근사 컴퓨팅과 효율적인 머신러닝 여정
초록
본 논문은 근사 컴퓨팅(AxC)이 머신러닝(ML) 시스템의 에너지·성능 효율을 크게 향상시키는 메커니즘을 체계적으로 정리하고, 알고리즘·아키텍처·회로 수준의 대표적 기법들을 분류한다. 특히 변환기(Transformer) 모델에 적용한 인‑메모리 근사와, 배터리 구동 인쇄 전자 회로에 적용한 초저전력 ML 구현 사례를 통해 AxC가 실제 상용화 단계까지 확장될 수 있음을 보여준다.
상세 분석
논문은 먼저 근사 컴퓨팅이 왜 머신러닝과 자연스럽게 결합되는지를 이론적·실증적으로 설명한다. ML 모델은 본질적으로 함수 근사 문제이며, 학습 과정 자체가 근사 오차를 보정하는 메커니즘을 제공한다는 점이 핵심이다. 이러한 특성은 비트 폭 축소(Quantization), 가중치 가지치기(Pruning), 구조적 희소성(Sparsity) 등 다양한 근사 기법을 적용해도 정확도 손실을 최소화할 수 있게 만든다.
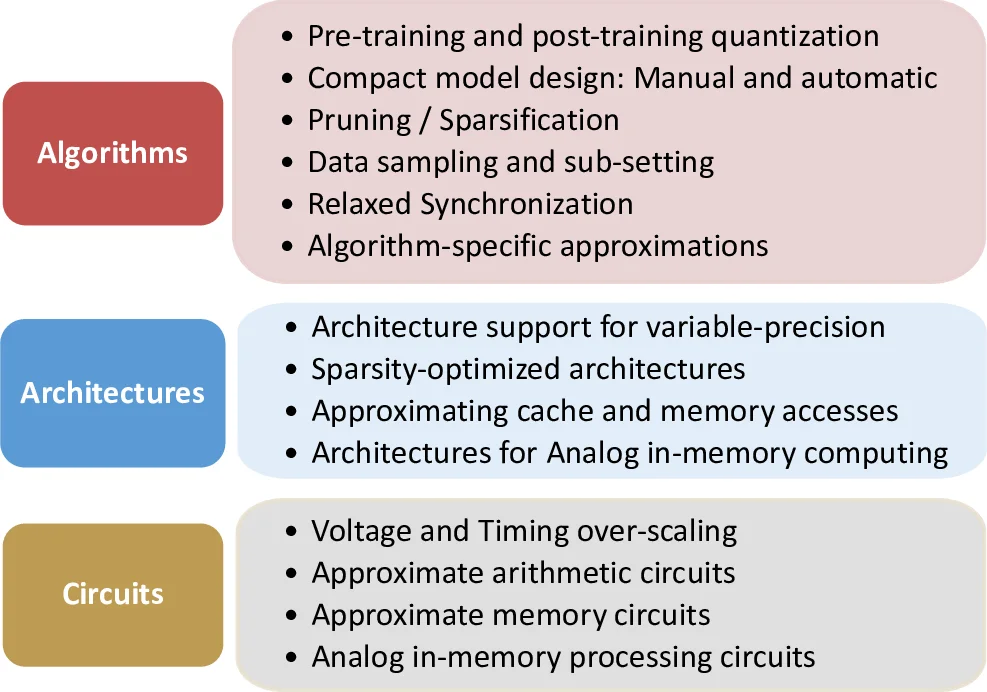
저자들은 AxC 기술을 알고리즘, 아키텍처, 회로 세 단계로 나누어 상세히 분류한다.
- 알고리즘 수준에서는 정밀도 스케일링, 자동 압축(knowledge distillation, NAS), 데이터 샘플링, 완화된 동기화 등 학습·추론 파이프라인 전체에 걸친 근사 전략을 제시한다. 특히 양자화는 FP16→FP8→INT4·INT2 순으로 진행되는 하이브리드 포맷(HFP8)과, 사후 양자화(PTQ)와 양자화 인식 학습(QAT)의 차이점을 명확히 구분한다.
- 아키텍처 수준에서는 가변 정밀도 지원, 희소성 최적화, 메모리/캐시 근사 등 하드웨어 설계 원칙을 제시한다. 가변 정밀도는 로직 공유와 파이프라인 분리 사이의 트레이드오프를 관리해야 하며, RaPiD와 같은 7 nm 멀티프리시전 가속기가 실제 구현 사례로 제시된다. 희소성 최적화는 구조적 블록 희소성(Block Sparsity)과 동적 스킵 제어를 통해 연산 효율을 높이지만, 정밀도 축소와의 상호작용이 아직 해결 과제로 남는다. 메모리 근사는 DRAM 리프레시 감소, 로드 스펙터레이션, 데이터 재사용 등으로 메모리 대역폭 병목을 완화한다.
- 회로 수준에서는 논리 근사, 타이밍 오버스케일링, 근사 메모리 설계가 논의된다. 논리 근사는 오류 허용 범위 내에서 트랜지스터 수와 전력 소비를 크게 줄이며, 타이밍 오버스케일링은 전압·주파수를 초과 동작시켜 에너지 효율을 극대화한다. 이러한 회로 기법은 상위 레이어의 근사 정책과 긴밀히 연계돼야 한다는 점을 강조한다.
두 가지 사례 연구가 논문의 핵심을 입증한다. 첫 번째는 Transformer 모델용 아날로그 인‑메모리 컴퓨팅(IMC) 가속기로, SRAM·ReRAM 기반의 아날로그 MAC 연산을 활용해 매트릭스‑곱 연산을 메모리 내부에서 수행함으로써 데이터 이동 비용을 거의 없앤다. 이 설계는 정밀도 8비트에서 4비트로 축소하면서도 BLEU 점수 손실을 0.3% 이하로 제한한다. 두 번째는 인쇄 전자(Printed Electronics) 기반 초저전력 ML 분류기이다. 저전압 트랜지스터와 근사 연산 셀을 이용해 배터리 구동 시 10 mW 이하의 전력 소모로 이미지 분류를 수행한다. 여기서는 양자화와 가지치기를 결합해 모델 파라미터를 95% 압축했으며, 정확도는 92% 수준을 유지한다.
마지막으로 논문은 현재 상용화된 CPU·GPU·TPU 제품군에 AxC 기능이 점진적으로 통합되고 있음을 언급하고, 향후 정밀도-희소성-전력 삼중 최적화, 동적 근사 제어, 보안·신뢰성 문제 해결이 연구 과제로 남아 있음을 제시한다. 전체적으로 이 논문은 근사 컴퓨팅이 머신러닝 시스템 설계 전반에 걸쳐 어떻게 적용될 수 있는지를 체계적으로 정리하고, 실제 구현 사례를 통해 그 실효성을 입증한다.
댓글 및 학술 토론
Loading comments...
의견 남기기