염색체 전위 핫스팟 탐지를 위한 스캔 통계 방법
초록
본 논문은 B세포에서 관찰되는 염색체 전위 브레이크포인트의 군집을 전역적인 유의수준으로 검정하기 위해 스캔 통계 모델을 제안한다. 베르누리 과정 가정 하에 윈도우 내 성공 횟수의 최대값을 스캔 통계량으로 정의하고, 하이퍼지오메트리·이항 근사를 이용해 p‑값을 계산한다. Benjamini‑Yekutieli 보정으로 다중 검정을 제어한 뒤, 윈도우 길이 500 bp와 5 kbp 두 가지 스케일에서 핫스팟을 탐지하였다. 기존의 로컬 네거티브 이항 기반 방법(NB)과 비교해 더 넓고 강력한 핫스팟을 발견했으며, 53BP1 결핍 및 AID 과발현 상황에서 핫스팟 길이가 크게 증가함을 확인했다.
상세 분석
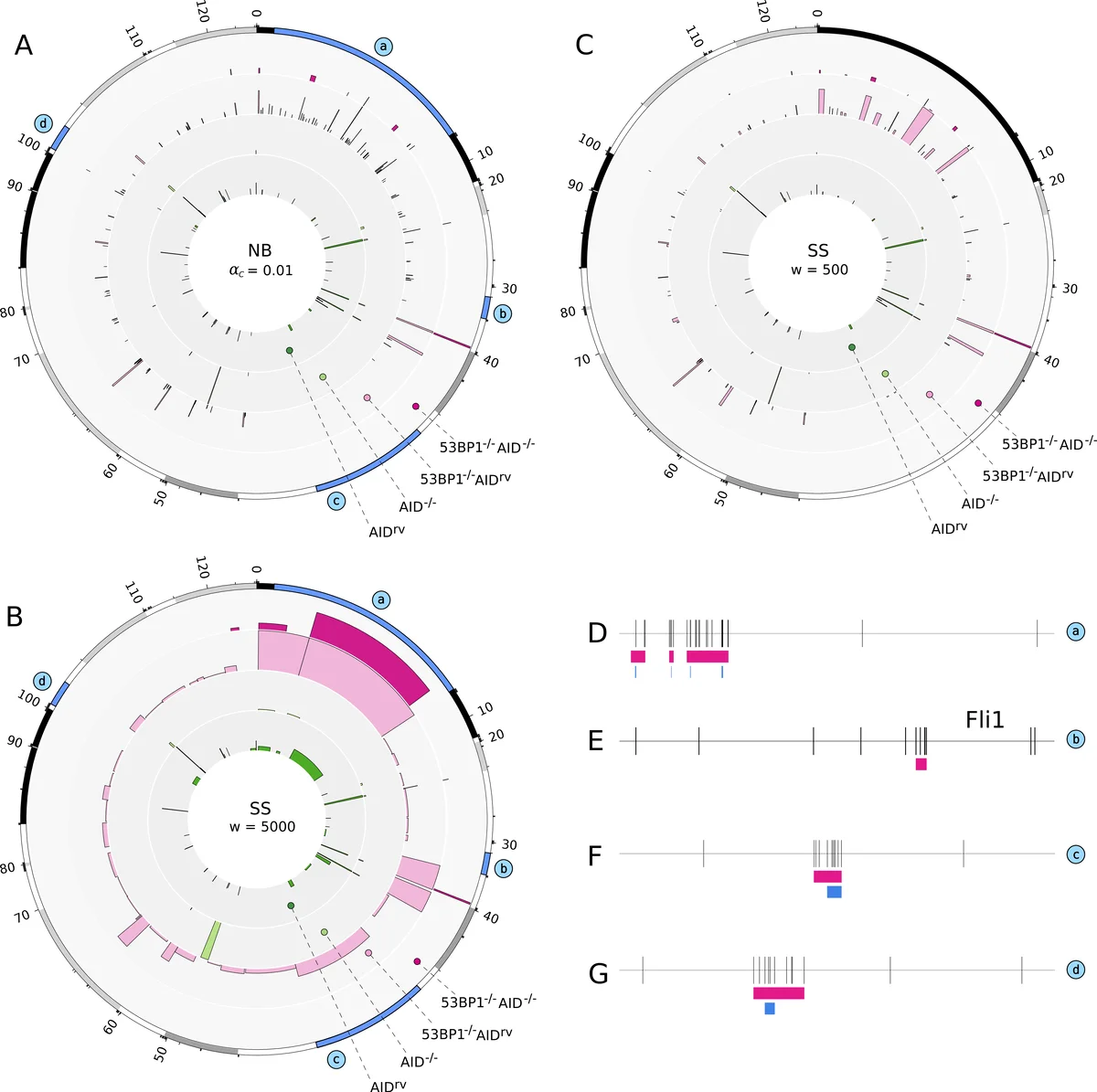
이 연구는 전통적인 로컬 클러스터 검정이 전역적인 오류율을 통제하지 못한다는 한계를 인식하고, 스캔 통계라는 고전적인 공간 통계 기법을 현대 NGS 데이터에 적용한 점이 가장 큰 혁신이다. 저자들은 염색체를 길이 N인 0‑1 시퀀스로 모델링하고, 전위 브레이크포인트가 발생할 확률 p를 전체 이벤트 수 a/N으로 추정한다. 윈도우 폭 m을 고정하고, 각 윈도우 i에서 성공 횟수 Y_i를 합산한 뒤, S_m = max_i Y_i 를 스캔 통계량으로 정의한다. 이때 S_m ≥ y 사건의 꼬리 확률을 구하는 것이 핵심이며, 정확한 하이퍼지오메트리 분포 대신 대규모 N(>10^6)과 m(≥500) 상황에서 이항 근사를 적용한다. 저자들은 2F1 초월함수를 이용해 폐쇄형 근사식(식 3)을 도출하고, 이를 통해 p‑값을 효율적으로 계산한다.
다음 단계에서는 모든 윈도우에 대해 개별 귀무가설 H0,i를 검정하고, Benjamini‑Yekutieli 절차로 종속적인 p‑값을 보정한다. 보정된 p‑값이 사전 정의된 α_H (0.05) 이하인 연속 윈도우들을 연결해 후보 핫스팟 영역 B*를 만든다. 이후 각 영역의 실제 길이 ℓ를 이용해 최종 p‑값을 재계산하고, 최종 핫스팟 집합 B†를 정의한다. 이 과정은 윈도우 길이 m을 500 bp와 5 kbp 두 가지로 설정해 다중 스케일 분석을 수행함으로써, 짧은 클러스터와 장거리 클러스터를 동시에 포착한다.
대조군으로 사용된 기존 방법(NB)은 인접 전위 사이의 거리 L_i가 기하분포를 따른다는 가정 하에, 거리의 누적 확률 P(L_i ≤ ℓ_i) ≤ α_c 로 클러스터를 정의한다. 이 방법은 개별 거리의 극단성을 검정하지만, 전체 염색체에 걸친 다중 검정 보정이 부족하고, 윈도우 크기에 민감한 한계가 있다. 저자들은 두 방법을 동일 데이터셋(4가지 B세포 조건)에서 적용해 비교했으며, 스캔 통계 기반 SS_500 및 SS_5000이 NB_0.01보다 더 넓은 핫스팟을 식별하고, 특히 53BP1 결핍·AID 과발현 상황에서 핫스팟 길이가 현저히 증가함을 보여준다.
또한, 발견된 핫스팟이 종양 억제 유전자와 겹치는 경우가 존재함을 보고했으며, ChIP‑seq 데이터와의 교차 검증을 통해 Pol II 축적과 연관된 영역임을 확인했다. 소프트웨어 구현 측면에서는 Perl과 R 기반의 hot_scan 패키지를 공개했으며, 병렬 처리와 GSL 수학 라이브러리를 활용해 대규모 유전체 스캔을 실시간에 가깝게 수행할 수 있다.
이 논문의 주요 기여는 (1) 전역적인 유의수준을 제공하는 스캔 통계 모델의 도입, (2) 베르누리·이항 근사를 통한 효율적인 p‑값 계산, (3) 다중 검정 보정을 포함한 체계적인 핫스팟 정의 절차, (4) 기존 로컬 방법과의 정량적 비교를 통한 방법론적 우위 입증, (5) 오픈소스 구현을 통한 재현성 확보이다. 이러한 접근은 전위 클러스터뿐 아니라 ChIP‑seq, 4C‑seq 등 다양한 시퀀싱 기반 데이터에서 비정상적인 신호 집합을 탐지하는 일반적인 프레임워크로 확장 가능하다.
댓글 및 학술 토론
Loading comments...
의견 남기기