다중코어·클러스터와 GPU를 활용한 딥러플 GP 방정식 솔버 최신 버전
초록
**
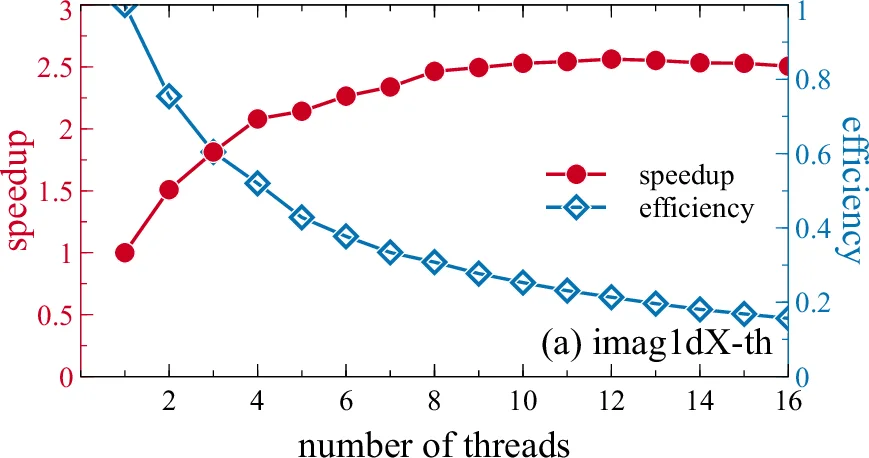
본 논문은 1·2·3 차원에서 딥러플 보스-아인슈타인 응축을 기술하는 시간‑의존성 Gross‑Pitaevskii 방정식을 풀기 위한 C와 CUDA 프로그램을 OpenMP, OpenMP/MPI, CUDA/MPI 형태로 재구성·병렬화한 최신 버전을 소개한다. 순차 버전 대비 1.1∼1.9배, OpenMP 단일 노드에서 2∼12배, OpenMP/MPI 클러스터(32노드)에서 11.5∼16.5배, CUDA/MPI 클러스터에서 9∼10배의 속도 향상을 보고한다.
**
상세 분석
**
이 연구는 기존에 순차적으로 구현된 Gross‑Pitaevskii(GP) 방정식 솔버를 현대 고성능 컴퓨팅 환경에 맞게 재설계한 점이 가장 큰 특징이다. 첫 번째 패키지인 DBEC‑GP‑OMP는 기존 C 코드에 OpenMP 지시문을 삽입해 멀티코어 CPU에서 스레드 수준의 병렬성을 확보한다. 특히 실‑복소 변환(R2C) FFT를 활용해 메모리 사용량을 절반으로 줄이고, FFTW3 라이브러리의 OpenMP 지원을 그대로 이용함으로써 구현 복잡도를 최소화하였다. 두 번째 패키지인 DBEC‑GP‑MPI는 OpenMP‑병렬화된 코드를 기반으로 3차원 문제에 대해 슬랩(1차원) 도메인 분할을 적용한다. 각 MPI 프로세스는 전체 NX 축을 나누어 할당받고, NY·NZ 축은 로컬에 완전히 보관한다는 설계는 데이터 이동을 최소화하고, 필요 시 전치(transpose) 연산을 통해 전체 축에 대한 연산을 수행한다. 전치 구현에 FFTW3의 전용 인터페이스를 활용해 통신 오버헤드를 낮추었다. 세 번째 패키지인 DBEC‑GP‑MPI‑CUDA는 CUDA 기반 3차원 솔버에 동일한 도메인 분할 전략을 적용했으며, cuFFT가 MPI 전용 인터페이스를 제공하지 않으므로 사용자 정의 MPI 데이터 타입과 All‑to‑All 통신을 이용해 전치를 직접 구현하였다. 이때 행‑열(또는 행‑열‑면) FFT 알고리즘을 사용해 로컬 GPU에서 1차원 FFT를 수행하고, 전치 후 다른 축에 대해 다시 FFT를 수행한다는 전형적인 3‑D FFT 파이프라인을 그대로 유지한다.
성능 평가에서는 파라다악스 슈퍼컴퓨터의 16코어 Xeon 노드와 Tesla M2090 GPU를 이용해 강력한 스케일링을 확인했다. OpenMP 버전은 1‑D 문제에서 스레드 수가 증가함에 따라 효율이 급격히 떨어지는 반면, 2‑D·3‑D 문제는 8~16 스레드에서 70 % 이상 효율을 유지한다. MPI 기반 버전은 슬랩 분할과 전치 비용을 고려한 강한 스케일링 실험에서 32노드(총 512코어) 사용 시 11.5∼16.5배, CUDA/MPI 버전은 GPU당 1프로세스·다중 GPU 구성을 전제로 9∼10배의 가속을 달성했다. 또한, 메모리 사용량을 절반으로 줄인 R2C FFT와 포인터 별칭을 통한 메모리 재활용이 전체 실행 시간 단축에 크게 기여했음이 확인되었다.
이 논문은 GP 방정식과 같은 비선형 파셜 미분 방정식의 고성능 시뮬레이션에 있어, CPU‑멀티코어, 분산 메모리 클러스터, 그리고 GPU를 각각 혹은 혼합해 활용할 수 있는 포괄적인 솔루션을 제공한다는 점에서 실험실 수준의 연구뿐 아니라 대규모 파라미터 탐색이나 고해상도 3‑D 시뮬레이션에도 바로 적용 가능하다. 또한, 오픈소스(Apache 2.0) 라이선스로 배포되어 커뮤니티가 자유롭게 확장·수정할 수 있다는 장점도 갖는다.
**
댓글 및 학술 토론
Loading comments...
의견 남기기