시간을 가르는 다익스트라: 결정적 워크로드를 위한 사전 스케줄링 기법
초록
본 논문은 머신러닝 가속기용 결정적 워크로드에 대해, 시스템 상태를 시간축으로 확장한 그래프에 다익스트라 알고리즘을 적용해 사전(compute‑time) 데이터 이동과 연산 스케줄을 최적화하는 “Dijkstra‑Through‑Time”(DTT) 방식을 제안한다. 배치 단계와 라우팅 단계로 구성된 두 단계 파이프라인을 통해 복잡한 NoC 토폴로지도 지원하지만, 컴파일 시간이 길어지는 트레이드오프가 있다. 간단한 파이썬 프로토타입과 사례 연구를 통해 데이터 재사용·캐시 일관성 없이도 효율적인 데이터 흐름을 달성함을 보인다.
상세 분석
DTT는 “푸시 흐름”을 전제로, 프로그램이 완전히 결정적일 때(조건 분기가 없고 데이터 의존성이 사전에 알려진 경우) 모든 PE가 필요로 하는 데이터를 미리 계산된 스케줄에 따라 전송하도록 설계되었다. 핵심 아이디어는 시간‑확장 스케줄링 그래프를 구성하고, 각 데이터 이동을 그래프상의 경로로 모델링한 뒤, 다익스트라 최단경로 알고리즘을 이용해 가장 빠른 전송 시퀀스를 찾는 것이다. 이 과정은 두 단계로 나뉜다.
첫 번째 ‘배치(Placing)’ 단계에서는 연산을 수행할 Actor(예: MAC 배열)를 선택한다. 논문에서는 간단히 “First‑Best‑Fit” 휴리스틱을 사용했으며, 여기서는 데이터가 이미 캐시된 정도를 affinity 함수로 활용한다. 배치 단계는 라우팅 단계보다 훨씬 가벼운 연산으로, 전체 스케줄링 품질에 큰 영향을 미치지만 최적해를 보장하지는 않는다.
두 번째 ‘라우팅(Routing)’ 단계에서는 실제 데이터 이동 경로를 찾는다. 각 Node(메모리, 레지스터, PE 등)는 사이클별 히스토리를 유지하고, Wire는 물리적 혹은 가상(대기) 연결을 나타낸다. 다익스트라 알고리즘은 (Node, cycle) 형태의 복합 노드를 탐색하면서, 버스 대역폭, 지연, 현재 사용 상황 등을 비용 함수에 반영한다. 결과적으로 데이터가 목표 시점에 정확히 도착하도록 최소 비용 경로가 선택된다.
논문은 간단한 4 KB SRAM‑레지스터‑멀티플라이어 구조와 복합 NoC 토폴로지를 가진 예시 하드웨어에 대해 단계별 시뮬레이션을 수행한다. 배치 결과는 연산을 수행할 PE와 입력 데이터를 매핑하고, 라우팅 결과는 DRAM→SRAM→레지스터→PE 순서의 전송 타임라인을 상세히 제시한다. 특히, 동일 데이터가 여러 연산에 재사용될 경우, DTT는 이미 캐시된 위치에서 직접 가져오도록 자동 최적화한다는 점이 눈에 띈다.
핵심 장점은 (1) 전통적인 캐시 일관성 프로토콜을 배제하고도 데이터 일관성을 보장한다는 점, (2) 복잡한 NoC 구조와 다양한 버스 대역폭을 정밀히 모델링할 수 있다는 점, (3) 연산 간 데이터 재사용을 전역적으로 고려함으로써 메모리 트래픽을 크게 감소시킨다. 반면 한계점으로는 (a) 결정적 워크로드에만 적용 가능하므로 일반적인 딥러닝 모델(조건부 연산, 동적 라우팅 등)에는 부적합, (b) 시간‑확장 그래프가 사이클 수와 노드 수에 따라 급격히 커져 컴파일 시간이 비선형적으로 증가한다는 점, (c) 현재 구현이 파이썬 프로토타입 수준이라 실제 하드웨어 설계 흐름에 바로 통합하기엔 성능·스케일링 측면에서 추가 연구가 필요하다.
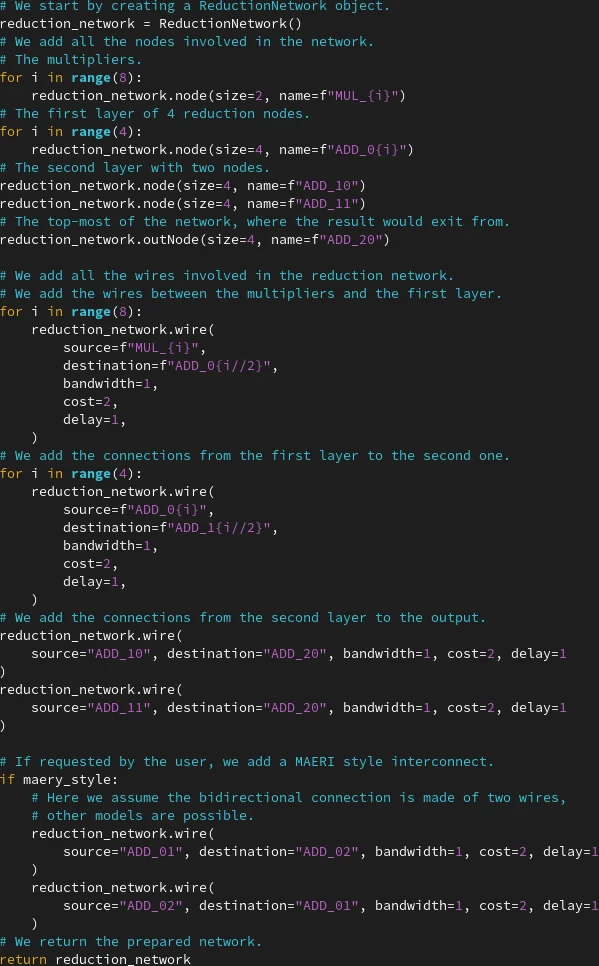
또한, 논문은 감소 네트워크(리덕션 트리)와 같은 역방향 데이터 흐름에도 DTT를 적용하는 방법을 제시한다. 여기서는 결과를 “배포”하는 대신, 가상의 배포 과정을 역으로 시뮬레이션하고 라우팅을 수행함으로써, 복합 가산기 구조의 병목을 사전에 탐지하고 설계 옵션(예: 증강 연결)의 에너지·성능 영향을 정량화할 수 있다. 이러한 활용은 하드웨어 설계 단계에서 다양한 토폴로지를 빠르게 비교 평가하는 프로토타이핑 백엔드로서의 가능성을 보여준다.
전반적으로 DTT는 기존 컴파일러 기반 데이터 흐름 최적화가 놓치는 “시간적” 제약을 그래프 탐색으로 보완하고, 하드웨어‑소프트웨어 공동 설계(co‑design) 관점에서 새로운 스케줄링 패러다임을 제시한다. 향후 연구에서는 (i) 비결정적 요소를 포함한 하이브리드 스케줄링, (ii) 대규모 NoC와 수천 개 PE를 대상으로 한 스케일링 최적화, (iii) 하드웨어 구현을 위한 RTL/FPGA 프로토타입과 실측 벤치마크가 필요할 것이다.
댓글 및 학술 토론
Loading comments...
의견 남기기