WaveRange를 활용한 3차원 시뮬레이션 데이터 고효율 파형렛 압축
초록
WaveRange는 3차원 정규 격자에 저장된 부동소수점 데이터를 대상으로, CDF 9/7 파형렛 변환, 양자화, 그리고 엔트로피 기반 레인지 코딩을 결합한 손실 압축 방식을 제공한다. 변환 단계에서 다중 레벨(기본 4레벨) 파형렛 계수를 생성하고, 사용자가 지정한 재구성 오차 한계에 맞춰 양자화 스텝을 자동 조정한다. 압축률은 데이터 종류와 허용 오차에 따라 10배 이상까지 달성되며, 복원 시 원본과의 차이는 지정된 L∞ 혹은 L2 기준을 만족한다. 소스 코드는 GPL‑3.0 라이선스로 공개돼 C/C++ 환경에서 독립 실행형 프로그램 혹은 라이브러리 형태로 활용 가능하다.
상세 분석
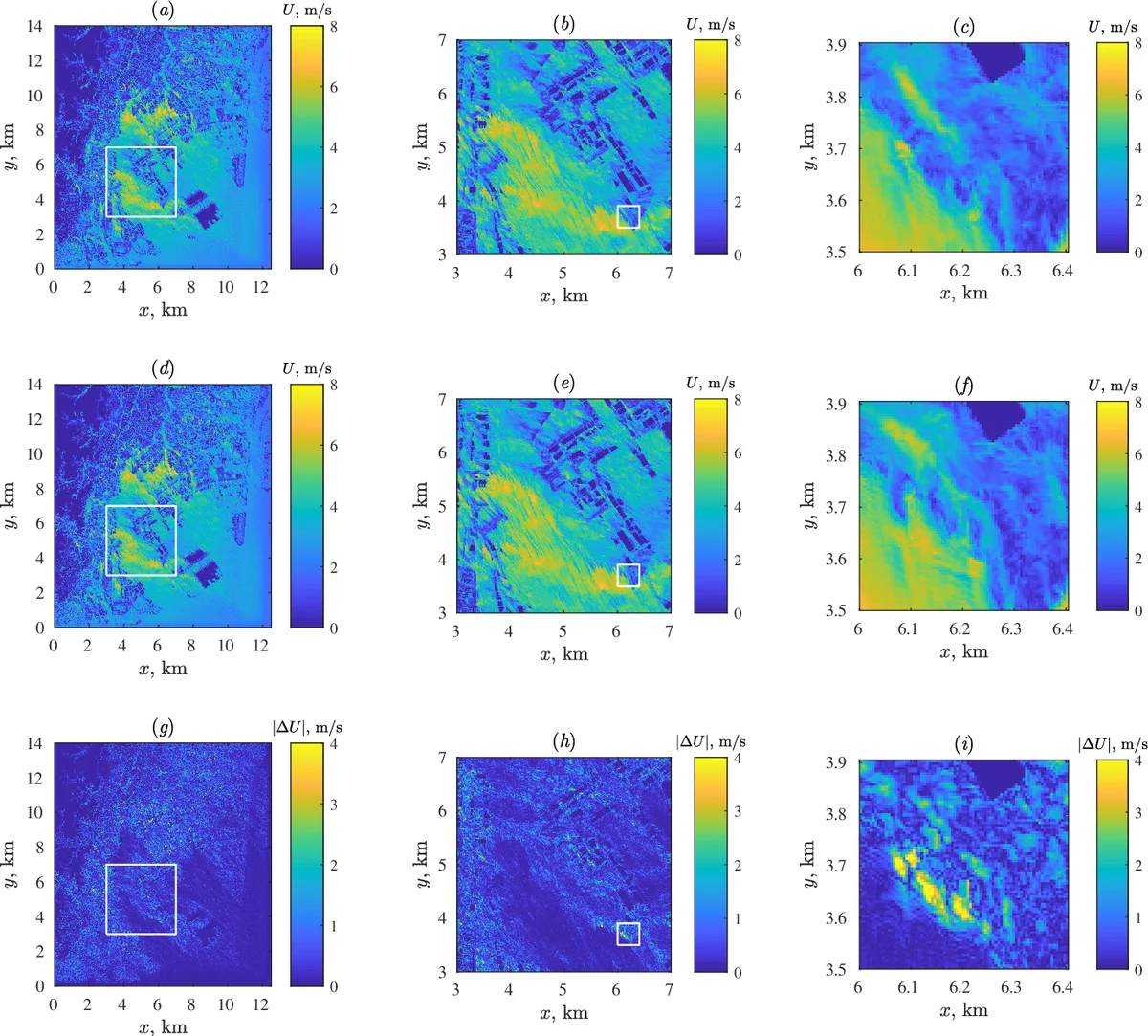
본 논문은 대규모 과학·공학 시뮬레이션에서 발생하는 테라바이트 규모의 3차원 부동소수점 데이터를 효율적으로 저장·전송하기 위한 전용 압축 프레임워크인 WaveRange를 제안한다. 핵심 알고리즘은 세 단계로 구성된다. 첫 번째는 3차원 다중해상도 파형렛 변환으로, 저자들은 CDF 9/7(코헨‑다우베시) 파형렛을 선택하였다. 이 파형렛은 lifting scheme 기반으로 구현되며, 1차원 변환을 x, y, z 축 순서대로 적용하고, 변환 결과의 저해상도(approximation) 계수를 다음 레벨 입력으로 재사용한다. 논문에서는 변환 레벨을 4로 고정했으며, 이는 전체 데이터의 약 4 %만이 최종 저해상도 계수로 남아 압축 효율을 크게 높인다. 파형렛 변환은 메모리 제자리(in‑place) 방식으로 수행돼 추가 메모리 오버헤드가 최소화된다.
두 번째 단계는 양자화이다. 저자들은 사용자가 지정한 재구성 오차(예: L∞ ≤ ε)와 파형렛 계수의 통계적 분포를 기반으로 동적 스케일링을 적용한다. 구체적으로, 각 레벨·세부계수(detail coefficient)에 대해 동일한 양자화 스텝을 사용하되, 전체 데이터의 최대 절대값을 기준으로 스텝 크기를 결정한다. 이 방식은 압축률과 정확도 사이의 트레이드오프를 사용자가 직관적으로 제어할 수 있게 한다.
세 번째는 엔트로피 코딩으로, 저자들은 범위 코딩(range coding)을 채택하였다. 이는 Huffman 코딩보다 높은 압축 효율을 제공하면서도 구현 복잡도가 비교적 낮다. 양자화된 정수 계열을 입력으로 하여, 실제 사용된 심볼(양자화 값)의 발생 빈도에 따라 가변 길이 코드를 생성한다.
성능 평가에서는 이상적인 정규 격자 테스트부터 실제 지구과학(대기·해양) 전역 시뮬레이션까지 다양한 사례를 다루었다. 압축률은 데이터의 스무스 정도와 허용 오차에 따라 8배~30배에 달했으며, 재구성 오차는 지정한 ε 이하로 유지되었다. 특히 재시작 파일에 대한 압축은 오차가 시뮬레이션 결과에 미치는 영향을 정량화했으며, 허용 오차 범위 내에서는 재시작 후 시뮬레이션이 원본과 거의 동일한 궤적을 보였다.
컴퓨팅 비용 측면에서는 변환·양자화·코딩 전체가 O(N) 복잡도를 가지며, 멀티코어 환경에서 OpenMP 기반 병렬화를 적용해 데이터 1 GB당 압축·복원 시간이 2~5초 수준으로 보고되었다. 이는 기존 LZMA와 같은 무손실 압축기 대비 10배 이상 빠른 속도와, 손실 압축기 대비 높은 정확도를 동시에 제공한다는 점에서 실용적이다.
마지막으로, WaveRange는 GPL‑3.0 라이선스로 공개돼 C/C++ API와 독립 실행형 바이너리를 제공한다. 입력 포맷은 Fortran/C 배열, FluSI, MSSG 등 다양한 과학 코드에서 직접 생성되는 바이너리 형태를 지원한다. 또한, 압축·복원 파라미터(레벨, 허용 오차, 양자화 스텝 등)를 명령행 옵션으로 지정할 수 있어, 사용자는 워크플로우에 맞게 손쉽게 튜닝할 수 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기