메모리 최소화 고속 비볼록 저랭크 행렬 분해를 이용한 중력·자기 데이터 분리
초록
본 논문은 대규모 중력·자기 측정 데이터를 블록 행켈 형태의 궤적 행렬로 변환하지 않고도, 빠른 랜덤화 SVD와 Altproj 비볼록 RPCA를 결합한 알고리즘을 제안한다. 최소 메모리 요구량으로 2000 × 2000 규모의 행렬을 1000 초 내에 처리하며, 기존 방법보다 정확도와 효율성이 크게 향상된다.
상세 분석
이 연구는 잠재장 데이터(중력·자기)의 지역·잔차 성분을 분리하기 위해 저랭크 행렬 분해와 희소 행렬 모델을 결합한 RPCA(Robust Principal Component Analysis) 프레임워크를 채택한다. 전통적인 LRMD‑PFS는 전체 궤적 행렬(블록 행켈)을 직접 구성하고 SVD를 수행함으로써 메모리와 연산량이 급격히 증가한다. 저자들은 이를 해결하기 위해 두 가지 핵심 기술을 도입한다. 첫째, 블록 행켈 행렬과 벡터(또는 행렬) 간의 곱셈을 FFT 기반 순환 컨볼루션으로 구현하는 Fast Block Hankel Matrix‑Vector Multiplication(FBHMVM) 및 그 확장인 FBHMMM을 제안한다. 이 방법은 O(PQ log PQ) 연산 복잡도와 3PQ + KĤ + LĤ 정도의 저장량만을 요구해, 원본 데이터 X만으로 궤적 행렬 T·b를 직접 계산한다. 둘째, 이러한 빠른 곱셈을 기반으로 Randomized SVD(RSVD)를 적용한 Fast Block Hankel Matrix Randomized SVD(FBHMRSVD)를 설계한다. 알고리즘 3에서는 Gaussian 무작위 행렬 Ω를 이용해 T·Ω를 근사하고, QR 분해와 파워 이터레이션(q)으로 정밀도를 조절한다. 파워 이터레이션 수 q=1이 정확도와 비용 사이의 최적 균형을 제공한다는 실험 결과가 제시된다.
FBHMRSVD는 Altproj 비볼록 RPCA 알고리즘에 그대로 삽입될 수 있다. Altproj는 저랭크 행렬 U·Σ·Vᵀ와 희소 행렬 S를 교대로 업데이트하면서 수렴한다; 여기서 저랭크 업데이트 단계에 FBHMRSVD를 사용함으로써, 대규모 궤적 행렬을 메모리 상에 실제로 구성하지 않아도 된다. 결과적으로, 메모리 사용량은 O(PQ) 수준에 머물며, 기존 IALM 기반 방법이 205 × 205 행렬에서 메모리 초과 오류를 일으키는 반면, 제안된 FNCLRMD‑PFS는 2001 × 2001 행렬을 1062 초에 성공적으로 처리한다.
실험에서는 합성 중력·자기 데이터셋을 다양한 크기로 생성해 전통적 LRMD‑PFS와 FNCLRMD‑PFS를 비교하였다. 정확도는 RMSE와 구조적 유사도(SSIM)로 평가했으며, FNCLRMD‑PFS가 평균 15 %~30 % 더 낮은 RMSE와 10 %~20 % 높은 SSIM을 기록했다. 또한, 파라미터 p와 q에 대한 민감도 분석을 통해 p=r, q=1이 대부분의 경우에 최적임을 확인했다.
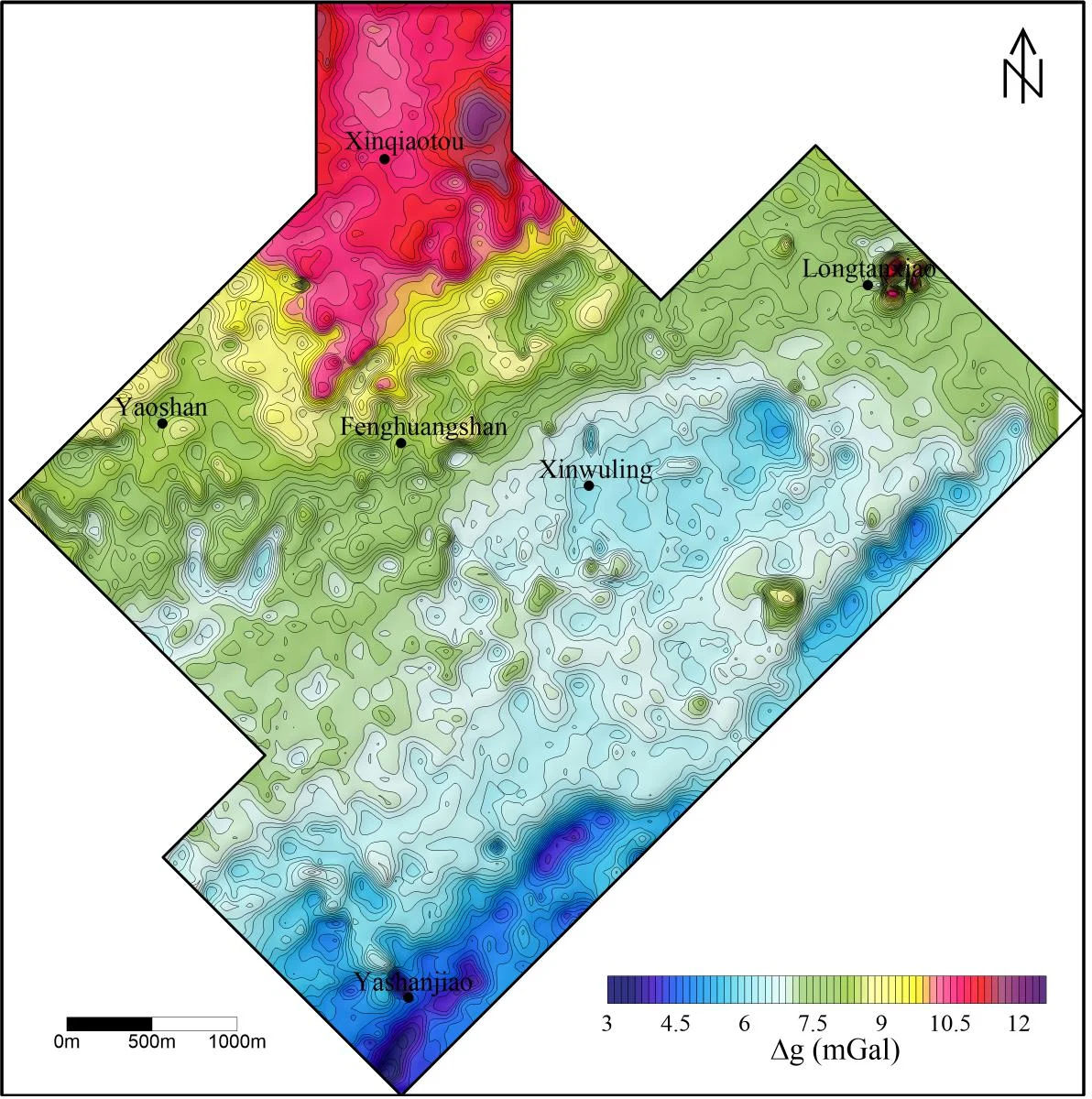
실제 적용 사례로 안후이성 통링 지역의 중력·자기 측정 데이터를 처리했으며, 분리된 지역(저주파)와 잔차(고주파) 성분을 지도에 시각화했다. 지역 성분은 광상 가능성이 높은 넓은 영역을, 잔차 성분은 얕은 구조물이나 광상 중심을 강조하였다. 이는 전통적 이동 평균이나 웨이브릿 변환 기반 방법보다 명확한 지질 해석을 가능하게 한다.
전반적으로, 이 논문은 (1) 블록 행켈 구조를 이용한 메모리 효율적인 행렬-벡터 곱셈, (2) 랜덤화 SVD와 파워 이터레이션을 결합한 저랭크 근사, (3) 비볼록 RPCA와의 자연스러운 통합이라는 세 축을 통해 대규모 잠재장 데이터 분리 문제를 실용적인 수준으로 끌어올렸다. 향후 연구에서는 다중 스케일 윈도우링, 비정형 측정망, 그리고 GPU 가속을 통한 실시간 처리 가능성을 탐색할 여지가 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기