비선형 음향 전처리와 자기 나노진동기 기반 저장소 컴퓨팅의 음성 인식 기여 분석
초록
본 논문은 음성 인식에서 사용되는 네 가지 주파수 변환 방법(코클레아그램, MFCC, 선형 스펙트로그램, 비선형 스펙트로그램 HP)의 비선형성 정도가 인식 성공률에 미치는 영향을 정량화한다. 비선형 변환만으로도 높은 인식률을 달성할 수 있음을 보이며, 자기 나노진동기를 이용한 저장소 컴퓨팅(Reservoir Computing) 하드웨어는 주로 선형 변환에 대한 성능 향상에 크게 기여한다는 결론을 제시한다.
상세 분석
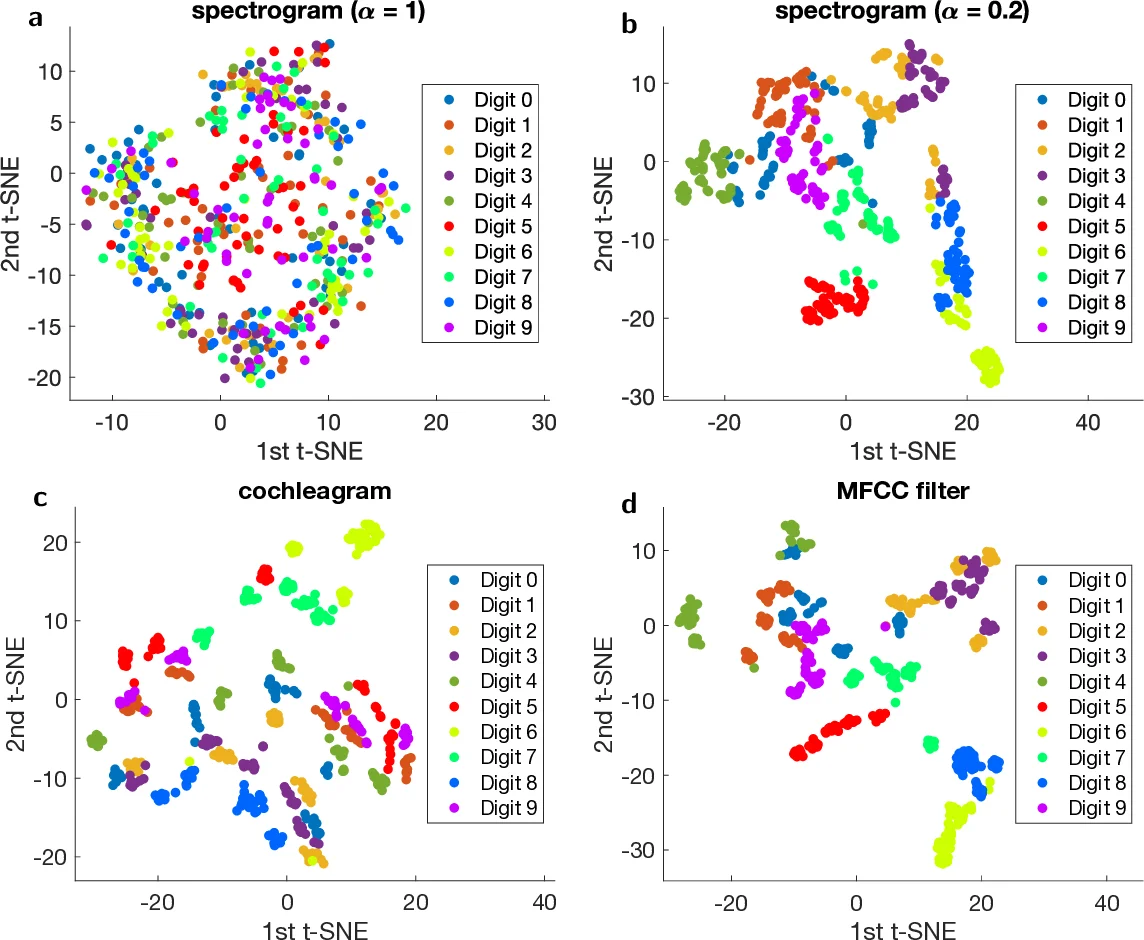
이 연구는 음성 인식 성능을 두 단계로 분리하여 평가한다. 첫 번째 단계는 입력 음성을 시간‑주파수 영역으로 변환하는 전처리 과정이며, 여기서는 코클레아그램, MFCC, 선형 스펙트로그램, 그리고 비선형 스펙트로그램 HP 네 가지 필터를 사용한다. 코클레아그램과 MFCC는 각각 자동 이득 제어와 로그‑에너지 변환이라는 비선형 요소를 포함하고 있어, 별도의 신경망 없이도 95.8 %와 77.2 %의 단어 성공률(Word Success Rate, WSR)을 달성한다. 반면 순수 선형 스펙트로그램은 무작위 추측 수준인 10 %에 머물러 비선형성이 없을 경우 데이터 구분 능력이 현저히 떨어짐을 보여준다. 비선형 스펙트로그램 HP는 |sin p|·Re + |cos p|·Im 형태의 비선형 변환을 적용해 89 %의 WSR을 얻으며, 비선형성 자체가 특징 추출에 결정적임을 입증한다.
두 번째 단계에서는 자기 나노진동기 기반 단일 동적 노드를 시간‑다중화하여 400개의 가상 뉴런으로 구성된 저장소(Reservoir)를 구현한다. 입력은 무작위 이진 마스크와 곱해진 후 STNO(Spin‑Torque Nano‑Oscillator)의 비선형 동역학을 통과한다. 출력 가중치는 Moore‑Penrose 의사역을 이용한 선형 회귀로 학습되며, 정규화는 적용되지 않는다. 실험 결과, 선형 스펙트로그램에 저장소를 결합했을 때 WSR이 10 %에서 약 88 %로 급격히 상승한다. 이는 저장소가 제공하는 비선형 동적 변환이 선형 전처리의 한계를 보완한다는 의미다. 반면 코클레아그램이나 MFCC와 같은 이미 강력한 비선형 전처리에서는 저장소가 추가하는 성능 향상이 1~2 % 수준에 그쳐, 전처리 자체가 데이터 구분을 거의 완전히 수행함을 보여준다.
또한, 저자들은 동일한 파라미터를 사용한 수치 시뮬레이션과 실제 자기 나노진동기 실험을 비교했으며, 두 결과가 매우 일치함을 확인한다. 이는 STNO 기반 저장소가 실제 하드웨어 구현에서도 이론적 기대치를 충족한다는 중요한 증거다. 전체적으로 논문은 “비선형 전처리와 저장소의 비선형 동적 변환이 서로 보완적이지만, 전처리의 비선형 강도가 충분히 클 경우 저장소의 기여는 제한적이다”는 핵심 메시지를 제시한다. 이러한 정량적 분석은 향후 neuromorphic 하드웨어를 평가할 때 전처리 단계와 하드웨어 단계의 각각의 역할을 명확히 구분하는 기준을 제공한다.
댓글 및 학술 토론
Loading comments...
의견 남기기