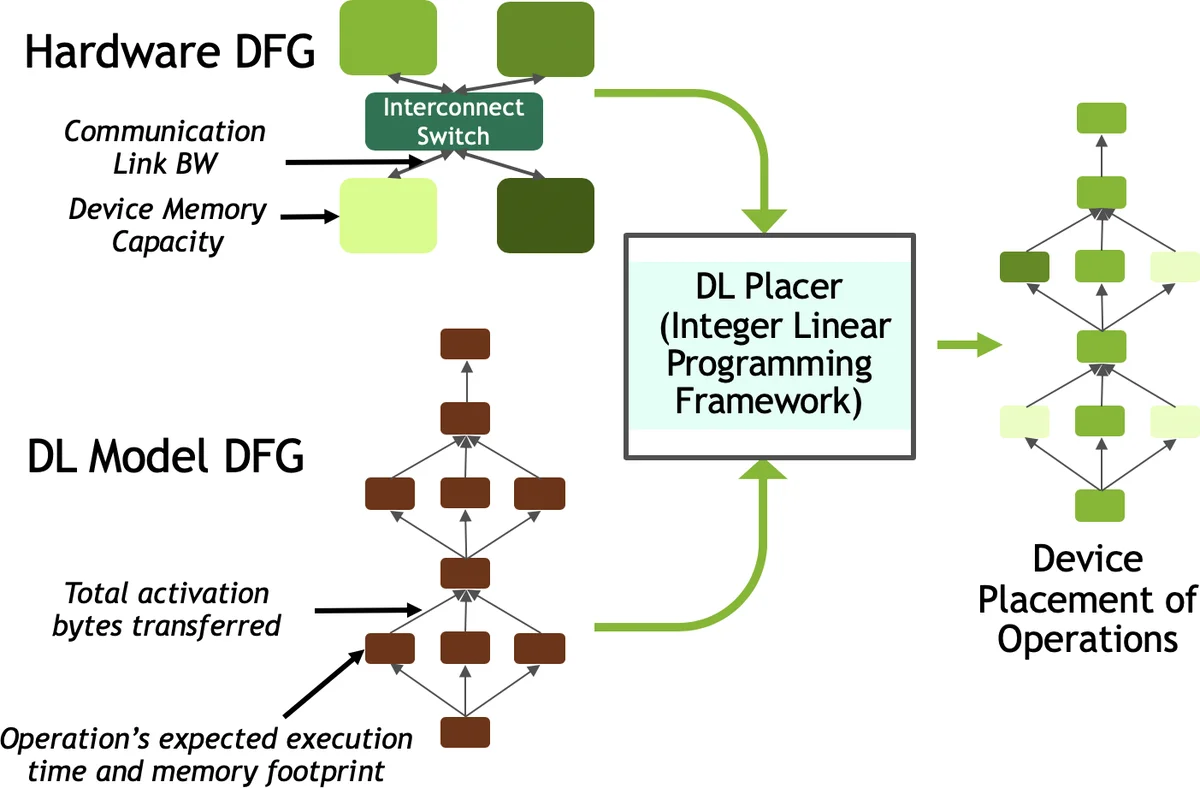
MP는 동일 미니배치를 여러 디바이스에 분할 배치함으로써 T를 직접 감소시킨다. 모델 그래프를 어떻게 분할하느냐에 따라 연산 간 데이터 이동 비용이 발생하는데, 이 비용을 최소화하면서 연산을 병렬화하는 것이 핵심이다. 논문은 이를 정수선형계획(ILP) 문제로 모델링한 DLPlacer를 제시한다. DLPlacer는 각 연산을 디바이스에 할당하고, 연산 간 통신량을 고려해 전체 실행 시간을 최소화한다. Inception‑V3에 대해 2‑GPU MP를 적용했을 때 1.32×의 속도 향상을 얻었으며, 이는 예측값과 6 % 이내의 오차를 보인다.
하이브리드 전략은 N‑way DP와 M‑way MP를 결합한다. 전체 디바이스 수를 M·N이라 할 때, 각 DP 워커는 M개의 GPU에 MP로 모델을 분할한다. 이때 글로벌 배치 크기는 DP만 사용할 때와 동일하게 유지되므로 S와 E는 변하지 않는다. 따라서 전체 속도 향상 S_U^{M,N} = S_U^M × SE_N × N × (E₁/E_N) 로 표현된다. 여기서 S_U^M는 MP에 의한 per‑step 속도 향상이다. 논문은 S_U^M > M·SE_{M·N}·(E_N/E_{M·N}) 조건을 만족하면 하이브리드가 DP 단독보다 우수함을 수식적으로 증명한다.
실험에서는 Inception‑V3, GNMT, BigLSTM 세 모델에 대해 2‑way와 4‑way MP를 구현하고, 다양한 디바이스 수(N)에서 DP와 하이브리드의 속도 곡선을 비교했다. 결과는 DP가 32 GPU까지는 비교적 선형에 가깝게 스케일링되지만, 그 이후부터는 SE_N이 급격히 감소한다. 반면 하이브리드 전략은 MP가 제공하는 S_U^M이 충분히 클 경우, 64 GPU, 128 GPU 등 더 큰 규모에서도 지속적인 속도 향상을 보였다. 특히 Inception‑V3은 2‑GPU MP에서 1.32×, 4‑GPU MP에서 1.55×의 per‑step 가속을 달성했고, 이를 DP와 결합했을 때 전체 학습 시간은 DP 단독 대비 최소 26.5 % 단축되었다. GNMT과 BigLSTM도 각각 8 %와 22 %의 절감 효과를 보이며, 모델별로 최적의 MP 수준(M)이 다름을 확인했다.
핵심 기여는 다음과 같다. (1) DP의 스케일링 한계를 정량적으로 분석하고, MP와 결합할 최적 시점을 찾아내는 이론적 프레임워크를 제시했다. (2) ILP 기반 자동 배치 툴인 DLPlacer를 개발해 실제 모델에 적용 가능한 최적의 연산‑디바이스 매핑을 제공했다. (3) 다양한 실제 모델에 대해 하이브리드 전략이 DP 단독 대비 실질적인 학습 시간 절감을 입증했다. 이 연구는 대규모 GPU 클러스터에서 효율적인 딥러닝 학습 파이프라인을 설계하고자 하는 연구자와 엔지니어에게 실용적인 가이드라인을 제공한다.
댓글 및 학술 토론
Loading comments...
의견 남기기