계통수 기반 비교 데이터의 계층적 자기상관 분석
초록
본 논문은 계통수(phylogenetic tree) 구조를 갖는 비교 데이터에서 선형 모델의 추정량과 정보 기준(BIC)의 대수적 거동을 연구한다. 브라운 운동(Brownian motion) 가정 하에 최적선형불편추정량(BLUE)이 거의 확실히 수렴하지만, 조절항(인터셉트)과 계통(라인지) 효과와 같은 일부 파라미터는 일관성이 없음을 보인다. 이를 보정하기 위해 ‘유효 표본 크기(effective sample size)’ 개념을 도입하고, BIC의 벌점 항을 log(1+ne) 형태로 수정한다. 또한, 조상 상태 추정에 있어 표본 수를 늘려도 정보량이 제한되므로, 트리 구조를 고려한 최적 샘플링 설계가 필요함을 제시한다.
상세 분석
이 연구는 비교 생물학·진화학에서 흔히 사용되는 계통수 기반 데이터의 통계적 특성을 엄밀히 규명한다. 먼저, 종 간의 공통 조상 관계가 브라운 운동으로 모델링된다는 가정 하에, 관측값 Y는 평균 μ와 공분산 σ²Vtree를 갖는 다변량 정규분포를 따른다. 여기서 Vtree의 원소 Vij는 두 종이 공유하는 조상까지의 시간(분기 길이)이다. 이러한 구조는 전통적인 i.i.d. 가정과는 달리, 관측치 간에 강한 상관관계를 부여한다.
선형 모델 Y = Xβ + ε (ε ~ N(0, σ²Vtree))에 대해, 설계행렬 X가 풀랭크일 때 BLUE인 β̂ = (XᵀV⁻¹X)⁻¹XᵀV⁻¹Y가 거의 확실히 수렴한다는 정리 1을 제시한다. 그러나 수렴값이 진정한 β와 일치하려면 해당 파라미터의 비대칭 분산이 0이어야 한다. 브라운 운동 트리에서는 인터셉트(조상 상태)와 특정 라인지 효과가 트리의 깊이에 따라 가중치가 크게 달라지므로, 이들의 추정량은 무작위 한계값으로 수렴하고 일관성을 상실한다. 즉, 표본 수 n이 무한히 커져도 β̂₀(인터셉트)는 실제 μ와 차이가 남는다.
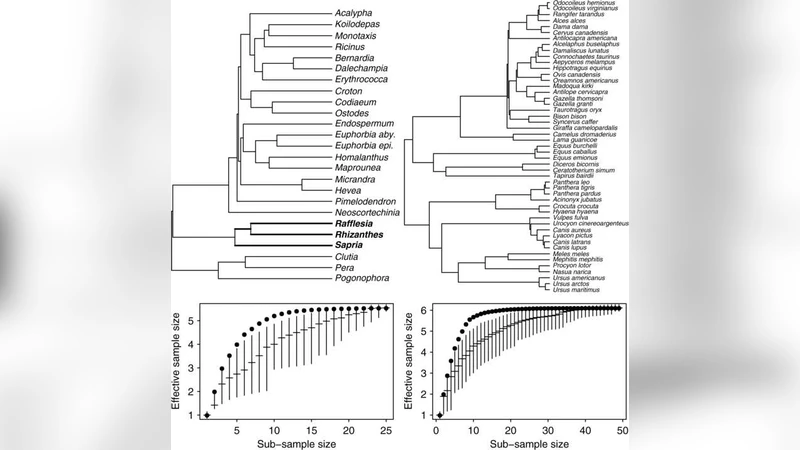
이러한 비일관성을 정량화하기 위해 ‘유효 표본 크기(ne)’를 정의한다. ne는 실제 표본 수 n에 비해 훨씬 작으며, 트리의 구조—특히 루트에서 가장 가까운 가지의 길이 t와 전체 깊이 T—에 의해 상한이 결정된다 (ne ≤ k·T/t, 여기서 k는 루트에서 뻗은 가지 수). 실험적으로는 25종 식물 데이터에서 ne≈5.5, 49종 포유류 데이터에서 ne≈6.1으로, n에 비해 4~8배 감소함을 확인한다.
BIC는 일반적으로 -2·log L + p·log n 형태로 모델 복잡도를 벌점한다. 그러나 비일관 파라미터에 대해 log n은 과도한 벌점이 되며, 실제 사후 확률을 잘 근사하지 못한다. 저자는 이를 보정하기 위해 인터셉트와 라인지 효과와 같은 파라미터에 대해 log(1+ne) 벌점을 적용한다. 이는 AIC와 유사한 형태이면서도 트리 의존성을 반영한다.
마지막으로, 표본 설계 측면에서 트리 구조를 활용한 ‘최적 샘플링’ 전략을 제안한다. 루트에 가까운 종(예: 화석 종, 초기 바이러스 샘플)을 포함시키면 인터셉트에 대한 가중치가 크게 증가해 ne를 최대화할 수 있다. 시뮬레이션에서는 전체 25종 중 15종만 선택해도 ne가 거의 최댓값에 도달함을 보여, 무작위 표본보다 현저히 효율적인 설계임을 입증한다.
요약하면, 계통수 기반 데이터는 전통적인 독립성 가정이 깨지는 특수한 상관구조를 가지며, 이는 추정량의 일관성, 모델 선택 기준, 그리고 표본 설계에 중대한 영향을 미친다. 본 논문의 이론적 결과와 실증적 검증은 이러한 특성을 정량화하고, 실무 연구자가 보다 신뢰성 있는 진화적 추론을 수행하도록 돕는다.
댓글 및 학술 토론
Loading comments...
의견 남기기