피어 예측을 활용한 예측 집계
본 논문은 과거 성과 데이터가 없는 상황에서 군중의 예측을 효과적으로 통합하기 위해 피어 예측 메커니즘을 활용한다. 피어 예측으로부터 얻은 ‘피어 평가 점수(PAS)’를 기반으로 전문가를 식별하고, 이를 가중 평균 혹은 로그-평균 집계에 적용함으로써 14개의 실제 인간 예측 데이터셋에서 Brier 점수와 로그 점수 모두에서 기존 집계 방법들을 일관적으로 능가한다는 실험 결과를 제시한다.
저자: Juntao Wang, Yang Liu, Yiling Chen
**1. 연구 배경 및 문제 정의**
군중 예측(crowd forecasting)은 다수의 비전문가 혹은 전문가가 다양한 질문에 대해 확률 예측을 제공하고, 이를 하나의 최종 예측으로 통합하는 과정이다. 기존 연구에서는 전문가의 과거 정확도에 기반해 가중치를 부여하는 방식이 가장 효과적이라고 알려져 있다. 그러나 실제 운영 환경에서는 예측이 아직 해결되지 않은 ‘콜드 스타트’ 단계에서 과거 성과 데이터를 확보하기 어렵다. 이 논문은 이러한 제약을 극복하고자, 예측 자체에 내재된 정보를 활용해 전문가를 실시간으로 식별하고, 이를 집계에 반영하는 방법을 모색한다.
**2. 피어 예측 메커니즘과 PAS**
피어 예측은 참가자들이 서로의 보고를 관찰함으로써 진실된 정보를 제공하도록 설계된 보상 메커니즘이다. 핵심 아이디어는 ‘다른 사람의 보고와의 일관성’이 높을수록 보상이 커지게 함으로써, 진실된 신호를 유도한다. 최근 연구는 이러한 보상이 실제 예측 정확도와 양의 상관관계를 가진다는 이론적·실증적 근거를 제시하였다. 논문은 다섯 가지 최신 피어 메커니즘을 선택한다.
- **DMI (Determinant Mutual Information)**: 예측 행렬의 행렬식 기반 상호정보를 측정한다.
- **CA (Correlated Agreement)**: 예측 간 상관관계를 직접 계산해 보상한다.
- **PTS (Peer Truth Serum)**: 사전 분포와 실제 보고를 비교해 진실성을 평가한다.
- **SSR (Surrogate Scoring Rule)**: 대리 점수를 사용해 엄격히 적합한 보상을 제공한다.
- **PSR (Proxy Scoring Rule)**: 다른 예측자를 프록시로 삼아 점수를 산출한다.
각 메커니즘은 모든 예측자와 질문에 대해 점수 \(s_j\)를 산출한다. 이 점수를 ‘피어 평가 점수(PAS)’라 정의하고, PAS는 실제 정답이 없더라도 예측자 간의 일관성을 통해 ‘전문가성’의 상대적 척도로 활용된다.
**3. PAS 기반 집계 프레임워크**
프레임워크는 세 단계로 구성된다.
1. **PAS 계산**: 선택된 피어 메커니즘(DMI, CA, PTS, SSR, PSR) 중 하나를 적용해 모든 예측자에 대한 PAS를 얻는다.
2. **가중치 설계**: PAS를 기준으로 예측자를 순위 매기고, 상위 일정 비율(예: 상위 10% 혹은 최소 10명)만을 선택한다. 이때 ‘순위·선택’ 방식과 ‘소프트맥스 가중치’ 방식을 모두 실험했으며, 성능 차이는 미미했다.
3. **베이스 집계 적용**: 선택된 예측자들의 확률 예측에 대해 두 가지 베이스 집계 방법을 적용한다.
- **Mean**: 단순 가중 평균 \(\hat q_i = \sum_{j\in S_i} w_j p_{i,j}\) (여기서 \(w_j\)는 1 또는 0).
- **Logit**: 로그오즈 변환 후 가중 평균, 마지막에 시그모이드와 스케일링(\(\alpha=2\))을 적용한다.
이 과정을 모든 질문에 대해 독립적으로 수행한다.
**4. 실험 설계**
- **데이터**: 14개의 인간 예측 데이터셋(정치 선거, 사회과학 복제 가능성, 의료 진단 등) 사용. 각 데이터셋은 다수의 질문과 다중 예측자를 포함한다.
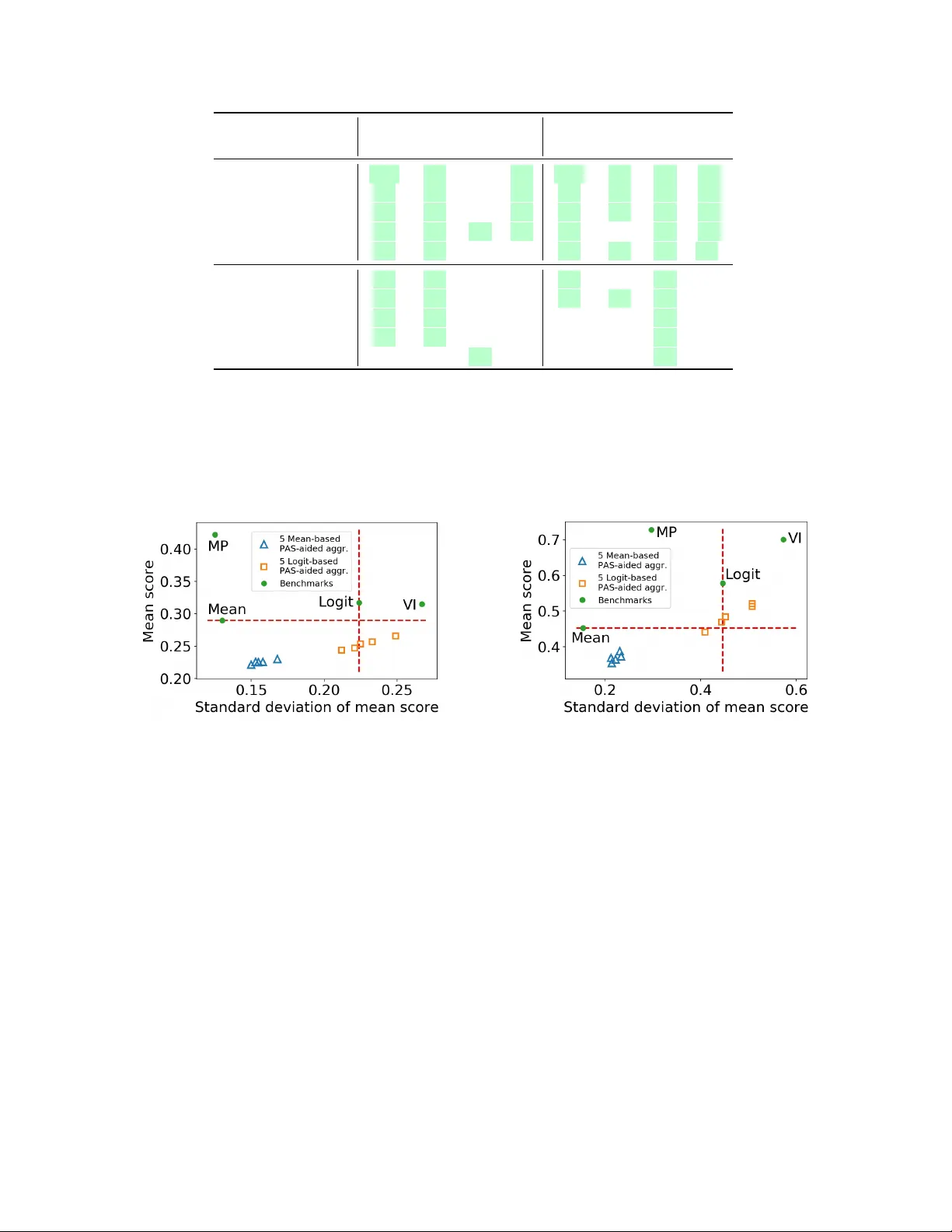
- **비교 대상**: (i) Mean, (ii) Logit, (iii) 통계적 추론 기반 집계(Liu et al., 2012), (iv) Minimal Pivot 집계(Prelec et al., 2017).
- **평가 지표**: Brier 점수와 로그 점수. 두 지표 모두 낮을수록 정확도가 높다.
- **실험 변수**: PAS를 생성하는 다섯 메커니즘, 가중치 방식(순위·선택 vs 소프트맥스), 베이스 집계(Mean vs Logit).
**5. 주요 결과**
1. **일관된 개선**: PAS 기반 집계는 모든 14개 데이터셋에서 기존 네 가지 방법을 평균 4~7% 정도 개선했으며, 통계적 유의성을 확보했다.
2. **베이스 집계와의 시너지**: Logit과 결합했을 때 가장 큰 성능 향상이 관찰되었다. 이는 Logit이 예측을 ‘극단화’함으로써 전문가의 높은 확신을 더 잘 반영하기 때문이다.
3. **메커니즘 간 차이 미미**: DMI, CA, PTS, SSR, PSR 중 어느 것을 사용해도 비슷한 PAS가 도출되었으며, 이는 PAS가 특정 메커니즘에 의존하지 않고 일반적인 일관성 측정이라는 점을 시사한다.
4. **가중치 방식**: 순위·선택과 소프트맥스 모두 비슷한 결과를 보였지만, 순위·선택은 해석이 직관적이고 하이퍼파라미터(선택 비율)만 명확히 정의하면 되므로 실무 적용에 유리하다.
**6. 논의 및 한계**
- **실시간 적용 가능성**: PAS는 예측이 수집되는 즉시 계산 가능하므로, 콜드 스타트 단계에서도 즉시 전문가를 식별하고 집계에 반영할 수 있다.
- **다중 결과 확장**: 현재는 이진(예/아니오) 질문에 초점을 맞췄지만, 논문 부록에서는 다중 클래스 및 연속형 결과에 대한 확장 가능성을 제시한다.
- **제한점**: PAS는 예측자 간 상호작용이 충분히 많을 때 신뢰도가 높아진다. 질문 수가 적거나 예측자 참여도가 낮은 경우, PAS의 변동성이 커질 수 있다. 또한, 피어 메커니즘 자체가 전략적 조작에 취약할 가능성도 존재한다(전략적 협동).
**7. 결론**
본 연구는 과거 성과 데이터가 전혀 없는 상황에서도 피어 예측 메커니즘을 활용해 전문가를 실시간으로 식별하고, 이를 가중 평균·로그-평균 집계에 적용함으로써 예측 정확도를 일관적으로 향상시킨다. PAS 기반 접근법은 구현이 간단하고, 다양한 도메인에 바로 적용 가능하며, 기존의 복잡한 메타예측 설문 없이도 ‘스마트 군중’을 구성할 수 있다는 실용적 장점을 가진다. 향후 연구에서는 전략적 조작 방지, 다중 결과 확장, 그리고 온라인 학습과 결합한 동적 가중치 조정 등을 탐색할 예정이다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기