집중 주성분 분석으로 확률 모델 시각화
초록
본 논문은 복제 이론을 이용해 고차원 확률 모델의 거리 척도를 재정의하고, 이를 기반으로 새로운 비선형 차원 축소 기법인 집중 주성분 분석(InPCA)을 제안한다. 제로 복제 한계에서 얻은 ‘집중 거리’는 피셔 정보 계량과 동등하며, 고차원에서 거리의 상대 대비 손실을 극복한다. Ising 모델, 신경망, ΛCDM 우주론 모델에 적용해 기존 t‑SNE·Diffusion Maps·UMAP보다 전역 구조와 지역 구조를 동시에 잘 보존하는 시각화를 보여준다.
상세 분석
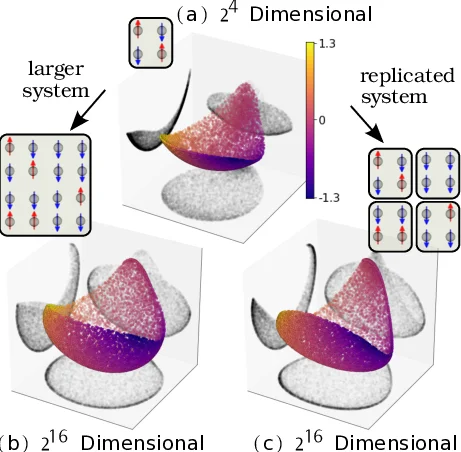
논문은 먼저 확률 모델 (L(x|\theta))의 전체 예측 집합을 ‘모델 매니폴드’라 정의하고, 전통적인 구면 임베딩 (z_x(\theta)=\sqrt{L(x|\theta)})을 통해 힐링거 거리 (d^2=8\bigl(1-\langle L(\cdot|\theta_1),L(\cdot|\theta_2)\rangle\bigr))를 도입한다. 이 거리와 피셔 정보 계량이 일치함을 보이며, 구면 임베딩이 로컬 구조를 보존한다는 점을 확인한다. 그러나 차원이 커질수록 모든 점이 구면 위에서 거의 동일한 거리(≈√8)로 수렴해 시각화가 불가능해지는 ‘거리 집중 현상’이 발생한다.
이를 해결하기 위해 복제 이론을 차용한다. 복제 수 (N)개의 독립 샘플을 곱한 전체 likelihood을 고려하면 거리 per replica는 (d^2_N = -8\frac{\log\langle L(\cdot|\theta_1),L(\cdot|\theta_2)\rangle}{N})가 된다. 여기서 복제 수를 0으로 보내는 한계를 취하면
\
댓글 및 학술 토론
Loading comments...
의견 남기기