CUDA 프로그램을 이용한 비등방성 트랩에서 시간 의존성 쌍극자 Gross‑Pitaevskii 방정식 해결
초록
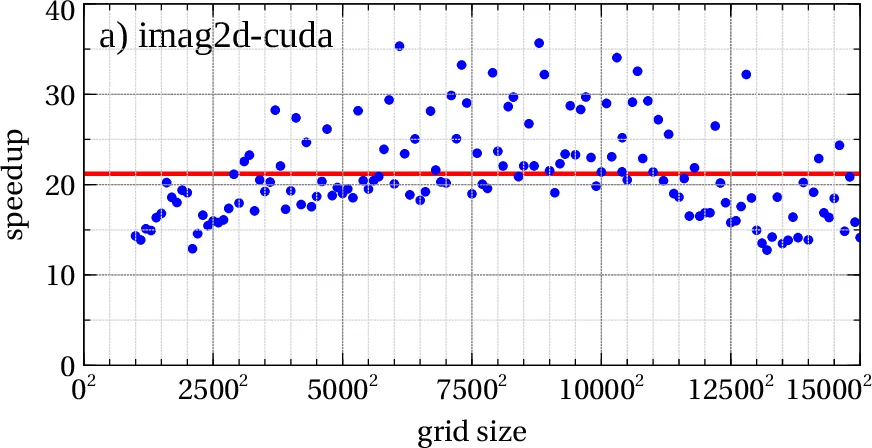
본 논문은 2차원·3차원 비등방성 조화 트랩 안에서 접촉 및 쌍극자 상호작용을 포함한 Gross‑Pitaevskii 방정식을 CUDA 기반 GPU에서 풀기 위한 프로그램을 소개한다. 기존 CPU 전용 코드와 동일한 분할‑단계 Crank‑Nicolson 스킴을 유지하면서, FFT 연산을 cuFFT 라이브러리로 교체하고 핵심 연산을 CUDA 커널로 구현해 평균 12배에서 25배까지 속도 향상을 달성하였다. 메모리 사용 최적화를 위한 POTMEM 옵션과 재사용 텐서 전략도 상세히 설명한다.
상세 분석
이 연구는 초저온 원자 물리학에서 널리 사용되는 비선형 파셜 미분 방정식인 Gross‑Pitaevskii(GP) 방정식의 쌍극자 상호작용 포함 형태를 고성능 GPU로 가속화하는 데 초점을 맞춘다. 기존에 발표된 Fortran·C 기반 CPU 프로그램은 FFTW를 이용해 푸리에 변환을 수행했으며, 계산량이 급증하는 3차원 문제에서는 실시간 시뮬레이션이 사실상 불가능했다. 저자들은 동일한 수치 스킴—시간을 작은 스텝으로 나누고 공간을 격자화한 후, 비선형 항을 실시간(실제 시간) 혹은 허수 시간(정상상태 탐색)으로 전파하는 split‑step Crank‑Nicolson 방법—을 유지하면서, 모든 연산을 CUDA 커널로 옮겼다.
핵심적인 최적화는 다음과 같다. 첫째, FFT 연산을 cuFFT로 교체함으로써 GPU 메모리 내에서 직접 복소‑실수 변환을 수행하고, Hermitian 대칭성을 활용해 메모리 요구량을 절감하였다. 둘째, 계산에 가장 많이 사용되는 함수들(calcpsidd2, calcnu, calclux 등)을 그리드‑스트라이드 루프 형태의 CUDA 커널로 구현해 블록 크기를 유연하게 조정할 수 있게 했다. 셋째, 재귀 관계가 있는 Crank‑Nicolson 계수 계산을 외부 루프 수준에서 병렬화하고, 내부 루프는 각 스레드가 독립적으로 수행하도록 설계했다. 이를 위해 임시 텐서를 재사용하고, POTMEM 파라미터를 통해 트랩 및 쌍극자 포텐셜을 GPU 메모리 혹은 CPU 메모리에서 직접 접근하도록 선택할 수 있게 했다. POTMEM=2는 두 개의 전용 텐서를 할당해 최고 성능을 제공하지만 메모리 사용량이 가장 크고, POTMEM=0은 포텐셜을 CPU 메모리에서 PCI‑Express를 통해 읽어들여 메모리 제한을 회피한다.
성능 평가에서는 Tesla M2090(6 GB) GPU와 Intel Xeon E5‑2670 CPU를 사용해 2D·3D 각 프로그램의 실행 시간을 측정했다. 결과는 격자 크기가 커질수록 cuFFT와 CUDA의 효율이 극대화되어 12배~25배의 속도 향상을 보였다. 특히 3D 경우, 600³ 격자까지 GPU 메모리에 적재 가능했으며, 실시간(실제 시간) 전파 프로그램은 수십 분 내에 수렴한다.
제한점으로는 Compute Capability 2.0 이상을 요구하고, GPU 메모리가 제한적일 경우 입력 격자 크기를 조정하거나 POTMEM 옵션을 낮춰야 한다는 점이다. 또한, 내부 재귀 루프를 완전하게 병렬화하지 못해 매우 큰 격자에서는 스레드 런치 오버헤드가 상대적으로 커질 수 있다. 그럼에도 불구하고, 저자들은 메모리 재사용 전략과 cuFFT 활용을 통해 기존 CPU 코드 대비 실용적인 가속을 달성했으며, 향후 더 높은 Compute Capability와 대용량 GPU가 보급되면 추가적인 성능 향상이 기대된다.
댓글 및 학술 토론
Loading comments...
의견 남기기