페이지 수준 버퍼링으로 NVM LLC 읽기 지연 숨기기
초록
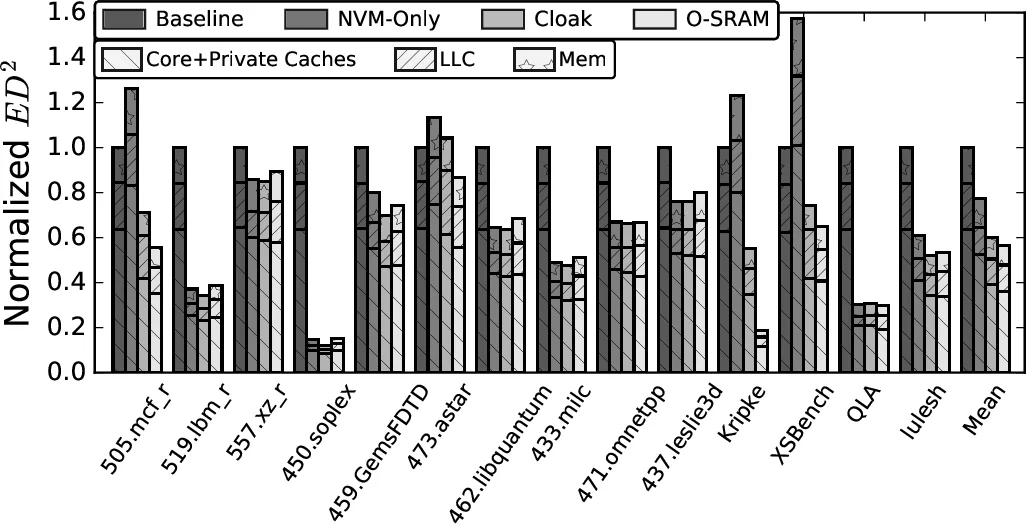
Cloak은 L1 TLB 재충전 시 페이지 단위로 NVM 기반 LLC에 남아 있는 캐시 라인을 작은 SRAM 페이지 버퍼로 복사해, 이후 동일 페이지에 대한 접근을 버퍼에서 빠르게 처리함으로써 NVM 읽기 지연을 가려낸다. 새로운 LLC 레이아웃과 적응형 교체 정책을 결합해 면적 비용은 거의 늘리지 않으면서 SRAM LLC 대비 23.8 %, 순수 NVM LLC 대비 8.9 %의 성능 향상을 달성한다.
상세 분석
본 논문은 기존 연구가 주로 NVM의 쓰기 지연을 완화하는 데 초점을 맞춘 반면, 실제 시스템에서 가장 병목이 되는 NVM 읽기 지연을 간과하고 있음을 지적한다. 이를 해결하기 위해 제안된 Cloak은 두 가지 핵심 아이디어를 결합한다. 첫째, 페이지 수준의 재사용 패턴을 활용한다. L1 데이터 TLB가 페이지를 다시 채우는 순간, 해당 페이지가 과거에 LLC에 존재했을 가능성이 높다는 통계적 근거를 제시하고, 이때 페이지에 속한 모든 라인을 한 번에 탐색·복사한다. 둘째, 복사된 라인을 보관할 SRAM 기반 페이지 버퍼(Page Buffer, PB)를 도입한다. PB는 동일 페이지의 라인들을 물리적으로 인접한 행에 배치한 새로운 LLC 데이터 레이아웃 덕분에 고대역폭 전송이 가능하며, NVM 배열에 대한 파이프라인이 불가능한 특성을 보완한다.
Cloak의 동작 흐름은 다음과 같다. L1 TLB 미스가 발생하면, 페이지 테이블 엔트리(PTE)의 Accessed/Dirty 비트를 확인해 과거 접근 여부를 판단한다. 페이지가 이전에 사용된 적이 있으면, LLC 컨트롤러는 해당 페이지의 라인들을 빠르게 찾아 PB에 복사한다. 복사 과정에서 페이지 라인들을 동일 물리 행에 모아 두어 탐색 비용을 최소화한다. 이후 동일 페이지에 대한 메모리 요청은 먼저 PB를 조회하고, 히트 시 SRAM에서 즉시 응답한다; 미스 시에는 기존 NVM 배열을 접근한다.
또한, 페이지 버퍼의 교체 정책은 페이지 재사용 빈도와 현재 버퍼 점유율을 고려한 적응형 방식으로 설계되어, 버퍼 활용률을 최적화한다. 실험은 4코어 시스템에 14가지 워크로드를 적용했으며, 평균적으로 SRAM 기반 LLC 대비 23.8 %의 성능 향상, 순수 NVM LLC 대비 8.9 %의 향상을 기록했다. 에너지‑지연 곱(ED²) 역시 각각 39.9 %와 17.5 % 감소하였다. 면적 증가는 미미한 수준으로, 기존 설계에 쉽게 통합될 수 있다.
이 설계는 페이지 재사용을 전제하므로, 페이지 수준의 지역성이 낮은 워크로드에서는 효과가 제한될 수 있다. 또한, PB의 크기와 수를 어떻게 설정하느냐에 따라 면적·전력 트레이드오프가 존재한다. 그럼에도 불구하고, NVM 기반 대용량 LLC에서 읽기 지연을 숨기는 실용적인 방법을 제시한 점은 큰 의의가 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기