BERTphone 발음 인식과 화자 언어 인식을 위한 다목적 Transformer 인코더
초록
BERTphone은 대규모 음성 코퍼스를 이용해 두 가지 목표(프레임 마스킹 복원과 CTC 기반 음소 예측)를 동시에 학습한 Transformer 인코더이다. 사전학습된 모델을 고정된 특징 추출기로 사용해 x‑vector 스타일 DNN에 입력하면 화자 인식에서는 평균 18 %의 EER 감소, 언어 인식에서는 LRE07 3초 폐쇄형 과제에서 Cavg 6.16이라는 최첨단 성능을 달성한다.
상세 분석
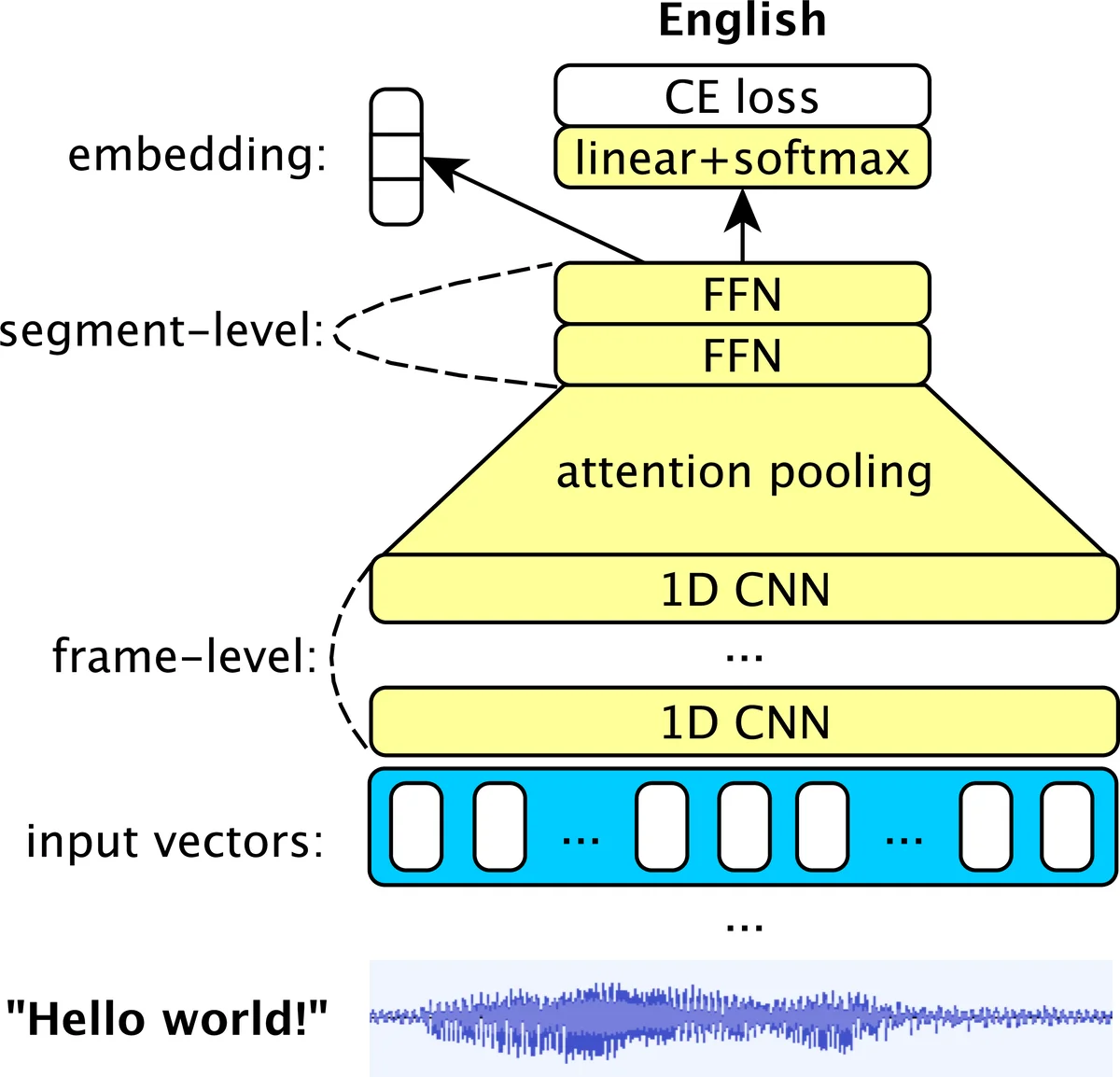
본 논문은 음성 신호를 연속적인 입력으로 받아들인 뒤, BERT와 유사한 양방향 Transformer 인코더에 두 개의 상보적인 사전학습 목표를 부여한다. 첫 번째 목표는 입력 MFCC 시퀀스의 5 % 위치에서 길이 3(스택된 3프레임, 즉 약 100 ms)인 연속 구간을 0으로 마스킹하고, 전체 프레임을 L1 손실로 복원하도록 학습한다. 이는 스펙오거멘트 기반 마스킹을 확장한 것으로, 프레임 간 높은 상관성을 고려해 스팬 마스킹을 적용함으로써 모델이 장기적인 음향 패턴을 포착하도록 유도한다. 두 번째 목표는 CTC 손실을 이용해 각 프레임에 대응하는 음소 라벨을 예측하도록 하는 것이다. 음소 라벨은 CMUdict에서 추출한 39개의 비정지 심볼이며, 강제 정렬 없이 순차적 확률을 최적화한다. 두 손실은 λ 파라미터로 가중합되며, 재구성 손실은 √T 로 스케일링해 시퀀스 수준 손실과 균형을 맞춘다.
모델 구조는 BERT‑base와 동일하게 12개의 self‑attention 레이어, d_model = 768, d_ff = 3072, 헤드 수 12를 사용한다. 입력은 평균‑정규화된 40‑dim MFCC에 3프레임을 스택해 차원을 120으로 늘린 뒤, 포지션 임베딩을 더한다. 사전학습은 8 kHz Fisher와 16 kHz TED‑LIUM 두 데이터셋에 각각 별도 모델을 학습함으로써, 샘플링 레이트 차이에 따른 특성을 보존한다.
사전학습된 인코더의 최종 레이어 출력을 고정하고, 이를 프레임‑레벨 특징으로 활용해 x‑vector와 유사한 구조의 DNN에 입력한다. 여기서는 5개의 1‑D CNN 레이어와 다중 헤드 self‑attention pooling(SAP)을 적용해 시간적 중요도를 학습한다. 화자 인식에서는 최종 임베딩을 PLDA로 비교하고, 언어 인식에서는 softmax를 직접 사용한다.
실험 결과, Fisher‑to‑Fisher 화자 인식에서 기존 phonetic‑multitask 모델보다 EER이 1.39 %→1.23 %로 개선되었으며, 대규모 VoxCeleb에서는 18 % 상대적 EER 감소를 기록한다. 언어 인식에서는 LRE07 3 초 폐쇄형 과제에서 Cavg 6.16을 달성해 이전 최고 기록을 크게 앞선다. 손실 가중치 λ와 레이어 파인튜닝, grapheme‑CTC 등 다양한 변형을 탐색했으며, λ≈0.5가 가장 안정적인 성능을 제공한다는 점을 확인한다.
이러한 결과는 음성 신호에 대한 고차원 음향·음소 정보를 동시에 학습한 사전학습 모델이, 별도 fine‑tuning 없이도 화자와 언어 인식이라는 서로 다른 다운스트림 과제에 효과적으로 전이될 수 있음을 보여준다. 또한, 기존 ASR‑bottleneck 특성보다 더 풍부한 표현력을 제공함으로써, 향후 음성 인식, 감정 분석 등 다양한 음성 처리 분야에 활용 가능성을 시사한다.
댓글 및 학술 토론
Loading comments...
의견 남기기