텍스트와 음성 기반 전신 애니메이션 합성 시스템
초록
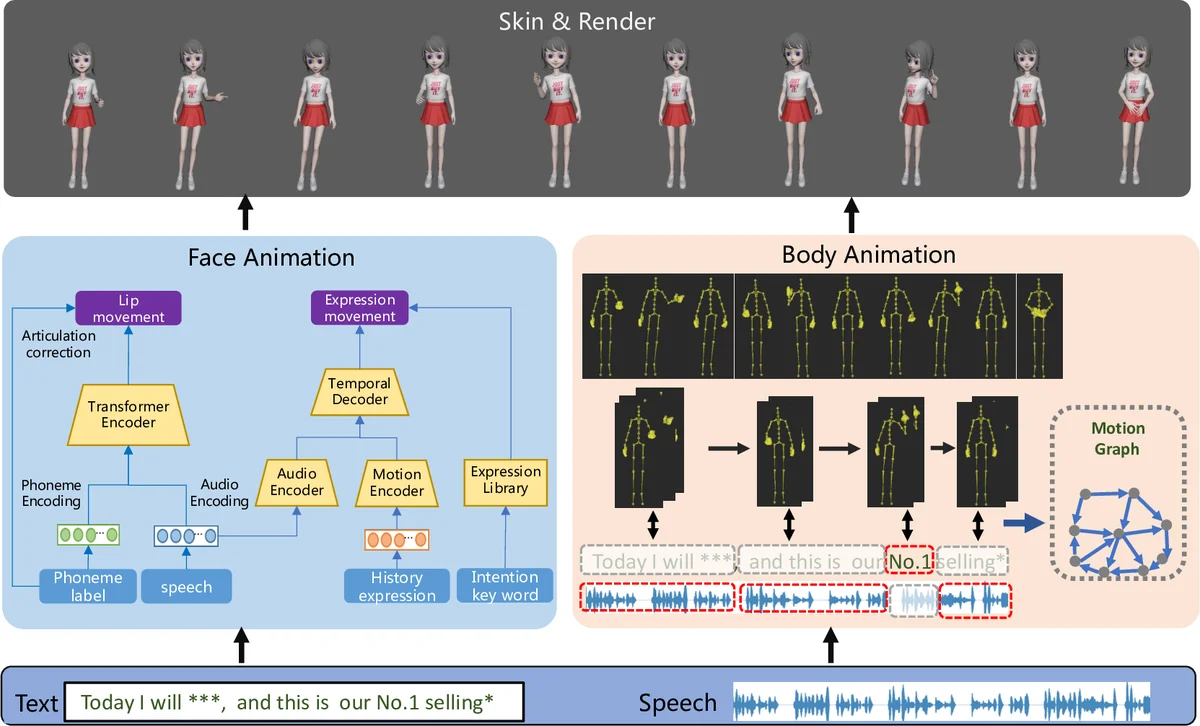
본 논문은 텍스트와 음성 입력을 동시에 이용해 얼굴과 전신 움직임을 자동으로 생성하는 시스템을 제안한다. 얼굴 애니메이션은 멀티패스 트랜스포머로 음성·텍스트(음소) 정보를 융합해 입술 움직임과 상부 표정을 예측하고, 전신은 모션 그래프와 규칙 기반 검색으로 의미 동작과 리듬 동작을 결합한다. 최종적으로 스키닝·렌더링을 거쳐 실시간 스트리밍에 적합한 고품질 3D 아바타 영상을 만든다.
상세 분석
이 연구는 기존 연구가 얼굴 혹은 몸 중 하나에만 초점을 맞추던 한계를 극복하고, 텍스트와 음성이라는 두 가지 모달리티를 동시에 활용해 전신 애니메이션을 생성한다는 점에서 의미가 크다. 얼굴 파트에서는 멀티패스 트랜스포머 구조를 도입해 음성의 MFCC·MFB 특징과 텍스트에서 추출한 음소 라벨을 결합한다. 특히 25프레임(1초) 윈도우를 사용해 시간적 컨텍스트를 포착하고, 입술 움직임 손실(L_lip)에서는 형태와 속도 차이를 동시에 최소화함으로써 입술의 정확한 동기화를 달성한다. 또한 발음 교정 규칙(‘b/p/m’ 발음 시 입을 닫는 등)을 적용해 물리적 타당성을 높였다. 표정 생성은 두 단계로 나뉜다. 첫 번째 단계는 오디오 인코더와 히스토리 모션 인코더를 결합한 트랜스포머 디코더로 리듬 기반 표정을 예측하고, SSIM 손실을 사용해 구조적 유사성을 보존한다. 두 번째 단계는 텍스트에서 감정·의도 태그를 추출해 사전 정의된 50여 개의 의도 기반 표정과 결합한다. 이로써 단순한 리듬 표정을 넘어 감정 표현까지 포괄한다. 전신 파트는 모션 그래프 기반 접근을 채택한다. 전문 배우가 촬영한 모션 데이터를 ‘의미 동작’(숫자, 방향 등)과 ‘비의미 동작’(자세 전환, 발걸음 등)으로 구분하고, 각 동작을 작은 세그먼트로 분할해 노드화한다. 전이 비용은 관절 위치와 속도 차이로 정의되며, 임계값 이하일 때만 엣지를 생성한다. 검색 단계에서는 입력 텍스트·음성을 구문 단위로 분할하고, 의미 구문에 맞는 의미 동작을 강제 매핑한다. 비의미 구문은 음성 리듬과 동기화된 비의미 동작을 비용 최소화 방식으로 배정한다. 최적화 목표식은 전이 비용, 의미 손실, 리듬 손실을 가중합한 형태이며, λ 파라미터를 통해 사용자가 강조하고 싶은 요소를 조정할 수 있다. 이러한 규칙 기반 검색은 평균적인 포즈를 회피하고, 텍스트·음성의 일대다 매핑을 자연스럽게 구현한다. 시스템 전체는 얼굴·전신 애니메이션을 합성 후 스키닝·렌더링 파이프라인을 거쳐 실시간 스트리밍에 적합한 비디오 스트림을 출력한다. 실험 결과는 다양한 언어(중국어·영어)와 다양한 감정·의도에 대해 높은 품질과 다양성을 보이며, 전문가와 일반 사용자 모두에게 긍정적인 평가를 받았다. 향후 연구에서는 감정·성격·상호작용을 더욱 정교화해 아바타의 표현력을 확대할 계획이다.
댓글 및 학술 토론
Loading comments...
의견 남기기