강인한 음성 활동 검출을 위한 무감독 세그먼트 기반 rVAD
초록
본 논문은 두 단계의 잡음 억제와 피치(또는 스펙트럴 플랫니스) 기반 세그먼트 확장을 결합한 무감독 음성 활동 검출(rVAD) 방법을 제안한다. 고에너지 잡음 구간을 사전 제거하고, 두 번째 단계에서 일반적인 스펙트럼 서브트랙션을 적용한 뒤, 피치가 검출된 프레임을 묶어 음성 구간을 형성하고, 이를 확장하여 최종적으로 사후 SNR 가중 에너지 차이를 이용해 VAD를 수행한다. 또한 피치 검출을 스펙트럴 플랫니스로 대체한 경량 버전(rVAD‑fast)을 제시하여 계산량을 10배 가량 감소시켰다. RATS·Aurora‑2·RedDots 데이터베이스 실험에서 기존 방법들을 능가하는 성능을 보였다.
상세 분석
rVAD는 기존 무감독 VAD가 갖는 “음성 존재 가정”과 “프레임 선택 기반”의 한계를 극복하기 위해 세 가지 핵심 아이디어를 도입한다. 첫째, 사후 SNR 가중 에너지 차이(d(m))를 이용해 고에너지 구간을 빠르게 탐지한다. 이때 에너지 차이에 로그형 사후 SNR을 곱함으로써 비음성 구간에서는 값이 거의 0에 수렴하도록 설계하였다. 둘째, 탐지된 고에너지 구간 중 피치가 검출되지 않으면 해당 구간을 ‘고에너지 잡음’으로 판단하고 제로화(zero‑out)한다. 이는 burst‑type 잡음이 높은 에너지를 가지고 있어 일반적인 스펙트럼 서브트랙션만으로는 제거가 어려운 상황을 효과적으로 완화한다. 셋째, 두 번째 패스에서는 최소 통계(MSNE), MMSE, MCRA 등 다양한 잡음 추정 기법을 적용한 스펙트럼 서브트랙션을 수행해 남은 정적 잡음을 억제한다.
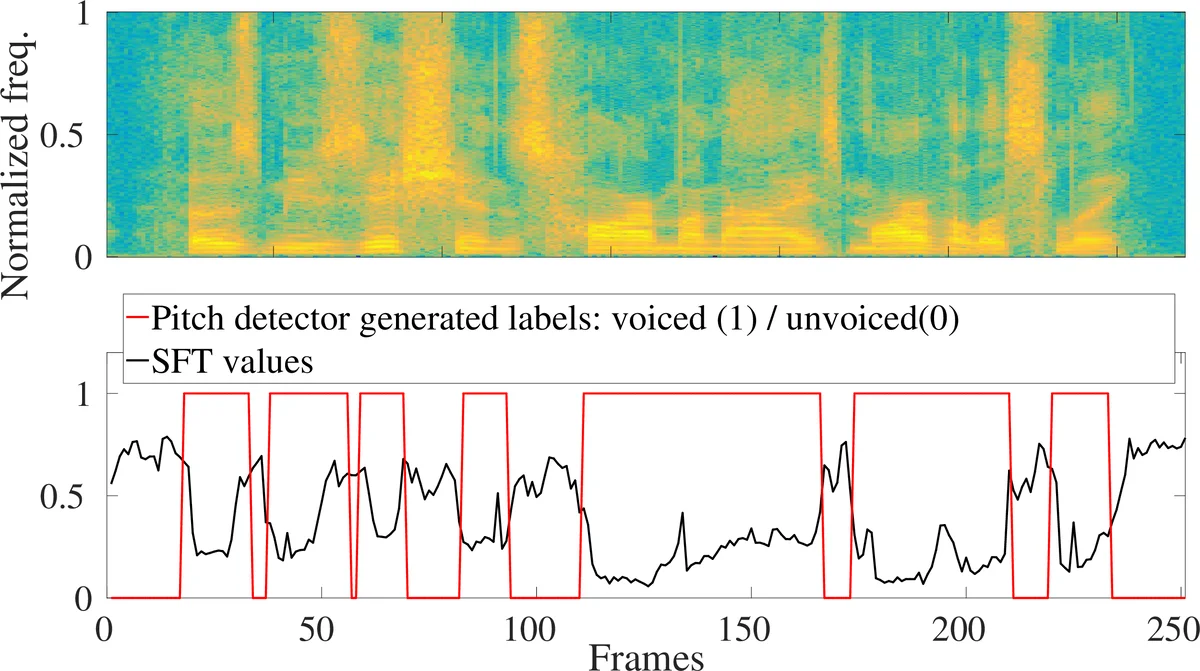
피치 기반 세그먼트 확장은 rVAD의 핵심이다. 프레임 단위 피치 검출 결과를 인접 프레임과 결합해 ‘피치 세그먼트’를 만든 뒤, 통계적 음성/비음성 경계값을 이용해 양쪽 끝을 확장한다. 이 과정에서 무음 구간, 무성음, 그리고 약한 비음성 구간까지 포함하도록 설계되어, 최종 VAD 판단에 필요한 최소한의 음성 정보를 확보한다. 확장된 세그먼트 내부에서는 다시 사후 SNR 가중 에너지 차이를 계산하고, 사전 정의된 임계값을 초과하는 프레임을 음성으로 판정한다.
계산 복잡도 측면에서 피치 검출은 가장 무거운 단계이며, 이를 스펙트럴 플랫니스(SFT)로 대체한 rVAD‑fast는 FFT 기반 플랫니스 계산만으로 피치와 유사한 존재 여부 판단을 가능하게 한다. 실험 결과 rVAD‑fast는 원본 rVAD 대비 약 10배 빠른 처리 속도를 보이며, VAD 정확도는 약 2~3% 정도만 감소한다는 트레이드오프를 제공한다.
성능 평가에서는 RATS와 Aurora‑2의 다양한 잡음 환경(정적·동적, SNR −5 ~ 20 dB)에서 DET 곡선, DCF, EER 등을 측정했으며, 기존 AFE, MFB, LTSV, 그리고 최신 딥러닝 기반 VAD와 비교해 전반적으로 우수한 결과를 얻었다. 또한 RedDots 2016 스피커 검증 데이터에 잡음(바이너리, 화이트, 카페 등)을 합성해 VAD 전처리 후 i‑vector 기반 스피커 검증을 수행했을 때, EER 감소 효과가 확인되었다.
요약하면, rVAD는 (1) 고에너지 잡음 사전 제거, (2) 두 단계 잡음 억제, (3) 피치(또는 플랫니스) 기반 세그먼트 확장, (4) 사후 SNR 가중 에너지 차이 기반 최종 판단이라는 네 단계 파이프라인을 통해 무감독 상황에서도 높은 잡음 강인성을 확보한다. 공개된 MATLAB·Python 구현과 함께 연구 재현성이 뛰어나며, 저전력 디바이스나 대규모 배치 처리에 적합한 경량 버전도 제공한다.
댓글 및 학술 토론
Loading comments...
의견 남기기