완전 기억과 종료 상태 없이도 수렴하는 로컬 무후회 학습
초록
본 논문은 CFR의 두 가지 제한(완전 기억, 종료 상태)을 완화하기 위해 로컬 무후회 학습(LONR)이라는 알고리즘을 제안한다. LONR은 각 상태마다 무후회 알고리즘을 두고 Q‑learning 형태의 업데이트를 적용해, MDP와 제한된 확장 모델에서 평균 Q값이 최적값으로 수렴함을 증명한다. 또한 비동기 업데이트와 밴딧 피드백을 다루며, NoSDE 마르코프 게임에서 마지막 반복(iterate)까지 수렴하는 실험 결과를 제시한다.
상세 분석
LONR은 기존 CFR이 정보집합마다 후회 최소화 알고리즘을 두고, 후회가 최소화된 정책을 통해 기대값을 계산하는 방식을 그대로 차용한다. 차이점은 CFR이 ‘카운터팩추얼’ 보상을 사용해 터미널 상태가 도달한 뒤에만 업데이트를 수행하는 반면, LONR은 Q‑learning과 유사하게 현재 상태‑행동 쌍에 대한 보상을 즉시 이용한다. 이를 위해 논문은 ‘무절대 후회(no‑absolute‑regret)’라는 강화된 후회 개념을 도입한다. 이 속성을 만족하는 알고리즘은 매 라운드마다 얻은 보상의 절대값이 사전 정의된 ρ_k 이하로 제한되며, ρ_k → 0인 경우 평균 후회가 0에 수렴한다.
핵심 이론적 결과는 네 개의 보조 정리(Lemma)와 최종 정리(Theorem)로 구성된다. Lemma 4.1은 LONR이 생성한 Q_k 평균값이 Bellman 연산자 T와 γ·ρ_k−1 만큼 차이가 난다는 부등식을 제시한다. 여기서 γ는 할인율이며, ρ_k는 k번째 라운드까지의 누적 후회 상한이다. Lemma 4.2와 4.3은 Q_k의 범위가 유한하고, Q_k와 TQ_k 사이의 차이가 O(1/k)+γ·ρ_k−1 로 수렴함을 보인다. 마지막 Lemma 4.4는 근사 고정점(approximate fixed point) 수열이 실제 고정점 Q에 수렴한다는 일반적인 수렴 성질을 이용한다. 이를 종합해 Theorem 4.5는 LONR이 평균 Q값이 최적 Q에 수렴함을 증명한다.
이론은 기본적으로 MDP에 국한되지만, 부록에서는 전이 확률은 고정된 채 보상만 시점마다 변하는 ‘온라인 MDP’와 단일 상태에서의 정상형 게임(normal‑form game)까지 확장한다. 다중 에이전트 환경인 마르코프 게임에 대해서는 비동기 업데이트와 밴딧 피드백을 고려한 두 가지 확장을 제시한다. 비동기 버전에서는 매 단계 무작위로 하나의 상태만 업데이트하고, 그때마다 해당 상태의 무후회 알고리즘이 선택한 정책을 사용한다. 이 경우에도 기대값을 평균화하면 동일한 수렴 구도를 유지한다는 근사적 증명을 제공한다.
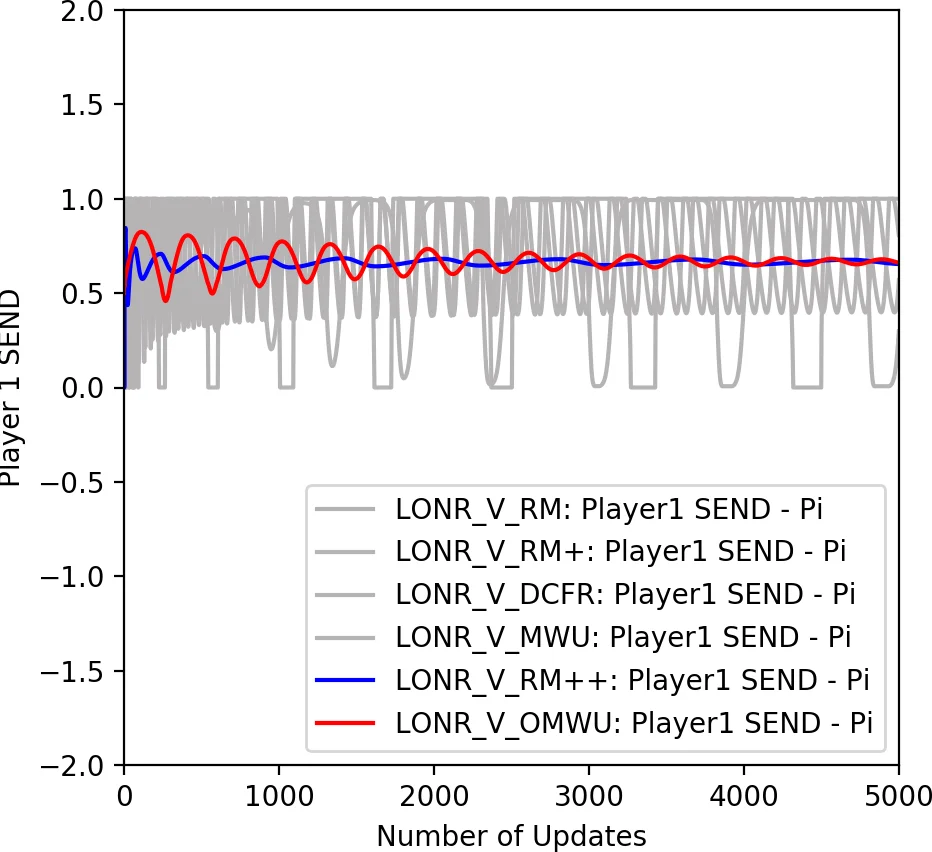
실험에서는 특히 NoSDE 게임이라는, 모든 정적 균형이 확률적이며 Q‑값만으로는 최적 무작위화 비율을 찾을 수 없는 어려운 마르코프 게임을 대상으로 LONR을 적용했다. 기존 연구는 이러한 게임에서 평균 정책은 수렴하더라도 현재 정책은 주기적 사이클을 보인다고 보고했지만, LONR은 ‘후회 매칭(regret matching)’의 변형을 사용해 마지막 반복까지도 안정적인 정책을 유지한다. 이는 최근 GAN 훈련에서 관찰되는 ‘마지막 반복 수렴’ 문제와 연관된 흥미로운 현상이며, 함수 근사와 결합했을 때도 유사한 효과를 기대할 수 있다.
전체적으로 LONR은 CFR의 강력한 수렴 보장을 유지하면서, 완전 기억과 종료 상태라는 제한을 없애고, Q‑learning과 같은 강화학습 프레임워크와 자연스럽게 결합한다는 점에서 의미가 크다. 특히 다중 에이전트 환경에서 후회 최소화가 제공하는 견고함을 활용해, 기존 RL 알고리즘이 실패하던 상황에서도 안정적인 수렴을 달성한다는 점이 주목할 만하다.
댓글 및 학술 토론
Loading comments...
의견 남기기