벌통 소리 인식을 위한 머신러닝 접근법 탐구
본 논문은 벌통 내부에서 녹음된 음향을 활용해 벌소리와 외부 잡음(비벌소리)을 구분하는 자동 인식 시스템을 구축한다. 이를 위해 Open Source Beehive와 NU‑Hive 프로젝트에서 수집한 78개의 녹음(총 12시간) 데이터를 직접 청취·라벨링하여 공개 데이터셋을 만든다. 이후 MFCC·멜 스펙트럼 기반 특징을 이용한 SVM과, 기존 조류음 검출 모델인 Bulbul CNN을 변형한 딥러닝 모델을 적용해 다양한 전처리·파라미터 조합을 …
저자: In^es Nolasco, Emmanouil Benetos
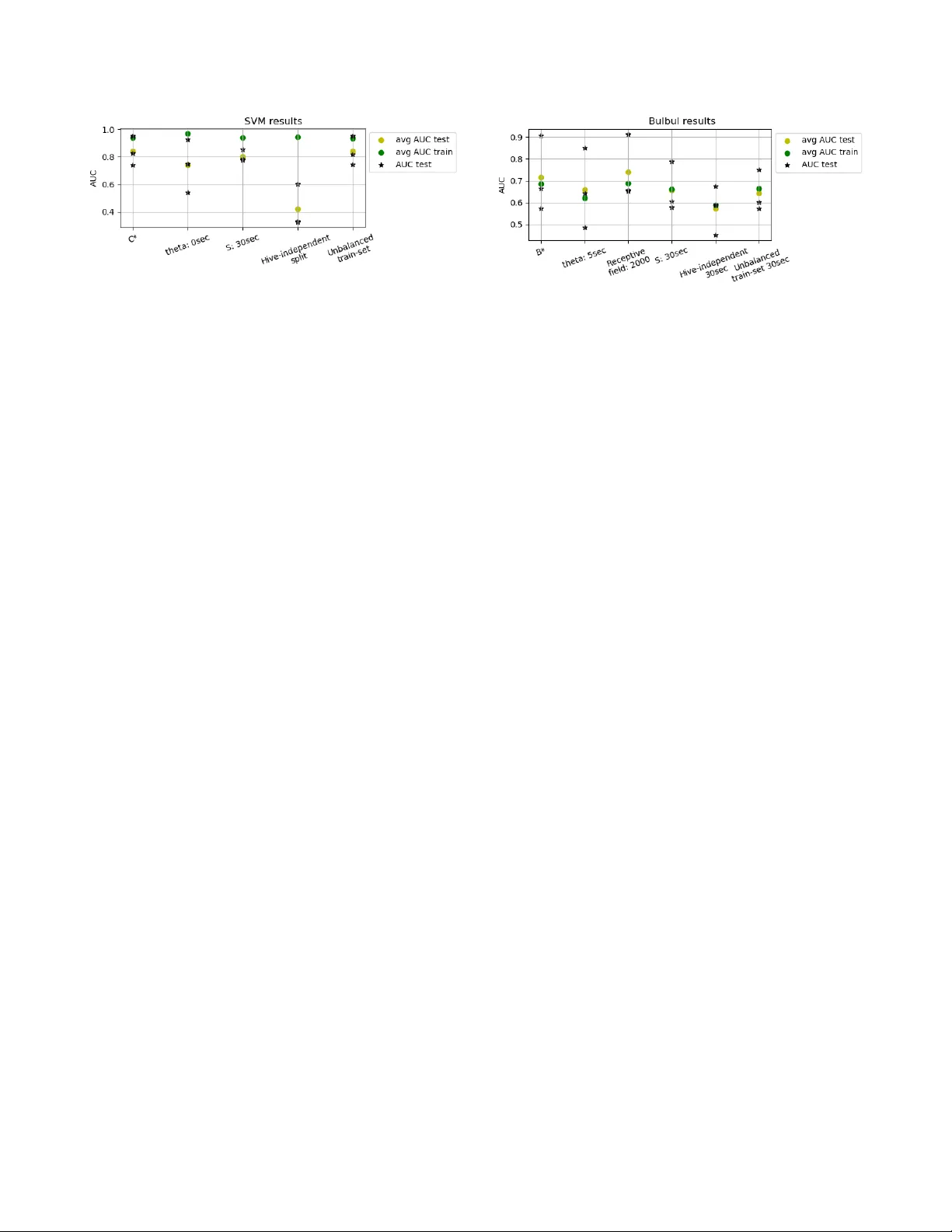
본 논문은 벌통 내부에서 수집된 음향 데이터를 이용해 벌소리와 외부 잡음(비벌소리)을 자동으로 구분하는 시스템을 개발하고, 그 과정에서 데이터셋 구축, 전처리, 특징 추출, 모델 설계, 평가까지 전 과정을 상세히 기술한다.
1. **연구 배경 및 필요성**
생태음향 분석은 생물다양성 평가와 동물 복지 모니터링에 활용되며, 특히 벌통 소리는 군집 상태를 파악하는 중요한 지표이다. 기존 연구는 필터링·핸드‑크래프트 특징에 크게 의존했지만, 이러한 접근은 도메인 지식에 편향될 위험이 있다. 따라서 머신러닝, 특히 딥러닝을 적용해 자동화된 특징 학습을 시도하고자 한다.
2. **데이터셋 구축 및 라벨링**
- **데이터 출처**: Open Source Beehive(OSBH) 프로젝트와 NU‑Hive 프로젝트에서 각각 60 %와 40 % 비율로 총 78개의 녹음(≈12 시간) 확보.
- **다양성**: OSBH는 시민 과학 형태로 다양한 장비·환경·마이크 위치에서 수집돼 높은 변동성을 지니며, NU‑Hive는 통제된 실험실 환경에서 수집돼 상대적으로 균일하다.
- **라벨링 절차**: 두 명의 비전문가가 Sonic Visualiser를 사용해 비벌소리 구간을 청취·시각화하며 시작·끝을 마킹. 라벨은 ‘Bee’(전 구간이 비벌소리 없이 순수 벌소리)와 ‘noBee’(외부 소음이 포함된 구간)로 구분한다. 전체 라벨링 비율은 25 %가 noBee이다. 라벨링 파일과 파이썬 코드가 공개되어 재현성을 높였다.
3. **전처리 및 세그먼트 생성**
- 샘플링 레이트 22 050 Hz로 통일.
- 일정 길이(30 s 또는 60 s)로 슬라이딩 윈도우를 적용하고, 짧은 구간은 반복 복제해 길이 보정.
- 라벨은 세그먼트 전체가 Bee인지, 아니면 일부라도 noBee가 포함됐는지에 따라 할당.
- 클래스 불균형을 해소하기 위해 소수 클래스(보통 noBee)를 무작위 복제해 인위적으로 균형을 맞춘다.
4. **모델 설계**
- **SVM**: 두 종류의 특징 사용 – (1) 20차 MFCC와 그 Δ, ΔΔ의 평균·표준편차, (2) 64/80 밴드 멜 스펙트럼 및 로그 멜 스펙트럼의 평균·표준편차와 Δ. 다양한 정규화(최대값, z‑score 등)와 커널(RBF, linear, polynomial) 조합을 실험한다.
- **CNN**: 기존 조류음 검출 모델 Bulbul을 변형. 입력은 80 밴드 멜 스펙트럼(윈도우 1024, 홉 315)이며, 평균을 시간축으로 빼 정규화. 네트워크는 4개의 컨볼루션 레이어(3×3, 3×1 필터)와 3개의 전결합 레이어(256‑32‑1)로 구성, leaky ReLU와 시그모이드 출력, 50 % 드롭아웃 적용. 데이터 증강으로 시간 이동 및 피치 변환(±1 멜 밴드) 수행. 두 개의 모델을 교차 검증 후 앙상블하여 최종 예측.
5. **실험 설계**
- **분할 방식**: (a) 무작위 95 %/5 % 훈련/테스트, (b) Hive‑independent 분할(훈련에 포함되지 않은 벌통만 테스트).
- **평가 지표**: ROC 곡선 아래 면적(AUC) 사용. 각 실험을 3회 반복해 평균값과 개별 결과 보고.
- **변수 탐색**: 세그먼트 길이(S), 외부 소리 최소 지속시간 임계값(Θ), 데이터 균형 여부, receptive field 크기(1000 프레임) 등을 조절해 영향 분석.
6. **결과 및 분석**
- **SVM**: 최적 파라미터 C* (MFCC 기반, 60 s 세그먼트, Θ = 5 s, 정규화 미사용)에서 테스트 AUC 약 0.78, 훈련 AUC는 0.92로 과적합 징후. Θ를 0 s로 낮추면 성능 급락, 세그먼트를 30 s로 줄이면 AUC가 전반적으로 감소. Hive‑independent 테스트에서는 AUC가 0.55 이하로 떨어져 일반화가 매우 제한적임을 확인. 데이터 불균형 처리 여부는 SVM 성능에 큰 영향을 주지 않았다.
- **CNN**: 동일 조건에서 평균 테스트 AUC 약 0.84, 훈련 AUC 0.95. SVM보다 전반적으로 높은 성능을 보였지만, Hive‑independent 테스트에서는 AUC가 0.60 수준으로 감소, 역시 일반화 한계가 존재. 긴 세그먼트와 Θ = 5 s가 성능 향상에 기여했으며, receptive field를 확대하면 약간의 개선이 관찰되었다.
- **공통 관찰**: 비벌소리의 지속시간이 짧을 경우(Θ = 0 s) 모델이 구분하기 어려워 AUC가 크게 감소한다. 따라서 라벨링 단계에서 최소 지속시간 임계값을 설정하는 것이 중요하다. 또한, 벌통마다 음향 환경이 크게 다르기 때문에 데이터 다양성을 확보하고, 교차‑벌통 검증을 통한 일반화 평가가 필수적이다.
7. **결론 및 향후 과제**
- 본 연구는 비벌소리와 벌소리를 구분하기 위한 최초의 공개 라벨링 데이터셋을 제공하고, SVM과 CNN 두 접근법을 비교함으로써 장시간 컨텍스트와 외부 소리 지속시간이 성능에 미치는 영향을 정량화했다.
- 현재 모델은 데이터 양이 제한적이고, 벌통 간 음향 차이가 크기 때문에 일반화가 부족하다. 향후 연구는 (1) 더 큰 규모의 라벨링 데이터 확보, (2) 멀티‑모달 센서(진동, 온도, 습도)와의 융합, (3) 트랜스퍼러닝·프리트레인된 음향 모델 활용, (4) 시계열 모델(RNN, Transformer) 도입 등을 통해 성능과 일반화를 동시에 개선할 필요가 있다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기