효율적·신뢰성 높은 디지털 보존 전략을 위한 대규모 계층형 이산 이벤트 시뮬레이션 모델
초록
본 논문은 디지털 컬렉션의 비트‑레벨 무결성을 장기적으로 유지하기 위해, 저장 하드웨어·환경·기관·전역 네 가지 위험 계층을 계층형 확률 모델로 정량화하고, 이를 이산 이벤트 시뮬레이션으로 구현한다. 비용·예산 제약 하에 손실 기대값을 최소화하는 최적 정책을 탐색하며, 다중 복제·정기 감사·복구 빈도 조절이 다양한 오류·충격 시나리오에 대해 강인한 보존 효과를 제공함을 실증한다.
상세 분석
이 연구는 디지털 보존 정책 설계에 수학적 최적화와 대규모 시뮬레이션을 결합한 독창적인 프레임워크를 제시한다. 먼저, 보존 목표를 “예산 제약 하에 기대 손실 최소화”라는 목적함수로 공식화하고, 정책 변수(복제 수, 감사 주기, 압축·암호화 여부 등)를 정의한다. 위험 모델은 네 단계로 계층화된다: (1) 디스크 섹터 오류 – 포아송 프로세스로 모델링된 미세 오류; (2) 환경 글리치 – 오류율을 일시적으로 상승시키는 포아송·지속시간 혼합; (3) 서버 실패 – 지수분포를 따르는 개별 기관의 수명; (4) 대규모 충격 – 복수 서버를 동시에 파괴하거나 서버 실패율을 급증시키는 포아송 사건. 각 계층은 가시성(감지 가능 여부)과 분포 형태를 명시해 시뮬레이션에서 자동 감지·복구 로직을 적용한다.
시뮬레이션 엔진은 계층형 이산 이벤트 구조를 채택해, 수백만 건의 복제·감사·복구 이벤트를 시간 순서대로 처리한다. 모델 파라미터는 실제 하드웨어 오류 통계(예: Pinheiro et al., 2007)와 기업 수명 데이터(예: 시장 조사 보고서)를 기반으로 캘리브레이션되었으며, 민감도 분석을 통해 정책 변수의 영향력을 정량화한다.
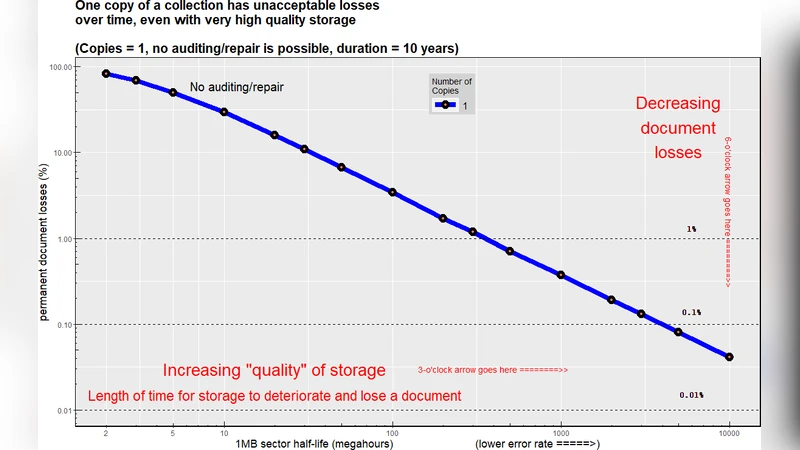
핵심 실험 결과는 다음과 같다. 첫째, 단일 복제는 저장 매체 품질이 매우 높아도 10년 이내에 상당한 문서 손실을 초래한다. 둘째, 복제 수를 35개로 늘리고 정기적인 감사·복구를 도입하면, 섹터 오류율이 10배 상승하는 극단 상황에서도 손실 확률이 0.01 % 이하로 감소한다. 셋째, 서버 수명이 평균 5년인 환경에서도 연간 1 % 수준의 서버 실패율을 가정하면, 복제와 감사 빈도를 적절히 조정하면 전체 컬렉션의 손실 위험을 0.1 % 미만으로 억제할 수 있다. 넷째, 경제 침체·전쟁·정부 검열 등 대규모 충격이 동시에 23개의 서버를 파괴하더라도, 감사 주기를 월 1회에서 주 1회로 단축하고 복제 수를 6~8개로 확대하면 손실 위험이 크게 증가하지 않는다.
이러한 결과는 “복제 수만 늘리면 충분하다”는 기존의 직관을 부정하고, 복제·감사·복구의 상호작용을 정량적으로 평가해야 함을 강조한다. 또한, 위험 계층을 명시적으로 모델링함으로써 정책 입안자는 특정 위협(예: 환경 글리치)이나 비용 구조(예: 클라우드 스토리지 월별 요금)에 맞춰 맞춤형 전략을 설계할 수 있다. 프레임워크는 오픈소스(https://github.com/MIT-Informatics/PreservationSimulation)로 제공되며, 클라우드 환경에서 손쉽게 확장·재현 가능하도록 설계돼 실무자와 연구자 모두가 활용할 수 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기