보안과 설명 가능한 머신러닝을 위한 파이썬 라이브러리 secml
secml은 머신러닝 모델에 대한 테스트‑시간 회피 공격과 학습‑시간 중독 공격을 포함한 다양한 적대적 공격을 구현하고, 보안 평가 곡선과 공격 손실 시각화, 특징·프로토타입 기반 설명 방법을 제공하는 오픈소스 파이썬 라이브러리이다. scikit‑learn, PyTorch 등 주요 프레임워크와 연동되며, 화이트박스·블랙박스 위협 모델을 모두 지원한다.
저자: Maura Pintor, Luca Demetrio, Angelo Sotgiu
본 논문은 머신러닝 모델에 대한 적대적 위협을 체계적으로 연구·평가할 수 있도록 설계된 파이썬 라이브러리 secml을 소개한다. 서론에서는 머신러닝이 테스트‑시간 회피(evasion), 학습‑시간 중독(poisoning), 모델 스틸링, 멤버십 추론 등 다양한 공격에 취약함을 언급하고, 기존 라이브러리들은 주로 딥러닝에 국한된 공격만 제공하거나 보안 평가를 위한 도구가 부족하다는 문제점을 제시한다. 이를 해결하기 위해 secml은 (i) 다양한 위협 모델(화이트박스·블랙박스, 특성·도메인 수준 변조) 하에서 공격을 정의·최적화하는 통합 프레임워크와 (ii) 공격 성공 원인을 설명하는 설명 가능성 메서드를 동시에 제공한다.
소프트웨어 구조는 크게 adv, ml, explanation, optim, data, array, figure, utils 등 8개의 패키지로 구성된다. adv 패키지는 CleverHans와 Foolbox에서 가져온 회피 공격(CW, PGD, PGD‑patch 등)과 저자 자체 구현 공격(다양한 SVM·RF·선형 모델에 대한 중독 공격)을 포함한다. 각 공격은 손실 함수와 제약 조건을 별도 객체로 정의하고, 옵티마이저(gradient‑based PGD, PGD‑LS, gradient‑free NES 등)를 교체함으로써 화이트박스↔블랙박스 전환이 가능하도록 설계되었다. ml 패키지는 scikit‑learn 분류기와 PyTorch 모델을 래핑해, 자동 미분을 통한 gradient 제공 및 체인 규칙에 의한 end‑to‑end gradient 계산을 지원한다. 특히, scikit‑learn 모델에 대해서는 손실의 미분을 수식적으로 구현해 gradient‑based 공격을 가능하게 한다.
explanation 패키지는 특징 기반 LIME·Integrated Gradients와 프로토타입 기반 Influence Functions을 구현한다. 이를 통해 회피 공격이 어떤 피처를 변조했는지, 혹은 어떤 학습 샘플이 특정 예측에 큰 영향을 미쳤는지를 시각화한다. optim 패키지는 기본 PGD와 더 효율적인 PGD‑LS(선형 탐색) 구현을 제공해, 공격당 필요한 gradient 평가 횟수를 크게 줄인다. data와 array 패키지는 다양한 공개 데이터셋 로더와 dense·sparse 행렬 인터페이스를 제공해, 텍스트, 이미지, 바이너리 등 다양한 도메인에 적용 가능하도록 만든다. figure 패키지는 matplotlib 기반의 고급 시각화 도구를 제공해, 공격 손실 곡선, confidence 변화, 보안 평가 곡선 등을 자동으로 그릴 수 있다.
보안 평가 기능은 두 가지 핵심 시각화를 제공한다. 첫째, “security evaluation curve”는 입력 변형 강도(‖δ‖p)와 모델 정확도 감소를 그래프로 나타내어, 공격 강도에 따른 모델 취약성을 정량화한다. 둘째, “attack loss inspection plot”은 각 iteration에서 손실과 목표 클래스 confidence 변화를 시각화해, 공격이 수렴했는지, 하이퍼파라미터(스텝 사이즈, 반복 횟수)가 적절한지 판단한다. 이러한 시각화는 기존 라이브러리에서 제공되지 않는 독창적인 기능이다.
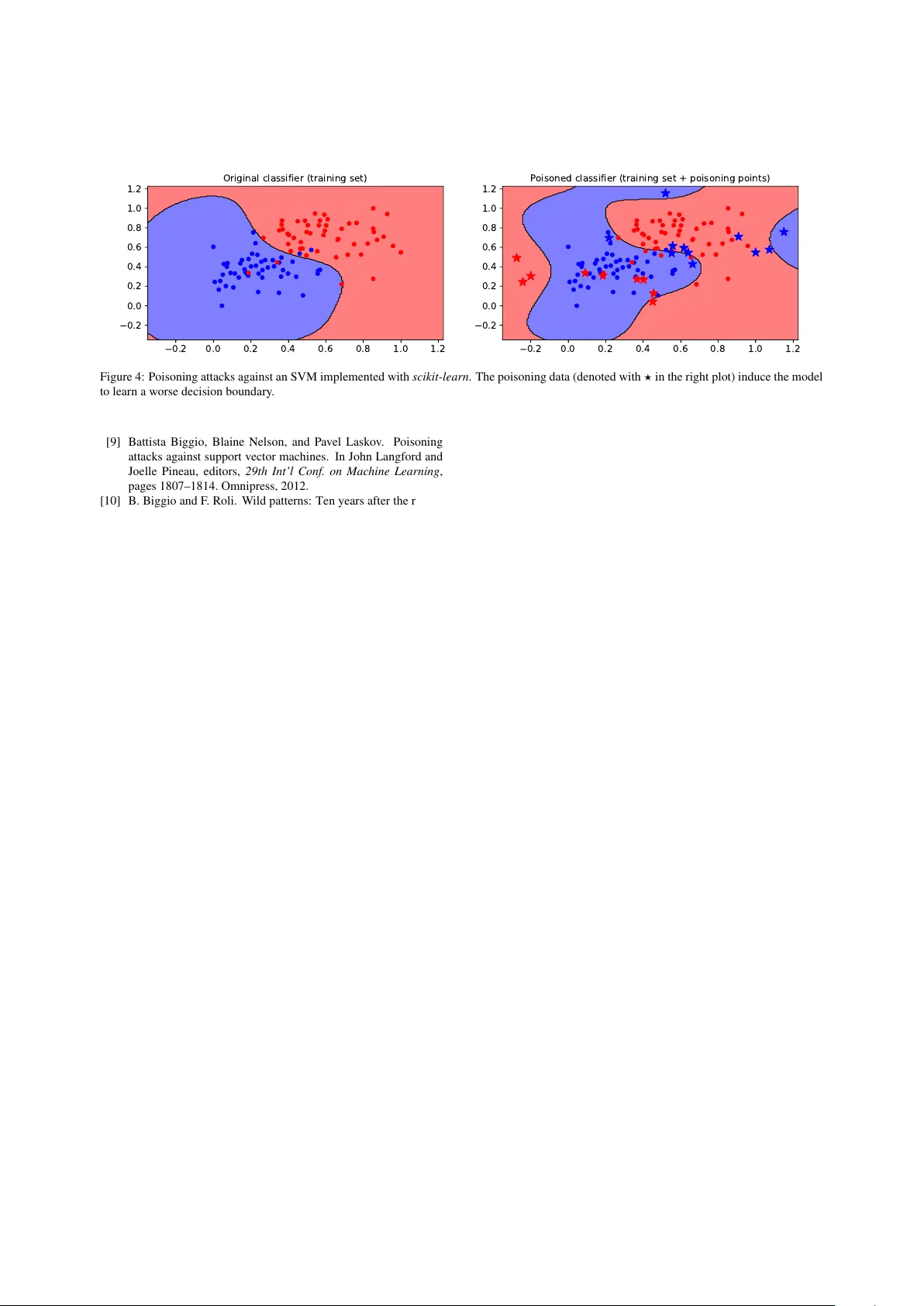
실험에서는 두 가지 사례를 제시한다. 첫 번째는 ResNet‑18(이미지넷 사전 학습 모델)에 대해 CW, PGD, PGD‑patch 공격을 적용해, 목표 클래스(tiger)로 오분류되는 과정을 시각화한다. 특히 PGD‑patch는 라이선스 플레이트 영역만 변조하고, Integrated Gradients를 통해 해당 영역이 모델 예측에 미치는 영향을 강조한다. 두 번째는 scikit‑learn SVM에 대한 중독 공격을 수행해, 악성 데이터 포인트가 결정 경계를 왜곡하고 테스트 정확도가 감소하는 과정을 보여준다. 두 실험 모두 secml의 공격 구현, 최적화, 시각화, 설명 기능이 원활히 작동함을 증명한다.
비교 표(Table 1)를 통해 Foolbox, ART, CleverHans와 비교했을 때, secml은 공격 손실 시각화, 보안 평가 곡선, dense·sparse 데이터 지원, 설명 가능성, 모델 줍, 포괄적인 튜토리얼 등 전반적인 기능에서 가장 풍부함을 확인한다.
테스트는 macOS, Ubuntu, Debian, Windows 환경에서 GitHub Actions를 이용해 자동화했으며, 전체 유닛 테스트와 문서화가 제공된다. 향후 계획으로는 새로운 방어 메커니즘 추가, TensorFlow·JAX 등 추가 딥러닝 프레임워크 래퍼 제공, 모델 줍 확대, 커뮤니티 기반 플러그인 생태계 구축이 제시된다.
결론적으로 secml은 공격·방어·설명이라는 세 축을 하나의 통합 프레임워크에 담아, 연구자와 실무자가 머신러닝 보안 실험을 재현 가능하고 효율적으로 수행하도록 지원한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기