샤플리값 설명 알고리즘 종합 분석
초록
본 논문은 샤플리값 기반 특성 기여도 추정 방법을 “특성 제거 방식”과 “추정 전략” 두 축으로 분류하고, 24가지 알고리즘을 체계적으로 비교·정리한다. 모델-불가지론적 근사와 모델-특정 근사의 차이를 실험적으로 검증하고, 각 방법의 가정과 한계를 제시한다.
상세 분석
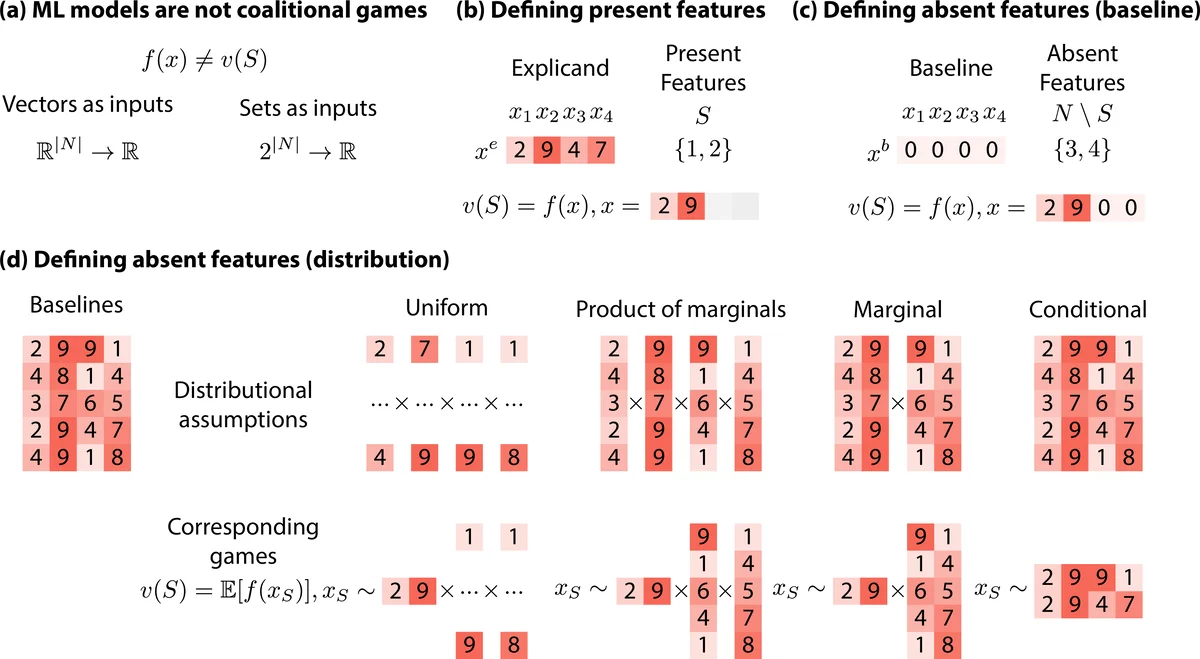
샤플리값은 게임 이론에서 정의된 공정한 기여도 할당 방법으로, 머신러닝 모델의 특성 기여도를 설명하는 데 널리 사용된다. 그러나 모델에 직접 적용하려면 (1) “특성이 없을 때”를 어떻게 정의하느냐, 즉 특성 제거 방식을 선택해야 하고, (2) 전체 특성 집합에 대해 샤플리값을 정확히 계산하는 것이 NP‑hard이므로 근사 추정 전략을 채택해야 한다는 두 가지 근본적인 난제가 존재한다. 논문은 이러한 두 축을 기준으로 기존 연구를 24개의 알고리즘으로 재분류한다. 특성 제거 방식은 크게(가) 베이스라인 대체, (나) 다중 베이스라인(분포 기반), (다) 조건부 기대값 등으로 나뉘며, 각각이 모델의 입력 공간을 어떻게 보존하거나 왜곡하는지에 따라 기여도 해석이 달라진다. 특히 베이스라인 선택이 임의적일 경우 해석의 일관성이 크게 손상될 수 있음을 실험을 통해 보여준다.
추정 전략은 모델‑불가지론적 접근과 모델‑특정 접근으로 구분한다. 모델‑불가지론적 방법은 KernelSHAP, Permutation, FastSHAP 등 샘플링 기반의 가중 회귀 혹은 마르코프 체인 몬테카를로 기법을 활용한다. 이들 방법은 다양한 수학적 정의(예: 베르누이 샘플링, 다중선형 연장)와 동등함을 증명했으며, 수렴 속도와 분산을 비교하였다. 반면 모델‑특정 방법은 선형 모델, 트리 기반 모델, 딥러닝 모델 각각에 특화된 구조적 가정을 이용한다. LinearSHAP은 계수 자체를 샤플리값으로 해석하고, TreeSHAP은 트리 경로를 이용해 정확히 O(td) 시간에 계산한다. DeepSHAP은 DeepLIFT과 연결하여 근사값을 제공하지만, 비선형 상호작용을 완전히 포착하지 못한다는 한계가 있다.
논문은 또한 현재 연구의 빈틈을 지적한다. 첫째, 베이스라인 선택에 대한 체계적인 가이드라인이 부족하고, 둘째, 고차원 상호작용을 효율적으로 추정하는 방법이 미비하며, 셋째, 모델‑불가지론적 방법의 샘플 효율성을 개선할 필요가 있다. 이러한 점들을 바탕으로 향후 연구는 베이스라인 자동화, 상호작용 탐지를 위한 샤플리값 확장, 그리고 하이브리드(불가지론 + 특정) 접근법 개발을 제안한다.
댓글 및 학술 토론
Loading comments...
의견 남기기