컴퓨터 그래픽스에서 성과 젠더의 편향 분석
초록
본 논문은 SIGGRAPH 2015년 이후 발표된 논문들을 조사해 컴퓨터 그래픽스 분야에서 성(sex)과 젠더(gender)가 어떻게 이진적 개념으로 사용되는지를 밝힌다. 데이터셋, 사용자 연구, 알고리즘 설계 전 단계에서 나타나는 대표성·측정·생략·평가·배포 편향을 알고리즘 공정성 프레임워크에 따라 분석하고, 이러한 편향이 실제 서비스에서 성소수자에게 미치는 위험을 제시한다. 저자들은 보다 포괄적이고 자기보고식 성·젠더 표기를 도입하고, 편향을 명시·완화하는 연구 관행을 권고한다.
상세 분석
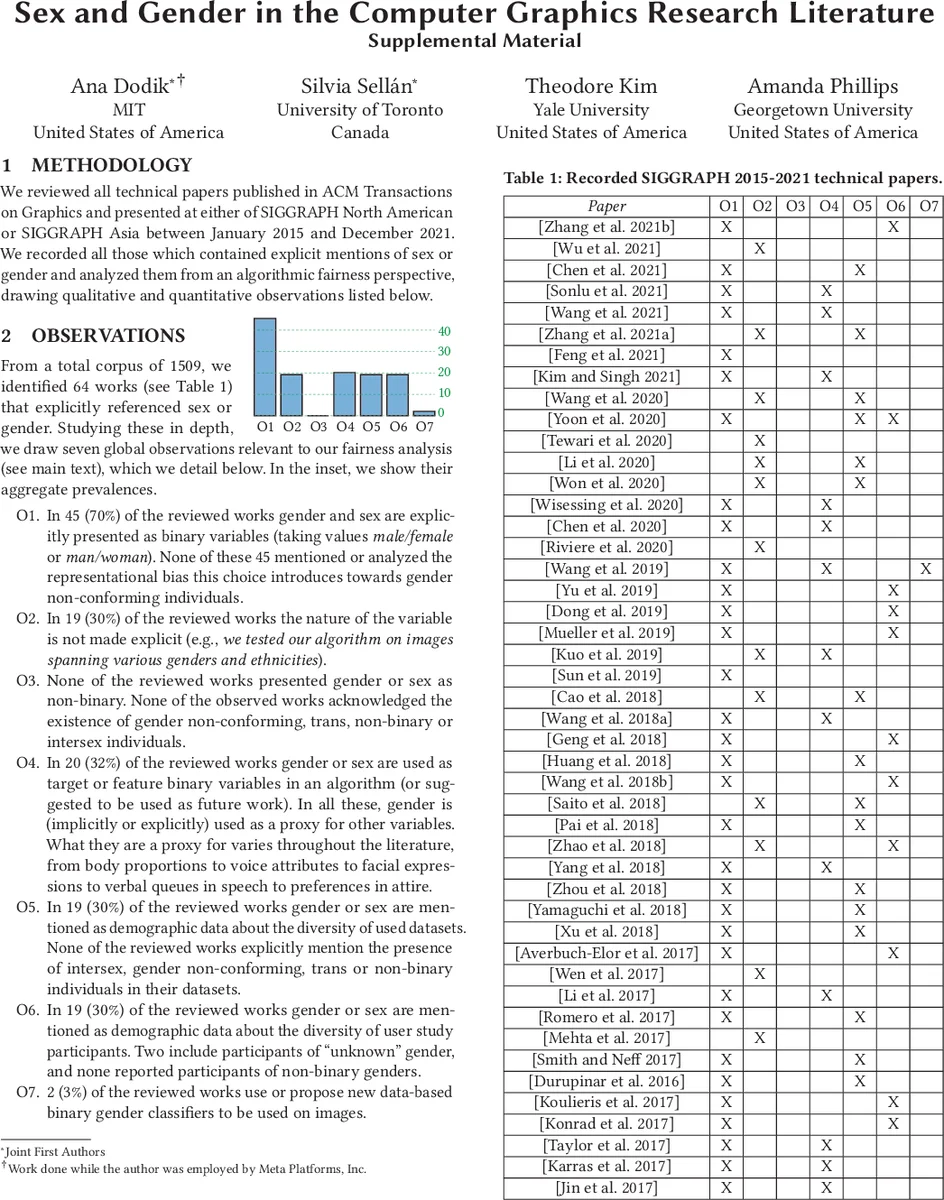
이 연구는 SIGGRAPH 학술대회 논문 64편을 대상으로 ‘sex’와 ‘gender’라는 용어가 등장하는 모든 사례를 수집·분류하였다. 조사 결과, 해당 논문들은 거의 모두 성과 젠더를 이진적(남/녀) 변수로만 취급했으며, 이는 데이터 수집 단계에서 비이진 인구를 배제하거나, 측정 단계에서 이미지 기반 성 인식기와 같이 자기보고가 아닌 외부 추정 방법을 사용함으로써 나타난다. 저자들은 Suresh와 Guttag(2021)의 알고리즘 공정성 프레임워크를 적용해 편향을 다섯 단계(대표성, 역사적, 측정, 생략 변수, 평가, 배포)로 구분하였다. 대표성 편향은 데이터셋에 비이진 성·젠더 인구가 전혀 포함되지 않은 점에서 드러났으며, 이는 모델이 해당 집단에 대해 일반화되지 못하게 만든다. 역사적 편향은 기존의 사회적 성 고정관념을 학습 데이터에 그대로 반영함으로써 ‘드레스는 여성, 짧은 머리는 남성’과 같은 오류를 초래한다. 측정 편향은 성·젠더를 신체 비율·음성 높이 등과 같은 구체적 특성의 대리 변수로 사용하는데, 이는 실제 특성을 왜곡하고 비이진 사용자를 오분류한다. 생략 변수 편향은 머리 길이·힙 폭 등 더 직접적인 특성을 무시하고 성·젠더만을 사용함으로써 모델 성능 향상의 원인을 정확히 파악하지 못하게 만든다. 평가 편향은 이진화된 성·젠더 모델을 기준으로 다른 연구를 평가함으로써 편향된 벤치마크가 지속되는 구조적 문제를 야기한다. 마지막으로 배포 편향은 실제 제품(가상 피팅, 음성 비서 등)에서 비이진 사용자를 배제하거나, 사용자가 자신의 정체성을 숨기도록 강요하는 상황을 초래한다. 이러한 일련의 편향은 단순히 기술적 결함을 넘어, 성소수자에 대한 대표성 손실·스테레오타입 강화·서비스 접근 제한이라는 실질적 해를 낳는다. 논문은 이러한 문제를 해결하기 위해 데이터 수집 시 자기보고식 비이진 성·젠더 옵션을 제공하고, 알고리즘 설계·평가 단계에서 편향 메트릭을 명시·측정하며, 배포 전 실사용자 테스트를 통해 실세계 영향을 검증할 것을 제안한다.
댓글 및 학술 토론
Loading comments...
의견 남기기