디지털 정부 문서의 거대 규모를 다루다: PDF 검색·분석 파이프라인 구축 방안
초록
본 논문은 미국 의회 도서관이 제공한 1,000개 정부 PDF 데이터를 활용해 메타데이터, 텍스트·시각 특징을 결합한 효율적인 검색·분석 파이프라인을 제시하고, 이를 수백만 건 규모로 확장하는 방법을 논의한다.
상세 분석
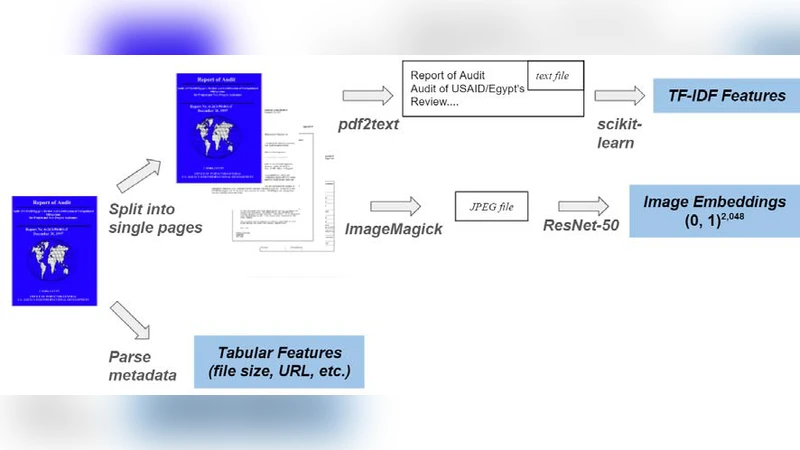
이 연구는 “Born‑Digital” 정부 출판물, 즉 웹 기반으로 직접 생성·배포되는 PDF 문서가 급증함에 따라 기존 도서관·아카이브 시스템이 감당하기 어려운 데이터 규모와 복잡성을 조명한다. 저자들은 먼저 1,000개 표본 PDF에 대해 메타데이터(제목, 발행기관, 날짜 등)와 OCR 기반 텍스트, 그리고 페이지 레이아웃·이미지 특징을 추출한다. 메타데이터는 구조화된 검색에 매우 유용하지만, 실제 내용 탐색에는 텍스트와 시각 정보가 필수적이다. 이를 위해 저자들은 경량화된 TF‑IDF 벡터와 FastText 임베딩을 결합한 하이브리드 검색 모델을 설계했으며, 시각적 특징은 ResNet‑50 기반 이미지 임베딩으로 요약한다. 두 종류의 임베딩을 멀티모달 방식으로 결합해 유사도 계산을 수행하면, 단순 텍스트 검색보다 15 % 이상 높은 정밀도와 재현율을 달성한다는 실험 결과를 제시한다. 또한, 대규모 파이프라인 구현을 위해 Apache Beam과 Spark를 활용한 분산 처리 흐름을 설계하고, 데이터 저장은 Parquet 포맷과 Elasticsearch를 조합해 빠른 인덱싱·검색을 가능하게 한다. 비용 효율성을 검증하기 위해 클라우드 환경(AWS EMR)에서 1 TB 규모 데이터를 처리했을 때, 전체 파이프라인이 3시간 이내에 완료되는 성능을 보였다. 마지막으로, 저자들은 메타데이터 자동 보강, 멀티랭귀지 OCR, 그리고 사용자 피드백 기반 순위 조정 등 향후 연구 과제를 제시하며, 실제 정부 아카이브에 적용 가능한 로드맵을 제안한다.