데이터 품질이 기업 이사회 연계 네트워크 분석에 미치는 영향
초록
본 논문은 전 세계 1억 6천만 기업을 포함한 대규모 이사회 연계 네트워크에서 데이터 완전성·정확성 문제를 자동으로 평가·보정하는 방법을 제시한다. 국가별 기업 규모 분포와 로그정규 모델을 이용해 누락 데이터를 추정하고, 네트워크 토폴로지를 활용해 중복 노드·엣지를 자동으로 정제한다. 스웨덴 사례를 통해 품질이 낮은 데이터가 중심성·확산 결과에 미치는 편향을 실증적으로 보여준다.
상세 분석
이 연구는 두 가지 핵심 데이터 품질 문제, 즉 ‘완전성(completeness)’과 ‘정확성(accuracy)’을 체계적으로 다룬다. 완전성 평가에서는 기업 규모(매출)와 직원 수를 로그정규분포로 모델링하고, 유럽 통계청(Eurostat)에서 제공하는 국가별 기업 규모 집계와 비교한다. 이를 통해 데이터가 ‘무작위가 아닌 누락(MNAR)’ 상태임을 확인하고, 각 국가별 누락 비율을 추정한다. 특히, 부유한 국가일수록 소규모 기업이 누락되는 경향이 강해 µ 파라미터가 과대평가되는 현상을 밝혀냈다.
정확성 보정 단계에서는 네트워크 자체의 구조적 특성을 활용한다. 동일한 기업명을 가진 다중 법인, 혹은 데이터 제공자가 만든 중복 레코드를 식별하기 위해 노드의 속성(국가, 매출, 직원 수)과 연결 패턴을 비교한다. 기대 토폴로지(예: 차수 분포, 거대 성분 크기)와 실제 관측값 사이의 차이를 최소화하도록 자동 프루닝·병합 알고리즘을 설계했으며, 이는 중복 노드와 가짜 엣지를 효과적으로 제거한다.
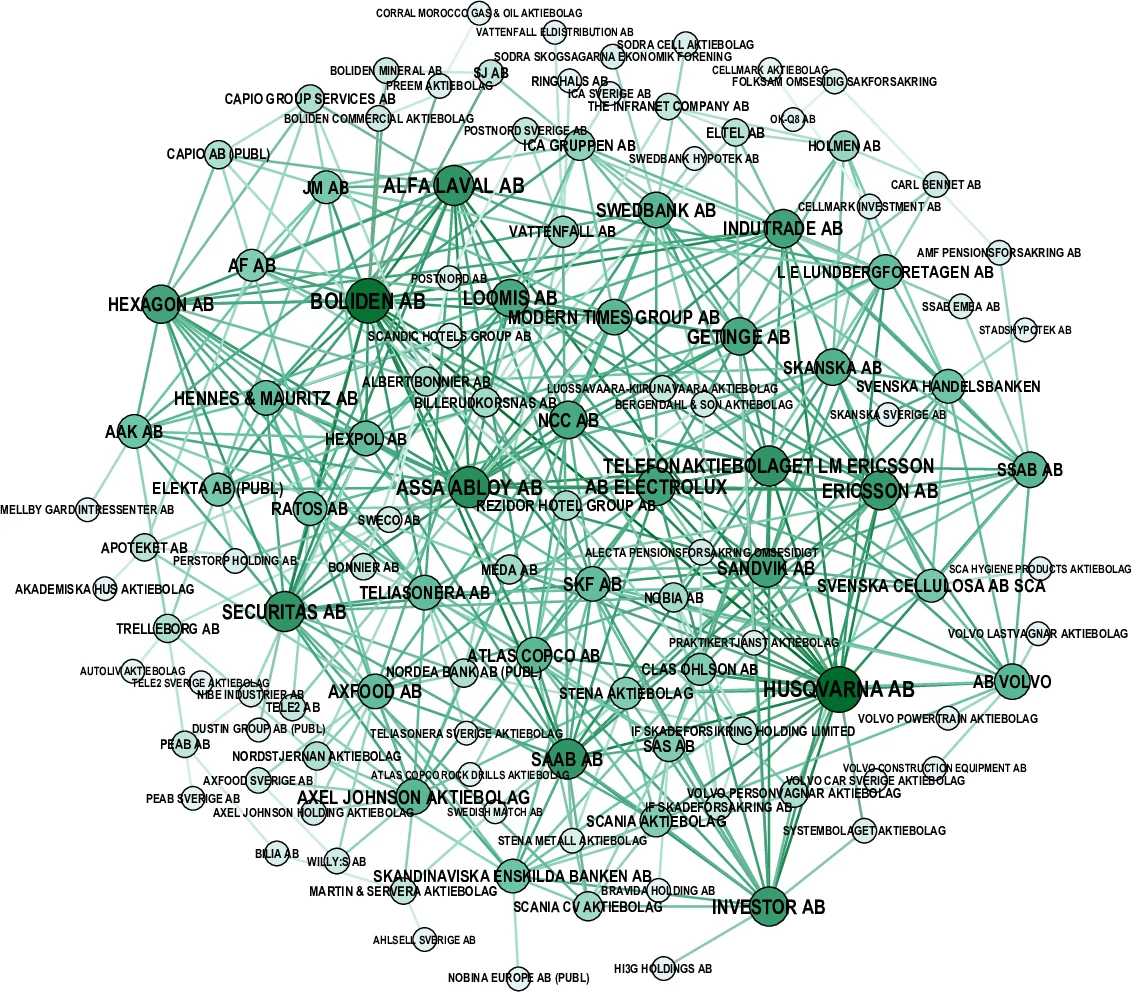
스웨덴 이사회 연계 네트워크 사례에서는 원본 데이터가 평균 매출·중심성 지표를 왜곡하고, SIS(선형 역학) 확산 모델에서 비현실적인 전파 속도를 보이는 것을 확인했다. 품질 보정 후에는 차수 분포가 기존 연구와 일치하고, 핵심 기업(예: Volvo, Ericsson)의 중심성 순위가 재조정되며, 확산 시뮬레이션에서도 보다 현실적인 영향력 범위가 도출되었다.
이러한 방법론은 대규모 기업 네트워크뿐 아니라, 사회적 연결망, 금융 네트워크 등 다양한 분야에 적용 가능하다. 특히, 데이터가 자동 수집되는 상황에서 ‘누락이 무작위가 아님’을 가정하고, 외부 집계와 내부 구조를 결합해 보정하는 접근은 향후 빅데이터 기반 네트워크 연구의 표준 절차가 될 잠재력을 가진다.
댓글 및 학술 토론
Loading comments...
의견 남기기