진화와 강화학습으로 최적 열역학 경로 찾기
초록
본 연구는 신경망 기반 강화학습을 이용해 모델 열기관의 효율을 최대화하는 최적 열역학 경로를 자동으로 탐색한다. 진화적(gradient‑free) 알고리즘과 정책 경사(gradient‑based) 학습 두 방식을 비교하며, 진화적 방법은 카르노, 스털링, 오토 사이클을 재현하고 새로운 비가역 사이클까지 발견한다. 정책 경사 학습은 스털링 사이클을 학습하지만 카르노 사이클에 도달하지 못한다. 결과는 게임용 강화학습 기법이 경로‑종속 물리량을 최적화하는 물리 문제에도 적용 가능함을 보여준다.
상세 분석
이 논문은 열역학적 효율이라는 경로‑종속(패스‑익스텐시브) 물리량을 최적화 목표로 삼아, 강화학습(RL) 프레임워크를 물리 시스템에 적용한 최초 사례 중 하나이다. 모델 열기관은 단일 원자성 이상기체를 가변 부피 용기에 담아, 고온·저온 저장소와 연결된 형태로 설정된다. 시스템 상태는 부피 V와 온도 T의 두 차원 벡터 sₜ=(V,T) 로 표현되며, 각 시점마다 신경망 정책 π_θ(a|s) 가 가능한 열역학적 기본 동작 a∈{압축, 팽창, 등온, 단열, 등적 가열·냉각} 중 하나를 선택한다. 선택된 동작은 즉시 새로운 상태 sₜ₊₁을 생성하고, 그 과정에서 일 ΔW와 열 ΔQ가 계산된다. K=200 단계의 고정 길이 궤적 ω에 대해 전체 효율 η_K = ΣΔW / ΣΔQ_in 로 정의하고, 이를 최적화 목표로 삼는다.
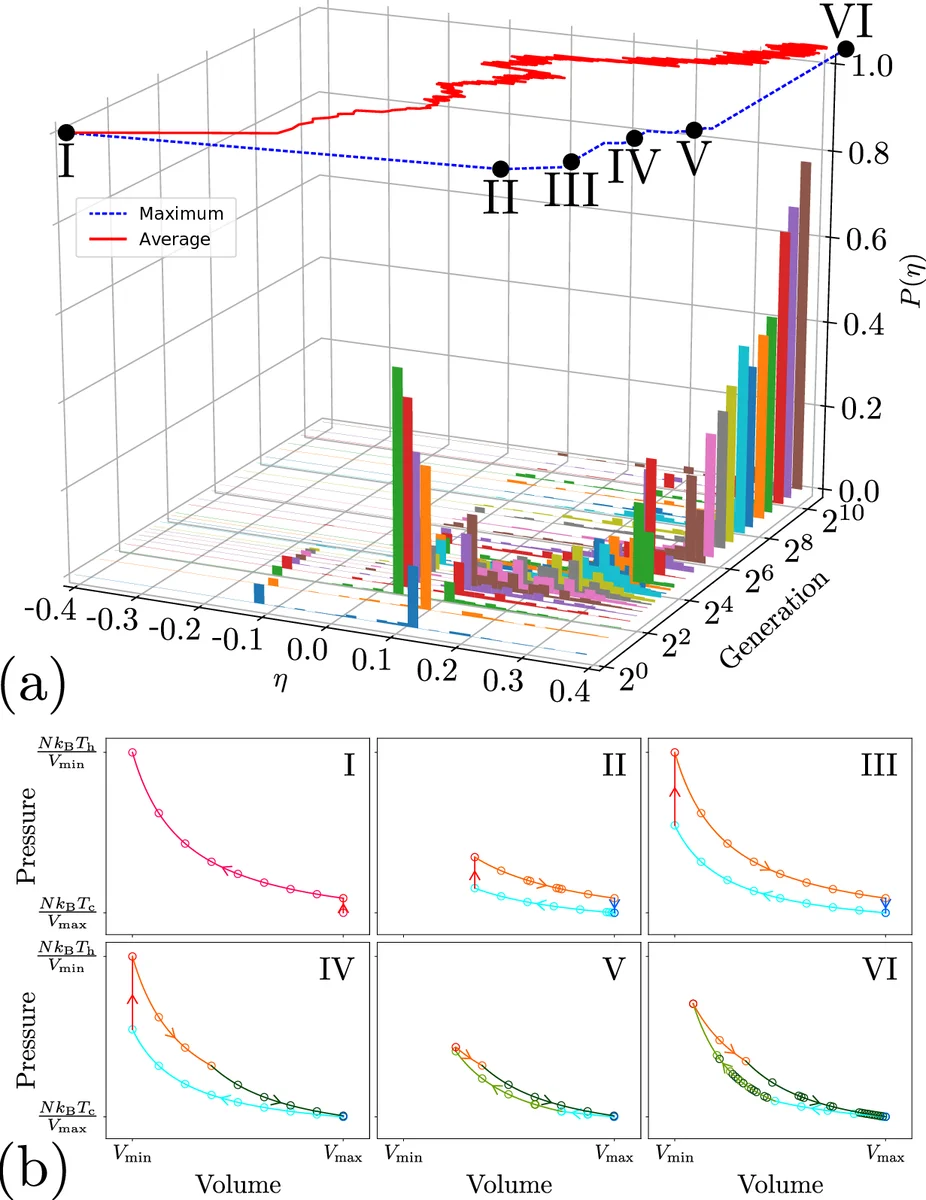
진화적 학습은 100개의 신경망을 초기화한 뒤, 효율이 높은 상위 25%를 선택하고, 선택된 네트워크에 가우시안 잡음(σ=0.05)을 가해 75개의 자손을 생성한다. 이 과정을 수백 세대 반복하면, 효율 분포 P(η) 가 카르노 효율 η_max=1−T_c/T_h 에 수렴한다. 진화 과정에서 네트워크는 자연스럽게 폐곡선(사이클) 형태의 궤적을 학습한다. 이는 사이클이 비사이클보다 평균 효율이 높기 때문이며, 네트워크가 “사이클을 유지하는 정책”을 스스로 발견한다는 의미다. 또한, 허용된 동작 집합을 제한하면(예: 단열을 제외) 스털링 사이클이나 오토 사이클을 최적해로 학습한다. 흥미롭게도, 비가역 동작을 추가했을 때는 기존 이론에 없던 새로운 사이클을 발견한다는 점에서 물리적 통찰을 제공한다.
정책 경사 기반 학습은 동일한 환경에 대해 REINFORCE‑type 알고리즘을 적용한다. 여기서는 두 개의 추가 입력 노드가 온도와 부피의 스케일링 값을 제공하고, 보상은 각 단계의 즉시 효율이 아니라 전체 궤적 효율 η_K 로 정의한다. 정책 파라미터 θ는 로그 확률의 그라디언트를 보상에 곱해 업데이트된다. 실험 결과, 이 방식은 스털링 사이클을 어느 정도 재현하지만, 카르노 사이클처럼 연속적인 등온·단열 구간을 정확히 맞추지는 못한다. 이는 정책 그라디언트가 고차원 연속 행동 공간에서 미세한 최적화를 수행하기엔 샘플 효율이 낮고, 특히 효율이라는 전역 보상이 희소하게 나타나기 때문으로 해석된다.
논문은 또한 효율을 부피 비율 V_r이나 온도 비율에 대한 함수로 해석해, 전통적인 열역학식(η_Carnot, η_Stirling, η_Otto 등)과 학습된 사이클의 효율을 정량적으로 비교한다. 진화적 방법은 이론적 최적값에 4자리 소수점까지 도달했으며, 학습된 사이클의 P‑V 궤적은 교과서적인 형태와 거의 일치한다. 반면 정책 그라디언트는 수렴 속도가 느리고, 최적값에 근접하지만 약간의 편차가 남는다.
이 연구는 (1) 강화학습이 물리적 경로‑종속 최적화 문제에 적용 가능함을, (2) 진화적 무그라디언트 방식이 전통적인 최적 제어보다 더 강건하게 전역 최적해를 찾을 수 있음을, (3) 새로운 물리적 사이클을 탐색하는 데 있어 기계학습이 실험적·이론적 탐구를 보완할 수 있음을 보여준다. 향후에는 다중 열원·복합 시스템, 비정상 상태 열역학, 혹은 양자 열기관 등에 동일한 프레임워크를 확장함으로써, 인간이 직접 도출하기 어려운 최적 프로토콜을 자동으로 설계하는 길을 열 수 있을 것으로 기대된다.
댓글 및 학술 토론
Loading comments...
의견 남기기