실제 PIM 시스템에서 머신러닝 학습 가속화 실험 평가
초록
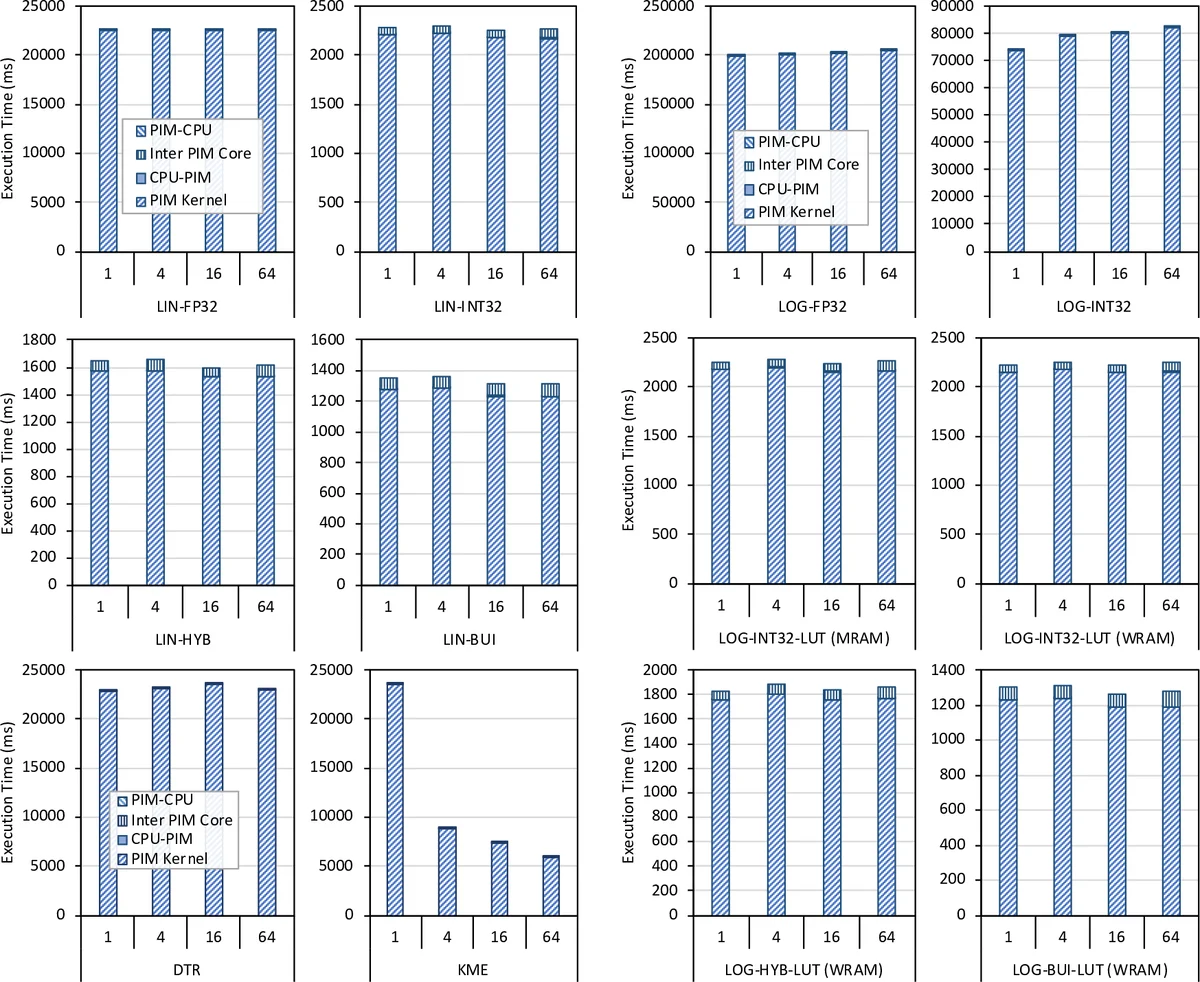
본 논문은 상용 PIM 아키텍처인 UPMEM을 이용해 선형 회귀, 로지스틱 회귀, 의사결정 트리, K‑Means 네 가지 고전 ML 알고리즘을 구현하고, CPU·GPU 대비 성능·정확도·확장성을 정량적으로 평가한다. 고정소수점·양자화·루크업 테이블 등 최적화를 적용한 결과, 의사결정 트리는 CPU 대비 최대 113배, GPU 대비 4.5배, K‑Means는 각각 2.8배·3.2배 향상을 보였다. 메모리‑바운드 워크로드는 PIM의 대용량 대역폭과 낮은 레이턴시를 활용해 크게 이득을 얻으며, 데이터 이동 비용을 최소화하는 설계 원칙을 제시한다.
상세 분석
이 연구는 현재 상용화된 일반‑목적 PIM 플랫폼인 UPMEM DIMM을 실험 베드로 삼아, 메모리‑바운드 특성을 가진 고전 머신러닝 학습 알고리즘을 직접 포팅하고 벤치마크한다는 점에서 의미가 크다. 먼저 저자들은 2,524개의 425 MHz 코어와 158 GB DRAM을 갖춘 시스템을 구축하고, 각 알고리즘에 대해 (1) 고정소수점 데이터 타입 전환, (2) 양자화 기법 적용, (3) 복잡 연산(예: 시그모이드) 대신 LUT 기반 구현 등 PIM 하드웨어의 제한을 보완하는 최적화 전략을 설계했다. 특히 의사결정 트리와 K‑Means는 반복적인 데이터 스캔과 비교 연산이 주를 이루어 메모리 대역폭에 크게 의존하는데, PIM 코어가 메모리 뱅크에 인접해 있어 스트리밍 접근이 자연스럽게 이루어졌다. 결과적으로 의사결정 트리 구현은 8‑코어 Xeon 대비 27×~113×, NVIDIA A100 대비 1.34×~4.5×의 속도 향상을 기록했으며, K‑Means는 CPU 대비 2.8×, GPU 대비 3.2×의 가속을 달성했다. 정확도 측면에서는 고정소수점·양자화에도 불구하고 원본 32‑bit 부동소수점 구현과 통계적으로 유의미한 차이가 없었으며, 이는 메모리‑중심 연산에서 정밀도 손실이 크게 영향을 미치지 않음을 시사한다. 확장성 실험에서는 PIM 코어 수와 메모리 용량을 늘릴수록 성능이 거의 선형적으로 증가했으며, 호스트와의 중간 결과 교환 비용은 전체 실행 시간의 5 % 이하에 머물렀다. 논문은 또한 PIM 설계 시 데이터 레이아웃을 스트리밍 친화적으로 배치하고, 연산이 제한적인 경우 LUT를 활용하는 것이 실용적임을 강조한다. 이러한 관찰은 향후 PIM 하드웨어가 부동소수점 연산을 네이티브로 지원하거나 SIMD 유닛을 확대할 경우, 더 넓은 범위의 머신러닝 워크로드(예: 선형 회귀·로지스틱 회귀)의 가속 효과가 기대된다는 점을 암시한다. 전체적으로 이 연구는 “메모리‑바운드”라는 정의에 기반해 워크로드를 선정하고, 실제 하드웨어에서 정량적 비교를 수행함으로써 PIM이 CPU·GPU 대비 실질적인 이점을 제공할 수 있음을 입증한다.
댓글 및 학술 토론
Loading comments...
의견 남기기