HiMA: 차세대 히스토리 기반 메모리 액세스 엔진으로 가속하는 DNC
초록
HiMA는 DNC의 복잡한 히스토리 기반 어텐션 연산을 지원하도록 설계된 타일형 메모리 액세스 엔진이다. 다중 모드 NoC와 서브매트릭스 파티셔닝, 두 단계 사용 정렬, 사용 스키밍·소프트맥스 근사 등으로 통신량과 연산량을 크게 줄이며, 분산형 DNC‑D 모델을 통해 거의 모든 메모리 연산을 로컬에서 수행한다. RTL 기반 40 nm 구현에서 기존 MANN 가속기 대비 최대 39배 속도, 164배 면적·61배 에너지 효율을 달성하고, Nvidia 3080Ti 대비 최대 2,646배 가속을 보인다.
상세 분석
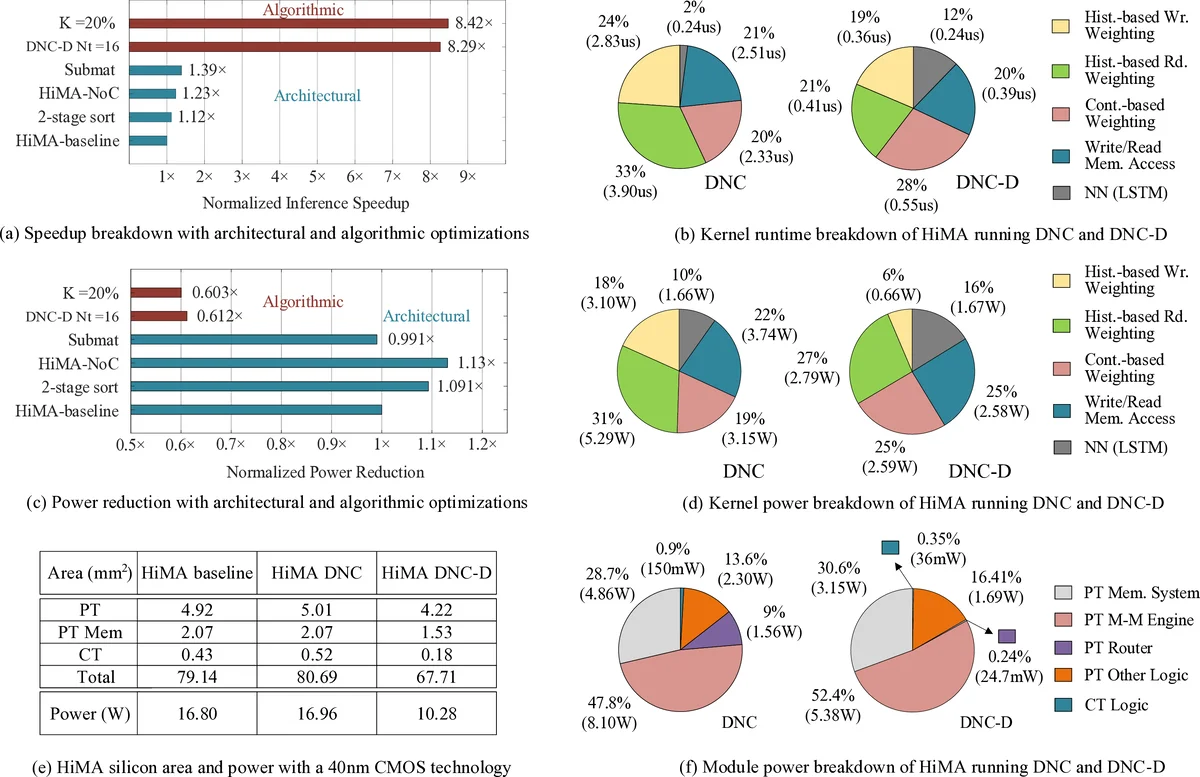
HiMA는 기존 MANN 가속기들이 갖추지 못한 히스토리 기반 메모리 접근을 효율적으로 처리하기 위해 세 가지 핵심 설계를 도입한다. 첫째, DNC 연산 흐름을 정밀히 분석해 트래픽 패턴을 도출하고, 이를 기반으로 다중 모드(Network‑on‑Chip, NoC)를 구현한다. 일반적인 패킷 전송 모드와 대용량 행렬 전송 모드를 동적으로 전환함으로써, 콘텐츠 기반 연산에서는 저지연 라우팅을, 히스토리 기반 연산에서는 대역폭을 최적화한다. 둘째, 메모리를 서브매트릭스 단위로 파티셔닝한다. 기존의 행/열 파티셔닝은 히스토리 기반 연산에서 발생하는 사용 벡터 정렬·정렬 후 사용량 합산에 비효율적인 데이터 이동을 초래했지만, 서브매트릭스 파티셔닝은 필요한 부분만 로컬 타일에 배치해 NoC 트래픽을 최소화한다. 셋째, DNC‑D라는 분산형 DNC 모델을 제안한다. 각 타일이 자체 메모리와 상태 변수(예: 사용 벡터, 링크 매트릭스)를 보유하고, 전역 출력은 가중합을 통해 합성한다. 이 구조는 메모리 접근을 로컬화해 병렬성을 극대화하고, 전역 동기화 비용을 크게 낮춘다.
연산 효율성을 높이기 위해 HiMA는 두 단계 사용 정렬(local‑global sort)과 두 가지 근사 기법을 적용한다. 로컬 단계에서는 각 타일에서 사용 벡터를 부분 정렬하고, 글로벌 단계에서 부분 결과를 합쳐 최종 정렬을 수행해 전체 복잡도를 O(N log N)에서 O(N log (N/T))로 감소시킨다. 사용 스키밍은 사용량이 낮은 메모리 슬롯을 사전에 제외해 불필요한 연산을 차단하고, 소프트맥스 근사는 지수 연산을 로그‑시그모이드 근사로 대체해 하드웨어 구현 비용을 크게 낮춘다.
RTL 설계와 40 nm 합성 결과, HiMA는 기존 최첨단 MANN 가속기인 MANNA 대비 평균 6.5배39배의 속도 향상을 보였으며, 면적 효율은 22.8배164배, 에너지 효율은 6.1배~61배 개선되었다. 특히 DNC‑D 모드에서는 메모리 규모가 커질수록 스케일링 효율이 급격히 상승한다. GPU와의 비교에서도 DNC 실행 시 최대 437배, DNC‑D 실행 시 2,646배의 추론 시간 단축을 기록했다. 이러한 결과는 히스토리 기반 어텐션 연산이 메모리·통신 병목에 크게 의존한다는 점을 확인하고, HiMA가 이를 효과적으로 해소함을 입증한다. 다만, 40 nm 공정 기반 구현이므로 최신 7 nm·5 nm 공정에서의 절대 성능은 더 높아질 가능성이 있으며, 타일 수와 NoC 토폴로지 설계가 메모리 크기에 따라 최적화 필요하다.
댓글 및 학술 토론
Loading comments...
의견 남기기