요약 기반 무정답 질문 생성의 교육 적용 가능성 탐구
초록
본 연구는 교과서 텍스트에 답변을 사전에 지정하지 않는 질문 생성(QG) 모델을 적용해 보면서, 원문 대신 인간이 만든 요약문을 입력으로 사용할 경우 질문의 적합성·해석 가능성·수용성이 크게 향상된다는 것을 실증한다. 자동 요약도 인간 요약에 비해 중간 정도의 성능을 보이며, 요약 기반 접근이 무정답 QG의 주요 오류를 완화한다는 점을 확인하였다.
상세 분석
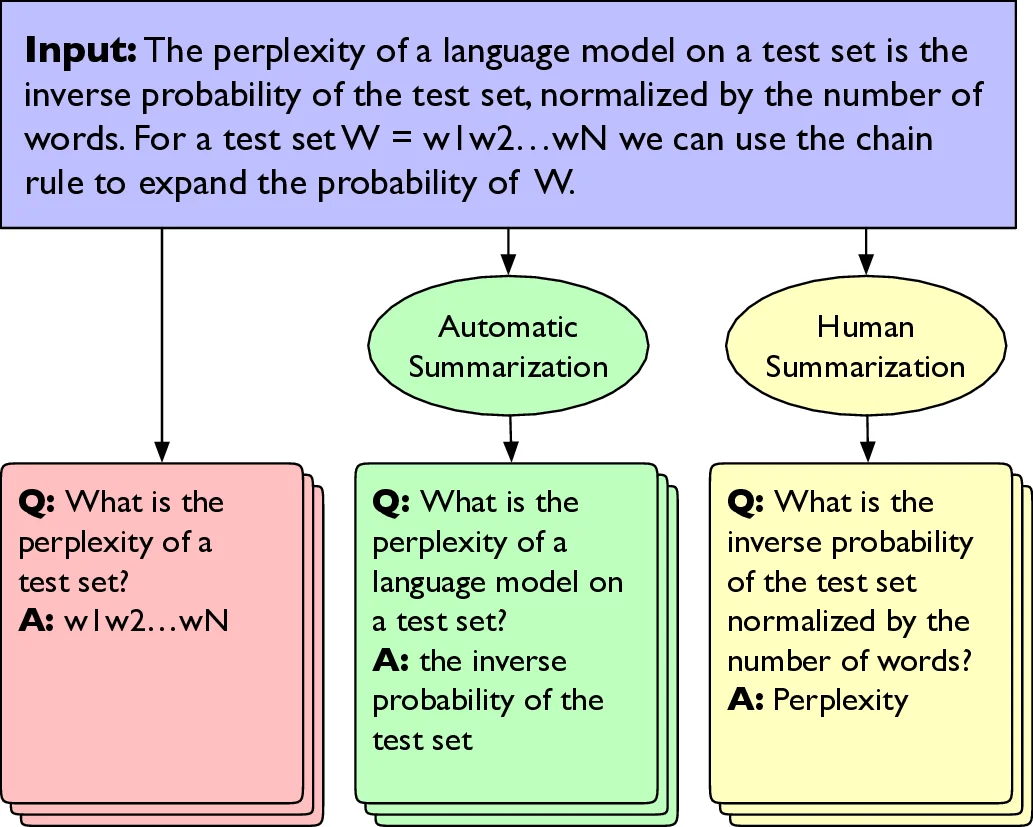
이 논문은 기존의 답변‑지정(answer‑aware) 질문 생성 방식이 교육 현장에서 요구하는 효율성과 확장성에 한계를 보인다는 점에 주목한다. 답변을 미리 지정하지 않는 answer‑agnostic QG 모델은 입력 텍스트에서 스스로 중요한 개념을 추출해야 하는데, 교과서와 같이 전문 용어와 긴 문단이 혼재된 자료에서는 의미 없는 혹은 해석 불가능한 질문을 생성하기 쉽다. 저자들은 이러한 문제를 완화하기 위해 두 단계 요약 전략을 도입한다. 첫 번째는 인간 연구조교가 교과서 각 절을 요약하도록 하여 핵심 용어와 개념을 압축시킨 ‘human summary’를 만든다. 두 번째는 BART‑large 기반 자동 요약 모델을 이용해 동일한 텍스트를 요약한다. 요약문을 입력으로 사용하면 모델이 답변 후보를 추출할 때 보다 높은 토픽 적합성을 보이며, 이어지는 질문 생성 단계에서도 문맥에 맞는 질문을 만들 가능성이 크게 증가한다.
실험 설계는 세 가지 입력 조건(원문, 인간 요약, 자동 요약)에서 동일한 T5‑base QA‑QG 하이브리드 모델을 적용하고, 각각 1208·667·318개의 질문‑답 쌍을 생성한 뒤, 무작위 추출된 300개의 질문을 3명의 연구조교가 ‘수용성’, ‘문법성’, ‘해석 가능성’, ‘관련성’, ‘정답성’ 다섯 가지 기준으로 이진 평가하였다. 결과는 인간 요약을 사용했을 때 수용성(83 % vs 33 %), 관련성(95 % vs 61 %), 해석 가능성(94 % vs 56 %)이 크게 상승했음을 보여준다. 자동 요약 역시 원문 대비 개선된 점수를 기록했지만, 문법성에서 약간의 하락을 보였다. 또한, 교과서에 강조된 핵심 용어(볼드 처리된 키워드)의 커버리지를 측정한 결과, 인간 요약은 높은 정밀도와 재현율을 동시에 달성했으며, 원문은 재현율은 높지만 정밀도가 낮고, 자동 요약은 그 중간 수준을 차지한다.
주요 통계적 지표인 Cohen’s κ를 통한 교차 검증에서는 ‘관련성’·‘해석 가능성’·‘수용성’에서 평균 0.4 수준의 ‘보통’ 수준의 합의가 관찰되었으며, 이는 인간 평가가 주관적이지만 일관된 판단 기준을 가지고 있음을 시사한다. 한계점으로는 답변 추출 단계에서 동일 문장에 대해 중복된 답을 선택하는 모델의 제한, 요약 품질에 따른 편향, 그리고 평가 샘플이 제한적이라는 점을 들 수 있다. 향후 연구는 요약‑질문 생성 파이프라인을 엔드‑투‑엔드 방식으로 통합하고, 교육 현장에서 실제 플래시카드·퀴즈 제작에 적용해 장기 학습 효과를 측정하는 방향을 제안한다.
댓글 및 학술 토론
Loading comments...
의견 남기기