복잡계 특징 유사성 연결성 통합 프레임워크
초록
본 논문은 복잡계 연구에서 자주 사용되는 특징, 유사성, 연결성이라는 세 가지 핵심 표현을 체계적으로 정리하고, 이들 간의 변환 과정을 9가지 매핑 유형으로 구분한다. 패턴 인식, 최적화, 선형대수, 시계열 분석 등 다양한 분야의 기법을 위 세 축에 매핑함으로써 연구자들이 문제에 맞는 표현과 방법을 선택하도록 돕는다. 또한 변환 경로를 도식화하고, 와크스만 모델을 예시로 제시해 실제 적용 가능성을 보여준다.
상세 분석
이 논문은 복잡계 분석을 “특징(F)”, “유사성(S)”, “연결성(C)”이라는 세 가지 기본 표현으로 축소하고, 이들 사이의 변환을 6가지 기본 매핑(예: F→S, S→C 등)과 9가지 주요 매핑 유형으로 구분한다. 저자는 먼저 복잡계 연구가 물리학, 사회학, 데이터 마이닝 등 다학제적 배경을 갖고 있음을 강조하면서, 이러한 다원성을 하나의 통합 프레임워크로 정리할 필요성을 제시한다.
특징 단계에서는 내재적(intrinsic) 특징과 유도적(induced) 특징을 구분하고, 특히 공간 좌표와 같은 연속형 특징이 유사성 행렬(거리 행렬) 생성에 어떻게 활용되는지를 상세히 설명한다. 유사성 단계에서는 거리 행렬, 상관계수, 토폴로지 유사성 등 다양한 메트릭을 통해 노드 간 관계를 정량화한다. 연결성 단계에서는 그래프 구조 자체, 인접 행렬, 최단 경로, 커뮤니티 구조 등 네트워크 토폴로지를 다룬다.
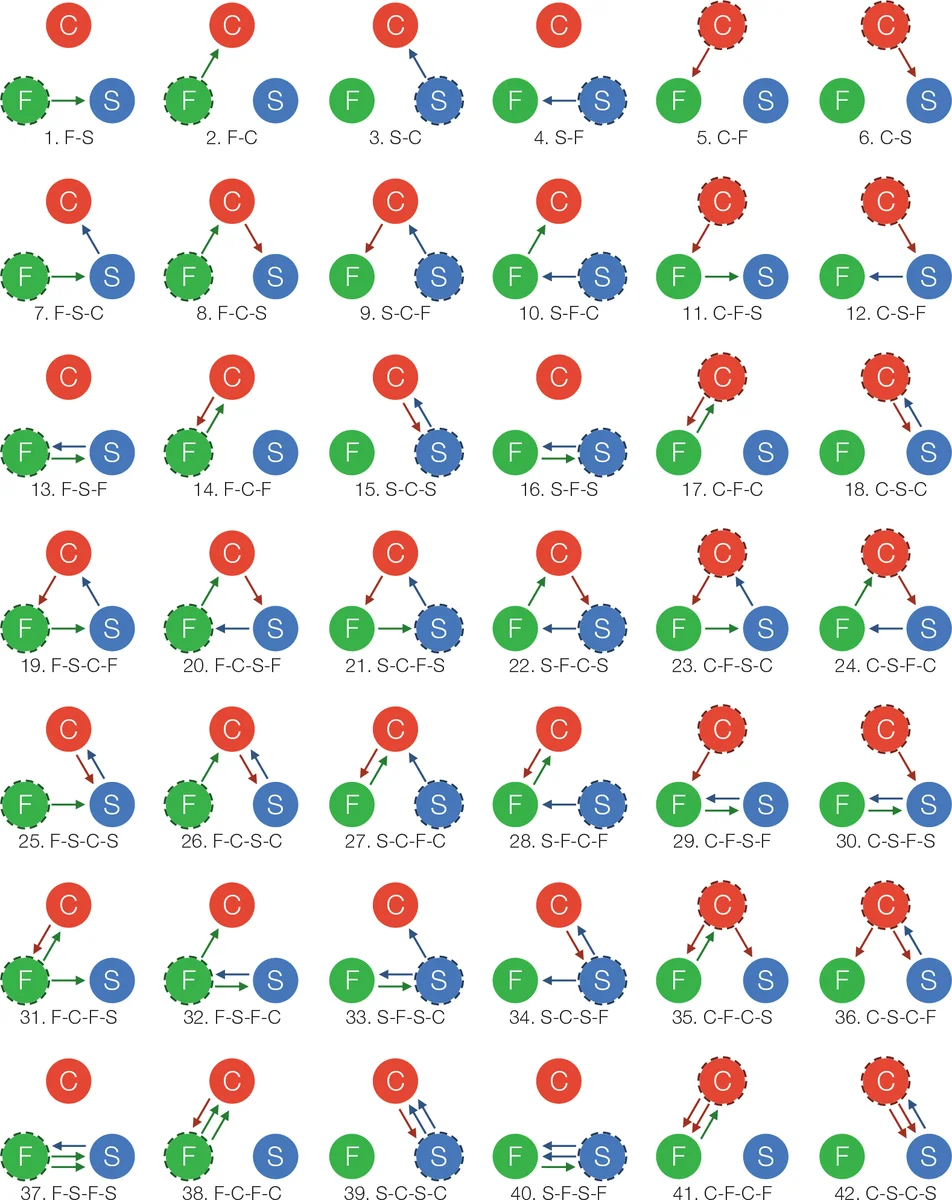
핵심 기여는 이 세 단계 사이의 변환을 “경로”라는 개념으로 모델링하고, 최대 세 번의 변환을 허용한 42개의 가능한 경로를 도표(Figure 4)로 제시한 점이다. 각 경로는 실제 연구에서 흔히 나타나는 흐름을 반영한다. 예를 들어, F→S→C→F(FSCF) 경로는 특징을 기반으로 거리 행렬을 만든 뒤, 확률적 연결 규칙으로 네트워크를 생성하고, 다시 레이아웃 알고리즘을 통해 새로운 특징(예: 시각적 좌표)을 도출하는 과정을 의미한다.
와크스만 모델을 통해 저자는 F→S→C 경로가 어떻게 구체화되는지를 보여준다. 무작위로 배치된 노드의 좌표(F) → 유클리드 거리 행렬(S) → 거리 기반 연결 확률(Pij)로 네트워크(C)를 생성한다. 이어서 힘‑기반 레이아웃을 적용해 새로운 시각적 특징을 얻는 추가 변환도 가능함을 제시한다.
또한 논문은 8가지 설계 지침을 제시한다. 문제 요구, 인터랙티브 탐색, 데이터 정제, 연구자·분야 적합성, 방법·소프트웨어 적합성, 보완적 표현, 교차수정화 등이다. 이 지침들은 어떤 표현(F, S, C)과 변환을 선택할지에 대한 실용적인 판단 기준을 제공한다.
기술적 측면에서 저자는 패턴 인식(클러스터링), 최적화(그래프 커팅), 선형대수(특징 행렬 분해), 시계열 분석(상관 기반 유사성) 등 기존 방법들을 각각의 매핑에 대응시켜 정리한다. 예컨대, 차원 축소 기법(PCA, t‑SNE)은 F→S 변환에 해당하고, 커뮤니티 탐지는 S→C 변환에 해당한다. 이러한 매핑 표는 연구자가 기존 도구를 새로운 맥락에 재활용할 수 있는 로드맵을 제공한다.
전체적으로 이 논문은 복잡계 연구에서 흔히 발생하는 “표현 선택” 문제를 체계화하고, 다양한 분야의 방법론을 통합적으로 이해할 수 있는 언어를 제시한다. 이는 새로운 연구 주제 발굴, 방법론 간 교차 적용, 그리고 교육적 커리큘럼 설계에 큰 도움이 될 것으로 기대된다.
댓글 및 학술 토론
Loading comments...
의견 남기기