탐색 비용과 무임승차의 불공정성 정량화
초록
이 논문은 다중 팔 밴딧 문제에서 여러 에이전트가 동시에 행동할 때, 한 에이전트가 다른 에이전트의 탐색 결과를 관찰함으로써 거의 비용 없이(상수 수준) regret을 달성할 수 있음을 보인다. 특히, 자기주도형 에이전트가 표준 제로‑regret 알고리즘을 사용할 경우, 자유탐색자(free rider)는 전체 시간 동안 O(1) regret을 얻는다. 이 결과는 순수 확률적 밴딧과 선형 컨텍스트 밴딧 두 모델 모두에 적용되며, 필요한 정보량과 가정에 대한 정밀한 하한도 제시한다.
상세 분석
본 논문은 기존의 단일 의사결정자 모델을 다중 에이전트 환경으로 확장하면서, “무임승차(free riding)” 현상이 정규화된 탐색 비용을 어떻게 축소시키는지를 이론적으로 규명한다.
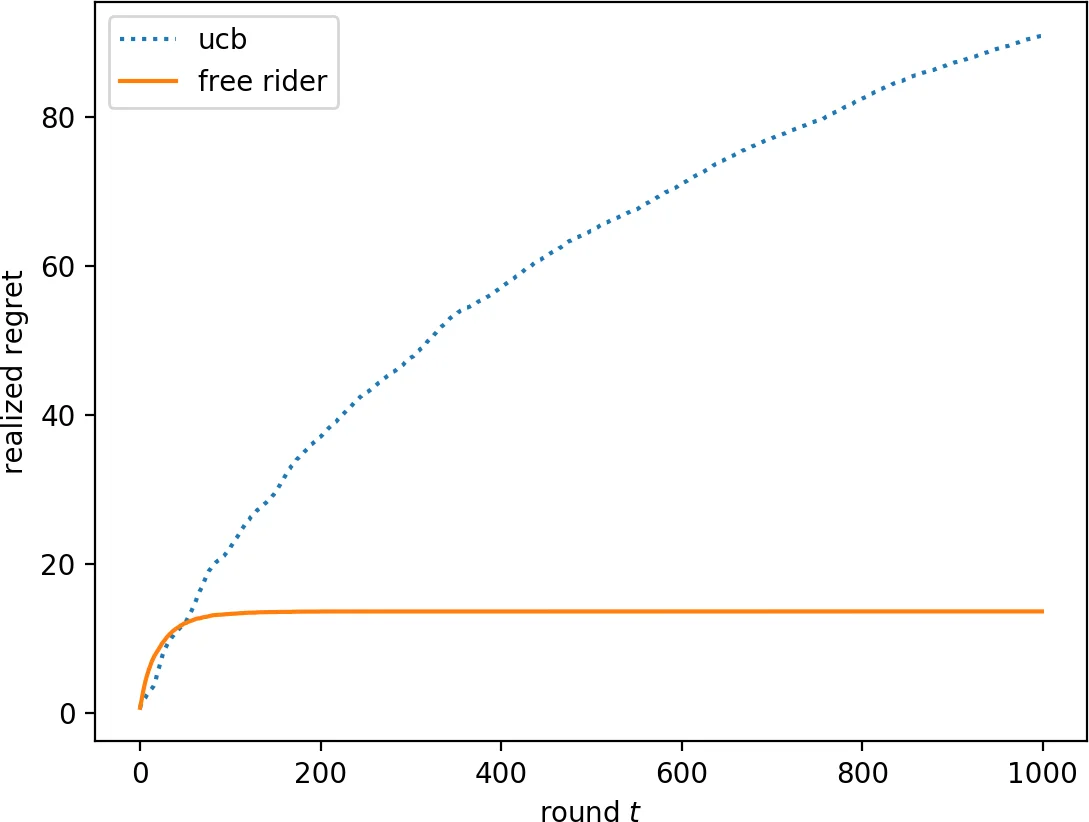
첫 번째 핵심 결과는 순수 확률적 밴딧에서이다. 저자는 두 가지 충분조건을 제시한다. (1) 어느 한 자기주도형 에이전트가 각 팔을 최소 γ·ln t 번씩, 기대값 기준으로 충분히 많이 시도한다면, 자유탐색자는 그 에이전트가 수집한 샘플을 그대로 이용해 평균 보상을 추정하고, 거의 최적의 팔을 선택함으로써 전체 regret을 상수 수준으로 제한한다. 여기서 γ는 α‑UCB와 같은 제로‑regret 알고리즘의 탐색 파라미터에 의해 명시적으로 계산된다. (2) 자기주도형 에이전트가 고확률로 o(t) 실현 regret을 달성한다면, 자유탐색자는 보상값 자체를 관찰하지 않아도 각 팔의 선택 횟수만 알면 충분히 좋은 추정치를 얻을 수 있다. 이는 부분 정보(partial‑information) 모델에서도 적용 가능함을 보여준다. 두 가정 모두 UCB, Thompson Sampling, 라운드‑로빈+exploitation 등 기존의 제로‑regret 전략이 만족한다는 점에서 실용성이 높다.
두 번째 주요 기여는 선형 컨텍스트 밴딧 확장이다. 여기서는 각 팔이 파라미터 벡터의 분포를 가지고, 에이전트마다 고유한 컨텍스트 벡터 xₚ가 존재한다. 저자는 자유탐색자의 컨텍스트가 다른 에이전트들의 컨텍스트들의 L₂‑노름이 작은 선형 결합으로 표현될 수 있을 때, 그리고 모든 다른 에이전트가 각 팔을 Ω(log t) 번씩 충분히 탐색한다면, 자유탐색자는 O(1) regret을 달성한다. 이는 컨텍스트가 서로 “유사”하거나, 하나의 에이전트가 다른 에이전트들의 행동을 선형적으로 재구성할 수 있는 경우에 해당한다.
또한, 저자는 탐색 횟수와 regret 사이의 역관계를 정량화한다. 정리 3·4는 O(T^{1‑ε}) regret을 보이는 정책이라면 각 팔을 최소 Ω(log T) 번은 샘플링해야 함을 기대값과 고확률 두 관점에서 증명한다. 정리 5는 UCB 정책이 반드시 각 팔을 최소 Ω(log t) 번은 선택해야 함을 결정론적으로 보인다. 이러한 하한은 자유탐색자가 얻을 수 있는 이득이 탐색을 전혀 하지 않는 경우와는 근본적으로 다름을 강조한다.
마지막으로, 저자는 자유탐색자가 O(log t) regret을 달성하려면 전체 컨텍스트와 보상 정보를 모두 알아야 함을 정리 10·11을 통해 보여준다. 즉, 상수 수준의 regret을 얻기 위해서는 “탐색 비용을 완전히 전가”받는 것이 아니라, 충분히 풍부한 관찰 정보를 확보해야 함을 명확히 한다. 전반적으로 이 논문은 다중 에이전트 밴딧에서 탐색 비용의 비대칭성을 정량화하고, 실제 시스템(예: 추천 서비스, 온라인 광고)에서 발생할 수 있는 무임승차 현상을 이론적으로 뒷받침한다.
댓글 및 학술 토론
Loading comments...
의견 남기기